数据分析————numpy和pandas
文章目录
- numpy和pandas
- numpy的基本操作
- 创建数组: a, b, c创建的数组相同, 任选一种;
- 查看numpy创建的数组类型
- 查看数组存储的数据类型, 常见的数据类型还有哪些?
- 制定创建的数组的数据类型
- 修改数组的数据类型
- 修改浮点数的小数点位数
- 数组的运算和索引切片
- 转置
- 索引和切片
- 数组中数值的修改
- 花式索引
- 形状修改
- 数组的拼接与分割
- 拼接
- 分割
- 数组元素的添加与删除
- numpy的统计函数
- pandas
- 创建Series数据类型
- Series 基本操作
- Series运算实例
- where方法
- DataFrame数据
- 创建DataFrame数据
- DataFrame基础属性和整体情况查询
- 文件读取和写入
- groupby功能
numpy和pandas
numpy的基本操作
创建数组: a, b, c创建的数组相同, 任选一种;
a = np.array([1, 2, 3, 4, 5])
b = np.array(range(1, 6))
c = np.arange(1, 6)
查看numpy创建的数组类型
print(type(a))
print(type(b))
print(type(c))
查看数组存储的数据类型, 常见的数据类型还有哪些?
print(a.dtype) # 为什么是int64? 因为硬件架构是64位;
制定创建的数组的数据类型
d = np.array([1.9, 0, 1.3, 0], dtype=float)
print(d, d.dtype)
修改数组的数据类型
e = d.astype('int64') # 里面可以是数据类型, 也可以是数据代码;int64---i1
print(e, e.dtype)
修改浮点数的小数点位数
# 随机创建一个三行四列的数组;
f = np.random.random((3, 4))
print(f)
# 修改浮点书的小数位数为3位
g = np.round(f, 3)
print(g)
数组的运算和索引切片
转置
import numpy as np
data = np.random.random((3, 4))
# 转换数据结构 # 2,6
data = data.reshape((2, 6))
print(data)
print("转置: ", data.T)
print("转置: ", data.transpose())
print("转置: ", data.swapaxes(1, 0))
索引和切片
import numpy as np
a = np.arange(12).reshape((3, 4))
print(a)
# *****************取单行或者单列*********************
# 取第2行;
print(a[1])
# 取第3列;
print(a[:, 2])
# 获取第2行3列的数据
print(a[1, 2])
# *****************取连续行或者列*********************
# 取第2行和第3行;
print(a[1:3])
# 取第3列和第4列
print(a[:, 2:4])
# 行: 1和2 列: 2
print(a[0:2, 1:2])
# *****************取不连续的行或者列*********************
# 行: 1和3 列: all 获取第一行和第三行的所有元素
print(a[[0, 2], :])
# 行: all 列: 1, 4
print(a[:, [0, 3]])
# 行: 1 , 3 列: 1 4 获取第一行第一列的元素, 和第三行第4列的元素
print("*"*10)
print(a[[0, 2], [0, 3]])
数组中数值的修改
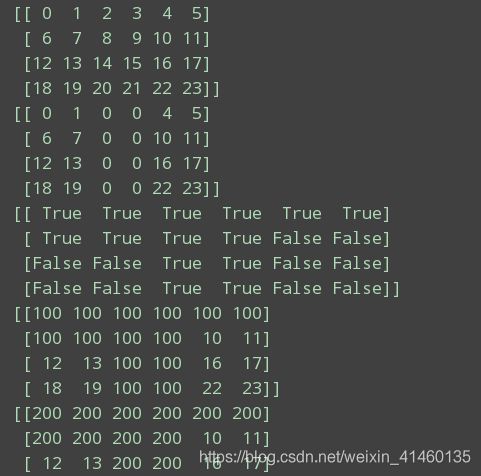
import numpy as np
# 执行行和指定列的修改
t = np.arange(24).reshape((4, 6))
print(t)
#行: all, 列: 3,4
t[:, 2:4] = 0
print(t)
# 布尔索引
print(t < 10)
#
t[t < 10] = 100
print(t)
t[t > 20] = 200
print(t)
# numpy的三元运算符 t<100?0:10
t1 = np.where(t < 100, 0, 10)
print(t)
print(t1)

花式索引
花式索引指的是利用整数数组进行索引。
花式索引根据索引数组的值作为目标数组的某个轴的下标来取值。对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素;
如果目标是二维数组,那么就是对应下标的行。
花式索引跟切片不一样,它总是将数据复制到新数组中。
import numpy as np
# 传入顺序索引数组
x = np.arange(32).reshape((8, 4))
print(x)
print(x[[4, 2, 1, 7]])
# 传入倒序索引数组
x=np.arange(32).reshape((8,4))
print (x[[-4,-2,-1,-7]])
# 传入多个索引数组(要使用np.ix_)
"""
原理:np.ix_函数就是输入两个数组,产生笛卡尔积的映射关系
将数组[1,5,7,2]和数组[0,3,1,2]产生笛卡尔积,就是得到
(1,0),(1,3),(1,1),(1,2);(5,0),(5,3),(5,1),(5,2);(7,0),(7,3),(7,1),(7,2);(2,0),(2,3),(2,1),(2,2);
"""
x=np.arange(32).reshape((8,4))
print(x)
print (x[np.ix_([1,5,7,2],[0,3,1,2])])
形状修改
reshape 不改变数据的条件下修改形状
numpy.reshape(arr, newshape, order='C')
order:'C' -- 按行,'F' -- 按列,'A' -- 原顺序,'k' -- 元素在内存中的出现顺序。
flat 数组元素迭代器
flatten 返回一份数组拷贝,对拷贝所做的修改不会影响原始数组
ravel 返回展开数组
数组的拼接与分割
拼接
concatenate 连接沿现有轴的数组序列
stack 沿着新的轴加入一系列数组。
hstack 水平堆叠序列中的数组(列方向)
vstack 竖直堆叠序列中的数组(行方向)
分割
split 将一个数组分割为多个子数组
numpy.split(ary, indices_or_sections, axis)
hsplit 将一个数组水平分割为多个子数组(按列)
vsplit 将一个数组垂直分割为多个子数组(按行)
数组元素的添加与删除
resize 返回指定形状的新数组
append 将值添加到数组末尾
insert 沿指定轴将值插入到指定下标之前
delete 删掉某个轴的子数组,并返回删除后的新数组
unique 查找数组内的唯一元素
arr:输入数组,如果不是一维数组则会展开
return_index:如果为true,返回新列表元素在旧列表中的位置(下标),并以列表形式储
return_counts:如果为true,返回去重数组中的元素在原数组中的出现次数
numpy的统计函数
numpy.amin()
用于计算数组中的元素沿指定轴的最小值。
numpy.amax()
用于计算数组中的元素沿指定轴的最大值。
numpy.ptp()
函数计算数组中元素最大值与最小值的差(最大值 - 最小值)。
numpy.percentile()
百分位数是统计中使用的度量,表示小于这个值的观察值的百分比。
numpy.median()
函数用于计算数组 a 中元素的中位数(中值)
numpy.mean()
函数返回数组中元素的算术平均值。 如果提供了轴,则沿其计算。
numpy.average()
函数根据在另一个数组中给出的各自的权重计算数组中元素的加权平均值。 average()
np.std()
标准差是一组数据平均值分散程度的一种度量。
标准差公式如下:std = sqrt(mean((x - x.mean())**2))
np.var()
统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数,
即 mean((x - x.mean())** 2)。
标准差是方差的平方根。
pandas
创建Series数据类型
Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
利器之一:Series
类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。
利器之二:DataFrame
是Pandas中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
常见的数据类型:
- 一维: Series
- 二维: DataFrame
- 三维: Panel …
- 四维: Panel4D …
- N维: PanelND …
Series是Pandas中的一维数据结构,类似于Python中的列表和Numpy中的Ndarray,不同之处在于:Series是一维的,能存储不同类型的数据,有一组索引与元素对应。
Series 基本操作
编号 属性或方法 描述
1 axes 返回行轴标签列表。
2 dtype 返回对象的数据类型(dtype)。
3 empty 如果系列为空,则返回True。
4 ndim 返回底层数据的维数,默认定义:1。
5 size 返回基础数据中的元素数。
6 values 将系列作为ndarray返回。
7 head() 返回前n行。
8 tail() 返回最后n行。
Series运算实例
import pandas as pd
import numpy as np
import string
s1 = pd.Series(np.arange(5), index=list(string.ascii_lowercase[:5])) # s1.index=[a, b, c, d, e] s1.value=[0 1 2 3 4]
s2 = pd.Series(np.arange(2, 8), index=list(string.ascii_lowercase[2:8])) # s2.index = [c,d,e,f]
print(s1)
print(s2)
# *****************按照对应的索引进行计算, 如果索引不同,则填充为Nan;
# 加法, 缺失值+ 真实值===缺失值
print(s1 + s2)
print(s1.add(s2))
# -
print(s1 - s2)
print(s1.sub(s2))
# *
print(s1 * s2)
print(s1.mul(s2))
# /
print(s1 / s2)
print(s1.div(s2))
# 求中位数
print(s1)
print(s1.median())
# 求和
print(s1.sum())
# max
print(s1.max())
# min
print(s1.min())
where方法
# &**********series中的where方法运行结果和numpy中完全不同;
s1 = pd.Series(np.arange(5), index=list(string.ascii_lowercase[:5]))
# print(s1.where(s1 > 3))
# 对象中不大于3的元素赋值为10;
print(s1.where(s1 > 3, 10))
# 对象中大于3的元素赋值为10;
print(s1.mask(s1 > 3, 10))
DataFrame数据
Series只有行索引,而DataFrame对象既有行索引,也有列索引
行索引,表明不同行,横向索引,叫index,
列索引,表明不同列,纵向索引,叫columns,
创建DataFrame数据
方法1: 通过列表创建
li = [
[1, 2, 3, 4],
[2, 3, 4, 5]
]
# DataFRame对象里面包含两个索引, 行索引(0轴, axis=0), 列索引(1轴, axis=1)
d1 = pd.DataFrame(data=li, index=['A', 'B'], columns=['views', 'loves', 'comments', 'tranfers'])
方法2: 通过numpy对象创建
narr = np.arange(8).reshape(2, 4)
# DataFRame对象里面包含两个索引, 行索引(0轴, axis=0), 列索引(1轴, axis=1)
d2 = pd.DataFrame(data=narr, index=['A', 'B'], columns=['views', 'loves', 'comments', 'tranfers'])
方法三: 通过字典的方式创建
dict = {
'views': [1, 2, ],
'loves': [2, 3, ],
'comments': [3, 4, ]
}
d3 = pd.DataFrame(data=dict, index=['粉条', "粉丝"])
DataFrame基础属性和整体情况查询
a)基础属性
df.shape #行数、列数
df.dtype #列数据类型
df.ndim #数据维度
df.index #行索引
df.columns #列索引
df.values #对象值,二维ndarray数组
b)整体情况查询
df.head(3) #显示头部几行,默认5行
df.tail(3) #显示末尾几行,默认5行
df.info() #相关信息概览:行数、列数、索引、列非空值个数、列类型、内存占用
df.describe() #快速综合统计结果: 计数、均值、标准差、最大值、四分位数、最小值等
文件读取和写入
csv文件的写入
df.to_csv('doc/csvFile.csv', index=False) # index=False不存储行索引
csv文件的读取
df2 = pd.read_csv('doc/csvFile.csv')
excel文件的写入
df.to_excel("/tmp/excelFile.xlsx", sheet_name="省份统计")
groupby功能
pandas提供了一个灵活高效的groupby功能,
1). 它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作。
2). 根据一个或多个键(可以是函数、数组或DataFrame列>名)拆分pandas对象。
3). 计算分组摘要统计,如计数、平均值、标准差,或用户自定义函数。