CouchDB及Append-only B+树
前言
今天晚上在写分布式系统上下层概念抽象-(2)的时候,遇到了一致性相关的内容,简单搜索了一些CAP的文章,就无意中看到了博文CouchDB Eventually Consistency。它是一个分布式的key-value数据库,感觉里面的设计还挺有意思的,很多ideas虽然知道,但是并没有和实际的系统挂钩,现在把它的一些设计思路写一写,主为备忘,权当一乐。
分布式系统
分布式系统需要处理的最典型情况就是网络分区故障,相比于很多系统将强一致性列为第一大需要,CouchDB采用了最终一致性的范畴,以可用性为第一准则。CouchDB提供了一种有效的方式来达到系统高可用。
CAP
- Consistency:所有节点在任何时刻看到都是相同的数据
- Availability:对于外部的请求,系统一定能够响应。
- Partition Tolerance:网络分区故障或者节点系统依然可以对外提供服务

然而如上图所示,最多两个条件能得到同时满足。CouchDB在满足PA的情况下,达到最终一致性。
当在分布式系统增加新server的时候,我们必须考虑如何划分数据:所有的节点是存储一样的数据?每个节点只存储部分数据?单点写,多点读?CouchDB采用的是所有的节点存储一样的数据方案(完全的副本)。那新的问题来了,如何保证server之间的同步?如何能够确保写操作能够立刻反映到其他的节点上?毫无疑问,为了保证所有的节点都能看到一致的数据库状态,某一个节点必须等待其他节点达成一致性协议,写操作才能开始写入。在这种情况下,一致性比可用性重要。然而,也有一些情况可用性比一致性重要。
Each node in a system should be able to make decisions purely based on local state. If you need to do something under high load with failures occurring and you need to reach agreement, you’re lost. If you’re concerned about scalability, any algorithm that forces you to run agreement will eventually become your bottleneck. Take that as a given.
—Werner Vogels, Amazon CTO and Vice President
如果可用性更重要,那么我们需要使得客户端不需要等待其他节点达成协议,就可将数据写入到server中。只要数据库自身能够协调解决冲突,那就达成了某种“最终一致性”,从而获得高可用性,这种服务保证在很多现实应用中都是一个很好的tradeoff。
Local Consistency
核心数据结构
在了解它的分布式运作原理之前,先看看单个CouchDB节点如何工作的?CouchDB的核心是一个B+树存储引擎,它提供log级别的插入,删除,查找性能。CouchDB将B树用在了内部的数据,文档,以及视图中。另外,CouchDB还支持range query(范围查询)。

CouchDB使用了Append-only的B+树(见下文)。写操作外部并发,但是到达底层的B+树核心,会顺序执行,每个写操作可看做一次完整的事务(追加新的节点,更新root node和meta block);读操作也外部并发,内部也并发,并且在写的过程中不会影响外部的读,外部可能读不到最新的数据。
无锁
当修改关系型数据库某一个table的一行的时候,DB需要首先对该行上锁,以确保不会出现同时写入以及在update的时候不会被读,这阻碍了操作的并发,从而影响吞吐。CouchDB使用了无锁的Multi-Version Concurrency Control(MVCC)协议来应对并发访问。

简单说来就是,CouchDB维护了每个记录的多个版本,如果对数据进行了修改,那么会增加它的版本号。如上图所示,在Locking状态下,写操作会对记录上锁,只有在commit之后,才能发起请求;在CouchDB中,读和写可以任意交错,在写入“new version”之前,读请求读的是老的数据,在写入“new versin”之后,读取的是新的数据。
CoundDB的数据是版本化的,这特别类似于现在的版本控制工具(git,svn等)。如果你需要更新某个文档,那么就创建这个文档的新版本,然后更新它,这样会拥有同一个文档的两个版本:旧版本和新版本。举一个例子,当有一个请求在请求某个文档的时候,写请求到来了,当读请求正在被处理的时候,写请求也可以并发执行,因为这个写请求包含了新版本的完整数据,CouchDB只简单将这个新版本加入到数据库中即可,完全不需要先等待读请求的完成。当再有读到来的时候,CouchDB会负责将这个读指向最新的版本。但是在这之前的那些在排队中的读请求,读取的依然是旧版本。
分布式一致性
考虑完了单机的操作,现在看看分布式如何工作的。简单说来,如何一个client对Server A发起写入操作,如何确保这与Server B,C,D一致。
增量副本
CouchDB操作基于单个文档进行,这也意味着,两个节点不需要大量频繁的同步操作。CouchDB使用了增量副本的机制,定期地将文档的改变部分在节点之间同步。我们会发现,每个server的Database的状态是自给自足的,没有全局状态的共享,是一种share nothing的机制,这意味着不存在分布式系统的单点问题。如果你想要扩容CouchDB,直接加一个新的server。其实这一段说是这样说,扩容的节点越多,意味着需要更新的越多,读操作吞吐能够线性增长,写操作增长并非线性。
你可能会问,如何同一个文档在不同的server内进行了不同的更新,那该如何做呢?CouchDB的副本系统实现了冲突检测和冲突解决的策略,当发现同一个文档在两个db中被修改后,此文档被标记为conflic(是不是看着像版本控制系统?)。在Replication的时候,系统会评测哪个成为winner,成为winner的被作为最新版本,而loser的版本并不会被系统丢失,它会被当作上一个版本。如果需要,你可以merge,或者回滚等操作到达你想要的状态。
典型案例
台式机备份
假定你有一个需求,要将台式机上的歌曲的playlist保存到CouchDB中,进行备份。
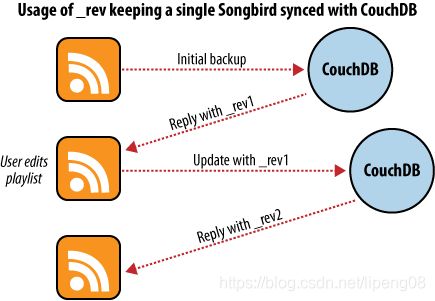
如上图所示,第一次Initial backup阶段,CouchDB会存储你的数据,并返回当前数据的版本号。当下次需要更新数据的时候,必须携带上一次的版本号(如rev1),然后CouchDB更新后,返回新的版本rev2。这个操作类似于zookeeper的更新策略(扩展阅读Apache Zookeeper),采用的是幂等性的语义,这种思路还特别类似于compare-and-set的无锁原子操作。强制client携带当前的正确版本是CouchDB的并发的核心。
恢复到新的笔记本

假设我们还有一个笔记本,想和台式机保持同步,我们第一步是使用restore命令来恢复备份。
如上图所示,当前笔记本和台式机都是rev1。然后过一段时间,我们通过笔记本上传了新的更新,当前版本号变为rev2,但是我们忘记了将更改同步到台式机上。随后,我们在台式机上修改了(基于rev1的修改)数据,希望将其同步到CouchDB上,但是CouchDB发现了冲突(当前系统的版本已经是rev2)。用户解决冲突的方法很简单,下载最新版本,与本地合并,然后上传即可。
多版本保存

上图是一个多版本的例子,分别两个不同的客户端,对两个不同的server,修改了不同的内容,在进行同步的时候,发现不一致,两个版本都会被保存下来,交给用户解决冲突。
Append-only B+树
这是我第一次看到Append-only的B树。上面的CouchDB中关于树的介绍中,说它使用的B+树是改造的B+树,增加了MVCC多版本控制以及是Append-only的。MVCC前面也说过很多,而Append-only是啥?Append-only形如其名,只支持追加操作,也就是说这棵树的任何操作都会转换为追加操作,可以预见的是这种B+树会耗费更多的存储空间,但是却可以更好的利用磁盘顺序写,达到很高的性能。
关于B树和B+树,虽然每次都看,但是总忘记其差异。现在再简单过一遍其特性,B树和B+树是算是log查找级别的key-value结构:B树的分支节点与叶子节点地位一样,都会存储key和相应的data,这样的话B树中如果在某个分支找到了key,那么可直接返回其data;与之不同的是,B+树的分支只存储key,而交给叶子节点存储完整的key和data,这也就意味着所有的查找操作最终都会落入到叶子中(额外副作用是分支节点的key和叶子节点的key有重叠,节点数变多了),这带来一个好处是就是磁盘的一个block(例如4KB)可以存储更多的分支节点。我们知道磁盘随机读耗时,而顺序读效率高,文件系统中的底层读一般都是一次读一个block(例如4KB),也就是说B+树能读取更多的分支节点,从而减少磁盘读取。另外,在文件系统中,分支节点很容易被系统cache住,从而使得一次文件查找等于多次内存查找(分支查找)和一次磁盘查找(叶子节点);不少B+树的实现还在叶子节点加上串联指针,来优化顺序访问,简言之B+树更适用于树状查找的文件系统。

物理存储表示
如上图所示,三层B+树,root和branch都是分支节点,只存储key,叶子节点存储完整的data。
上述的这些节点在数据库文件中被顺序存储下来,增加,更新,删除只会影响这个数据库文件的offset。也就是说,所有的操作都会转换为追加操作。这个数据库文件的最后位置有一个meta block,用于定位root node,以及存储hash校验,统计值等。
如上图所示,它是B+树对应的database file的物理存储排布,文件末尾是meta data的block,存储了指向root的指针,树中的节点都存储了相应的指针,指向对应的节点。注意,这个指针不同于内存中的指针,它可认为是使用额外的存储空间存储着其他节点的offset和length。

节点更新
始终记住更新操作最终都会转换为B+树的物理存储的append操作,文件不支持内部的修改,只支持append。
以更新leaf 8为例,不能进行原地更新,需要新加入额外的节点(假如是leaf 12),并将数据copoy过去。这样的话,leaf8的所有父亲也需要进行同步的更新,与之同理,所有的父亲的指针无法原地修改,也需要新加入节点,并将数据copy一份。也就是说,会形成如下的B+树图:


那形成的物理存储结构是如何的呢?如上图所示,相比于过去的存储结构,我们追加了4个节点,分别是meta 14,以及新的branch 11,leaf 12和root 13这3个节点。这不可避免的增加了存储开销,因为旧的数据依然存在。再带来一个额外的好处就是,旧的链路依然存在,依然可以正常的访问,例如过去有个人持有了meta 10(过去的root的指针),那么过去的整棵树都完整的存在。
不知道你是否想到了snapshot(快照)?上面的结构意味着创建一个snapshot(甚至于很多很多个)是极端的容易,代价是极端的小,直接存储当前文件的偏移量即可,恢复快照也非常容易,例如想恢复到root 9,直接将文件进行截取到meta 10即可。再提一遍,存储开销会增大,毕竟更新一个字节也需要增加一个完全copy的节点。
从这里我想到了一种MVCC的实现,我们可以对上面的leaf节点再增加链路,用于指向它的上一个version,然后上一个version指向更靠前的version,另外新的version不需要存储完整的数据,只需要存储与历史version的改变的部分(diff)即可。实现MVCC只需要上面的物理存储结构进行小部分的改变,例如leaf 8更新了一个字节,那么追加一个新节点leaf 12,它只存储改变的位置,以及改变的内容(开销很低),然后leaf 12有一个指针指向leaf 8,其他节点不变。这样当用户要访问最新的版本,那么使用meta 14,会找到leaf 12,再使用其指针,可以找到它的上一个版本leaf 8,如果它还有上上一个版本,还可以继续向上回溯。这样会有一个问题,如果有几百个版本,那么欲访问最新数据,需要向前回溯数百次,对于这种情况我们可以在多个版本diff之后,做一下merge操作,存储mere之后的数据,就不需要不断向前回溯了。
- [1] CouchDB Eventually Consistency
- {2] how the append-only btree works
- [3] 知乎B和B+树的讨论