网络爬虫:
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
以上是网络爬虫的百度,下面开始介绍使用Python进行网络爬虫来获取数据。
用来获取新冠肺炎的实时数据。
使用的工具PyCharm
新建Python文件,命名为get_data
使用爬虫最常用的request模块
第一部分:
获取网页信息:
import requests
url = "https://voice.baidu.com/act/newpneumonia/newpneumonia"
response = requests.get(url)第二部分:
可以观察数据的特点:
数据包含在script标签里,使用xpath来获取数据。
导入一个模块from lxml import etree
生成一个html对象并且进行解析
可以得到一个类型为list的内容,使用第一项就可以得到全部内容
接下来首先获取component的内容,这时使用json模块,将字符串类型转变为字典(Python的数据结构)
为了获取国内的数据,需要在component中找到caseList
接下来上代码:
from lxml import etree
import json
# 生成HTML对象
html = etree.HTML(response.text)
result = html.xpath('//script[@type="application/json"]/text()')
result = result[0]
# json.load()方法可以将字符串转化为python数据类型
result = json.loads(result)
result_in = result['component'][0]['caseList'] 第三部分:
将国内的数据存储到excel表格中:
使用openyxl模块,import openpyxl
首先创建一个工作簿,在工作簿下创建一个工作表
接下来给工作表命名和给工作表赋予属性
代码如下:
import openpyxl
#创建工作簿
wb = openpyxl.Workbook()
#创建工作表
ws = wb.active
ws.title = "国内疫情"
ws.append(['省份', '累计确诊', '死亡', '治愈', '现有确诊', '累计确诊增量', '死亡增量', '治愈增量', '现有确诊增量'])
'''
area --> 大多为省份
city --> 城市
confirmed --> 累计
crued --> 值域
relativeTime -->
confirmedRelative --> 累计的增量
curedRelative --> 值域的增量
curConfirm --> 现有确镇
curConfirmRelative --> 现有确镇的增量
'''
for each in result_in:
temp_list = [each['area'], each['confirmed'], each['died'], each['crued'], each['curConfirm'],
each['confirmedRelative'], each['diedRelative'], each['curedRelative'],
each['curConfirmRelative']]
for i in range(len(temp_list)):
if temp_list[i] == '':
temp_list[i] = '0'
ws.append(temp_list)
wb.save('./data.xlsx')第四部分:
将国外数据存储到excel中:
在component的globalList中得到国外的数据
然后创建excel表格中的sheet即可,分别表示不同的大洲
代码如下:
data_out = result['component'][0]['globalList']
for each in data_out:
sheet_title = each['area']
# 创建一个新的工作表
ws_out = wb.create_sheet(sheet_title)
ws_out.append(['国家', '累计确诊', '死亡', '治愈', '现有确诊', '累计确诊增量'])
for country in each['subList']:
list_temp = [country['country'], country['confirmed'], country['died'], country['crued'],
country['curConfirm'], country['confirmedRelative']]
for i in range(len(list_temp)):
if list_temp[i] == '':
list_temp[i] = '0'
ws_out.append(list_temp)
wb.save('./data.xlsx')整体代码如下:
import requests
from lxml import etree
import json
import openpyxl
url = "https://voice.baidu.com/act/newpneumonia/newpneumonia"
response = requests.get(url)
#print(response.text)
# 生成HTML对象
html = etree.HTML(response.text)
result = html.xpath('//script[@type="application/json"]/text()')
result = result[0]
# json.load()方法可以将字符串转化为python数据类型
result = json.loads(result)
#创建工作簿
wb = openpyxl.Workbook()
#创建工作表
ws = wb.active
ws.title = "国内疫情"
ws.append(['省份', '累计确诊', '死亡', '治愈', '现有确诊', '累计确诊增量', '死亡增量', '治愈增量', '现有确诊增量'])
result_in = result['component'][0]['caseList']
data_out = result['component'][0]['globalList']
'''
area --> 大多为省份
city --> 城市
confirmed --> 累计
crued --> 值域
relativeTime -->
confirmedRelative --> 累计的增量
curedRelative --> 值域的增量
curConfirm --> 现有确镇
curConfirmRelative --> 现有确镇的增量
'''
for each in result_in:
temp_list = [each['area'], each['confirmed'], each['died'], each['crued'], each['curConfirm'],
each['confirmedRelative'], each['diedRelative'], each['curedRelative'],
each['curConfirmRelative']]
for i in range(len(temp_list)):
if temp_list[i] == '':
temp_list[i] = '0'
ws.append(temp_list)
# 获取国外疫情数据
for each in data_out:
sheet_title = each['area']
# 创建一个新的工作表
ws_out = wb.create_sheet(sheet_title)
ws_out.append(['国家', '累计确诊', '死亡', '治愈', '现有确诊', '累计确诊增量'])
for country in each['subList']:
list_temp = [country['country'], country['confirmed'], country['died'], country['crued'],
country['curConfirm'], country['confirmedRelative']]
for i in range(len(list_temp)):
if list_temp[i] == '':
list_temp[i] = '0'
ws_out.append(list_temp)
wb.save('./data.xlsx')结果如下:
国内: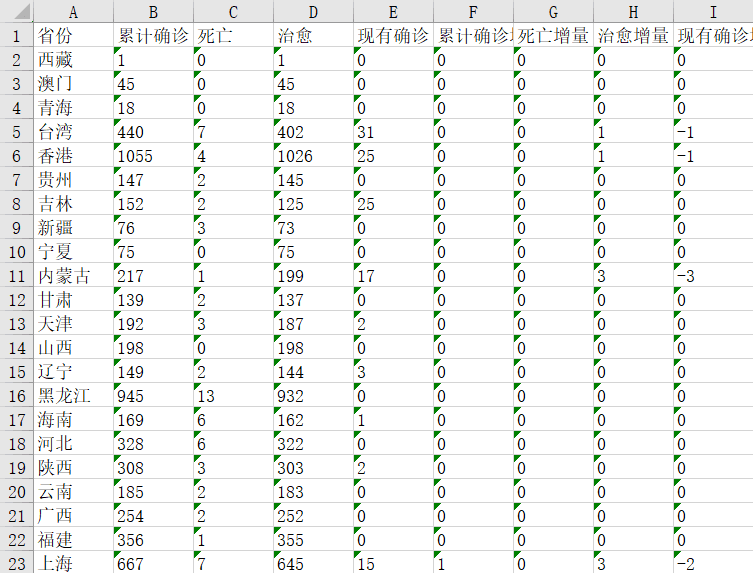
国外: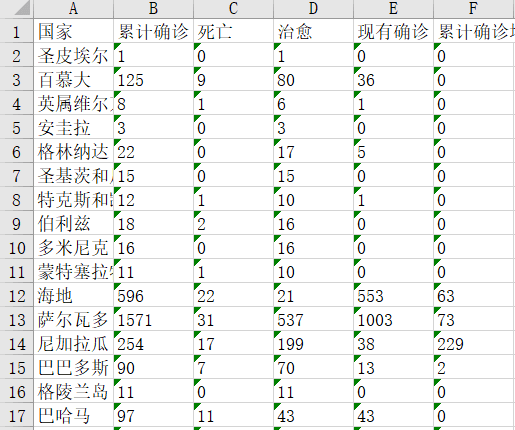
推荐 :
- 020 持续更新,精品小圈子每日都有新内容,干货浓度极高。
- 结实人脉、讨论技术 你想要的这里都有!
- 抢先入群,跑赢同龄人!(入群无需任何费用)
- 点击此处,与Python开发大牛一起交流学习
- 群号:858157650
申请即送:
- Python软件安装包,Python实战教程
- 资料免费领取,包括 Python基础学习、进阶学习、爬虫、人工智能、自动化运维、自动化测试等