python爬虫(1):从入门到放弃,重新入门
背景
上学期学python学到一半迷上了爬虫强大的功能,从urllib开始入门,学习request、正则表达式、Xpath,中间用urllib爬了k站的一些图片。urllib请求和下载速度太慢了,数据处理也比较麻烦,所以去学速度更快,更强大的的scrapy。
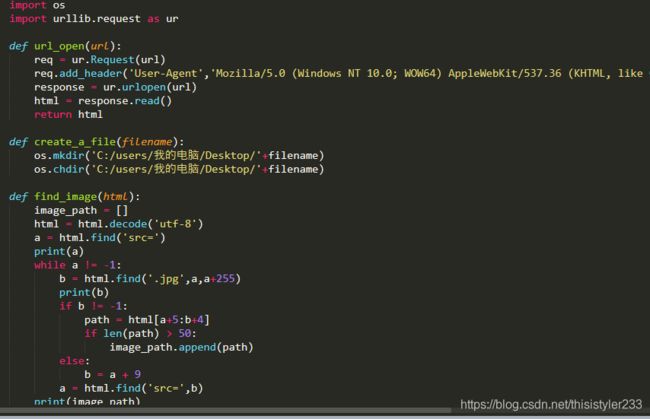
scrapy真的好难啊(哭),至今回想起那段噩梦还后怕,爬k站时爬虫直接被禁,因为是代码问题检查了一遍又一遍,用了好多隐藏的方法都没用,当时就很怀疑人生,差点去学了selenium,最后还是放弃了。
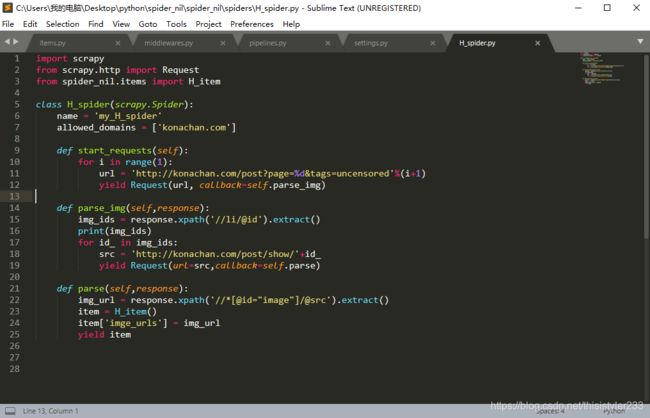
今天在b站上发现个不错的爬虫视频教程,心动之下又开始学爬虫了哈哈哈,立个flag,这次要一次过!
正文
看了5天视频,其中也跟着视频做了小爬虫,比如贴吧爬虫,有道翻译爬虫,才学了几天就能做出这些很有意思的东西,开心。
之后我写了两个自己喜欢的爬虫程序
- b站著名up主老番茄的所有的视频信息,用播放次数排出top10的视频
- 分类爬取网易云音乐所有歌单的信息
老番茄爬虫
老番茄是我最喜欢的b站up主,爬一爬他的视频,发现了不少好玩的东西。
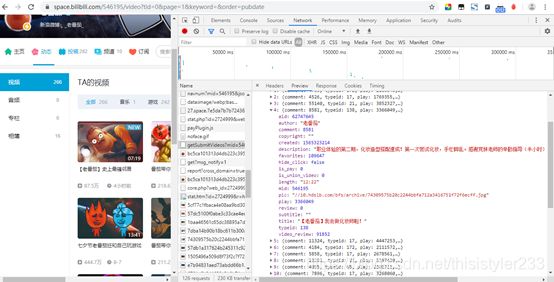
先开始去踩点,或者说抓包,用chrome的审查工具找到response中有我们想要的页面内容的network中的内容。如图,我发现response是json的字典型字符串(庆幸),直接用json.loads转化为python的字典,就可以通过键和值提取了。
寻找数据的方法:
- 一般来说数据就在刷新网页时的前几个响应中 ,从network中一个一个往下找(忽略jpg,css,png,js,gif类型)
- 用search寻找页面上我们想要的数据中的数字和英文(汉字可能被编码)
写代码,用面向对象的编程方法,定义一个QieJiang(茄酱)类,这里的parse_url方法是自己写的,作用和request.get()一样。
#第一行向老番茄致敬!
import requests
import re
from parse_url import parse_url
import json
class Qiejiang_spider():
def __init__(self):
self.temp_url = "https://space.bilibili.com/ajax/member/getSubmitVideos?mid=546195&pagesize=30&tid=0&page={}&keyword=&order=pubdate"
def get_useful_content(self,html_str):
video_info = {}
html_list = json.loads(html_str)
for i in html_list['data']["vlist"]:
video_info[i['title']] = i['play']
return video_info
def print_top10(self,video_info):
sorted_info = sorted(video_info.items(),key = lambda item:item[1],reverse = True)
#这里懒得发送请求了,直接找到数据手动打印了
print('截至2019/8/21,12:08,老番茄共265个视频,其中音乐区1个,游戏区241个,鬼畜区1个,生活区21个,影视区1个')
for i in range(10):
print('排名第{}的视频是 {},播放量{}'.format(i+1,sorted_info[i][0],sorted_info[i][1]))
def run(self):
# 1.获取url_list
url_list = [self.temp_url.format(i) for i in range(1,10)]
print("获取url地址成功")
video_info = {}
# 2.请求,获取响应
for url in url_list:
print(url)
html_str = parse_url(url)
# 3.从响应中获取数据
video_info_temp = self.get_useful_content(html_str)
# 4.更新字典
video_info.update(video_info_temp)
# 5.显示播放数量最多的前十个视频
self.print_top10(video_info)
if __name__ == '__main__':
qiejiang_spider = Qiejiang_spider()
qiejiang_spider.run()
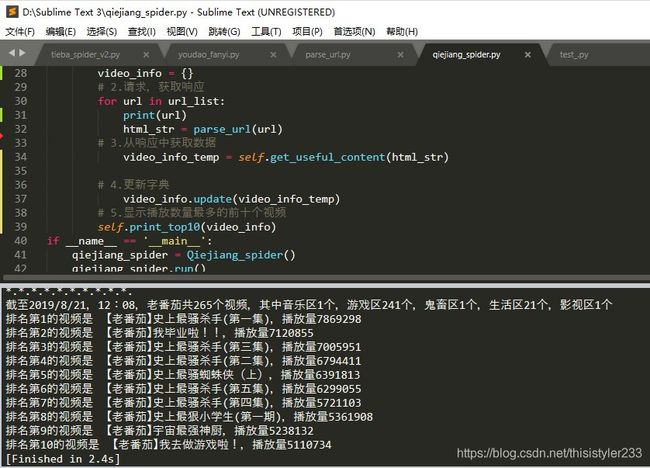
结果如下,数据没有保存,只是进行了排序就输出了。
网易云音乐歌单爬虫
这个是视频最后的一个作业之一,我觉得挺有意思,也有点难度,我就做了。
写爬虫时应注意:
- 尽量减少请求次数,表层页上有需要的信息就不要进入详情页抓取
- 需要的response中有json的内容就不要去用html类型的response
- 不变的参数不要用请求获取,可以用代码自动生成添加
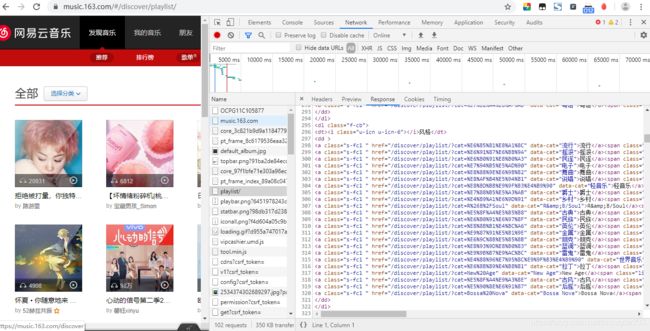
如上图,在playlist中找到了所有的分类和对应的url地址(残缺),我先获取每个大类的名称建一个文件夹,文件夹内放所有的小分类的每一页的内容。response是html形式的,我们可以用xpath来提取对应的数据。
代码如下:
from parse_url import parse_url
from lxml import etree
import os
import json
def mkdir(path):
folder = os.path.exists(path)
if not folder:
os.mkdir(path)
return 1
else:
print('该目录已经存在了')
return 0
class Netease_spider():
def __init__(self):
self.start_url = "https://music.163.com/discover/playlist"
def save_content(self,page_data,file_path,num_pages):
with open(file_path+'/第'+str(num_pages)+'页.txt',"w",encoding='utf-8') as f:
for i in page_data:
f.write(json.dumps(i,ensure_ascii=False))
f.write('\n')
f.write('\n')
def run(self):
# 1.准备原始的url地址
# 2.发送请求,获取响应
html_str = parse_url(self.start_url)
print("一级请求")
# 3.提取各主题的url,构成url列表
html = etree.HTML(html_str)
cat_list_box = html.xpath("//dl[@class='f-cb']")
for each in cat_list_box: #每一个大主题
column_name = each.xpath("./dt/text()")[0]
print(column_name)
mkdir("./"+column_name)
title = each.xpath("./dd//a")
for each in title: #获取每个小主题url地址
title_name = each.xpath("./text()")[0]
if title_name == 'R&B/Soul':
title_name = 'R&B Soul'
print(title_name)
#print(each)
file_path = "./"+column_name+"/"+title_name
if mkdir(file_path):
det_url_temp = "https://music.163.com"+each.xpath("./@href")[0]+'&limit=35&offset={}'
#print(det_url_temp)
det_urls = [det_url_temp.format(i*35) for i in range(38)]
print("进入每一页中")
for det_url in det_urls: #每个小主题的每一页
print(det_url)
det_html_str = parse_url(det_url)
print("二级请求,换页")
#print(det_html_str)
det_html = etree.HTML(det_html_str)
music_list = det_html.xpath("//div[@class='u-cover u-cover-1']")
num_pages = det_urls.index(det_url) + 1
page_data = []
#3.1 遍历,发出每一页的请求,获取每一页的信息
for each in music_list:# 每一页的各个歌单
#print('*'*100)
#print(each)
#print('*' * 100)
music = {}
music['title'] = each.xpath("./a/@title")[0]
music['n_p'] = each.xpath("//span[@class='nb']/text()")[0]
music['music_list_url'] = "https://music.163.com"+each.xpath("./a[@class='msk']/@href")[0]
music['pic_url'] = each.xpath("./img/@src")[0].replace('param=140y140','')
#3.2 加入列表,保存列表
page_data.append(music)
#print(page_data)
self.save_content(page_data,file_path,num_pages)
print('保存成功')
if __name__ == '__main__':
netease_spider = Netease_spider()
netease_spider.run()
跑了十几分钟,运行结果如下。
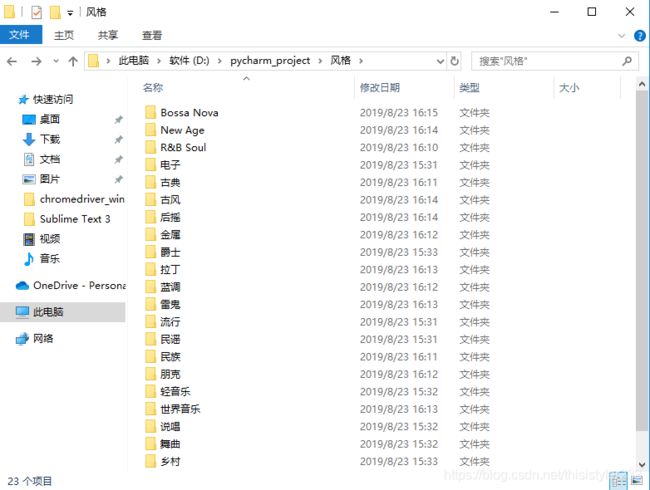

这样的结果还算满意,而且还有点出乎意料:全程只用了一个user-agent,没有使用代理等反反爬虫的手段,很轻松地爬到了数据。
总结
- 爬虫功能太简单了,单线程爬虫太慢,应该用多线程分布式爬虫;代码写得页很混乱,很多内容应该写成一个方法,让主代码看起来更有逻辑。
- 在寻找数据时要用到很多前端的知识,缺乏。有机会去学学。
- 毫无目的性地爬到一丢没用的数据,不会pandas处理,也不会可视化,下一步该学学数据科学。
- 数据保存在txt文件里,因为不会用数据库保存数据,这样很不方便。
- 写代码的效率还是太低,多练练。
- 学习爬虫的selenium模拟登陆。