FLASK学习系列二-工厂函数和数据库连接
flask的安装请参见这个
项目的布局
整个教程都是在flask_tutorial这个目录下进行的。
依照系列一中的内容,先创建一个简单的文件hello.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello():
return 'Hello, World!'
但是随着项目的增大,不可能将所有的代码放在一个文件中。所以需要根据不同代码文件的功能将其分为不同的模块,在这里项目将会被分为这样的几个模块:
- flaskr:包含应用代码和文件
- tests:测试模块
- venv:flask和其他依赖所安装地方(虚拟环境)
- 告诉python如何安装你的项目的安装指导
- 版本控制工具
项目的整体布局:
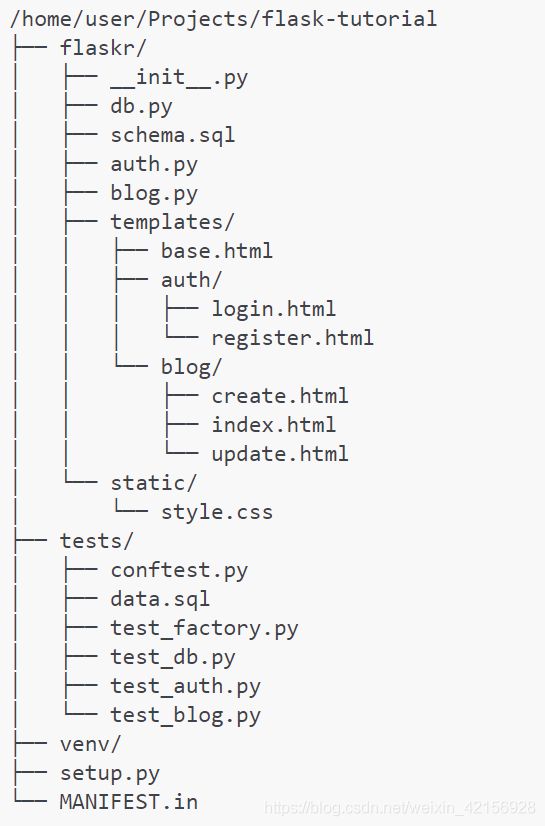
应用安装
flask的应用实际上是一个flask类的实例,关于这个应用的任何东西,包括配置文件和url,都将会在这个类里面注册。
创建一个flask应用最为直接的方法就是创建一个flask全局实例,但是随着项目的增大这种方法会带来很多的麻烦。
这里我们并不会创建一个flask全局的实例,而是要在一个函数中创建。这个函数便是应用工厂函数,一切的配置,注册,以及应用所需要的设置都会包含在这个文件中,最后这个应用将会被返回。
应用工厂函数
接下来我们将创建应用工厂函数,这个函数将有两个功能,第一它会包含应用工厂;第二它会告诉pythonflaskr目录应该被视为一个包。
flaskr/init.py
import os
from flask import Flask
def create_app(test_config=None):
# create and configure the app
app = Flask(__name__, instance_relative_config=True)
app.config.from_mapping(
SECRET_KEY='dev',
DATABASE=os.path.join(app.instance_path, 'flaskr.sqlite'),
)
if test_config is None:
# load the instance config, if it exists, when not testing
app.config.from_pyfile('config.py', silent=True)
else:
# load the test config if passed in
app.config.from_mapping(test_config)
# ensure the instance folder exists
try:
os.makedirs(app.instance_path)
except OSError:
pass
# a simple page that says hello
@app.route('/hello')
def hello():
return 'Hello, World!'
return app
- app = Flask(name,instance_relative_config=True)这句创建了flask实例,name 是现在的python模块的名字,应用需要知道它的安装的路径
;instance_relative_config=True 告诉应用是和instance文件夹有关的,实例文件夹是在flaskr外面,并且其保留着不能提交给版本控制的本地数据 - app.config.from_mapping() 设置了应用将会用到的配置文件。其中secret_key是用于保证数据安全的密钥,但是这个密钥在项目部署是将会被一个随机值覆盖;DATABASE是数据库文件保存的地方。
- app.config.from_pyfile()将会覆盖在config.py中得来的默认的配置
- os.makedirs()确保了app.instance_path存在,flask并不会自动创建实例文件夹,但是它是必要的,因为项目将会在这里创建数据库文件。
- @app.route(),创建了一个简单的路由,它建立了url和/hello之间的联系,并在最后返回一个响应。
运行应用
在终端中的flaskr当前路径下运行以下代码(window版,其他版本参见)
set FLASK_APP=flaskr
set FLASK_ENV=development
flask run
输出这个样:
* Serving Flask app "flaskr"
* Environment: development
* Debug mode: on
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 855-212-761
这时便可以访问http://127.0.0.1:5000/hello来查看结果。
定义和访问数据库
本次的应用将会采用SQLite数据库存储用户信息,python中在sqlite3中有内置的支持。
SQLite非常方便,原因在于其不需要设置一个一个隔离的数据库服务器,但是如果在同一时间有并发的请求写入数据库的话,写入放入速率就会降低。这一点会在大的项目中出现。
连接数据库
数据库的任何操作都是在连接好的基础上实现的。在web应用中,数据库连接多数发生请求到来时,在处理请求的某一个时间点连接会被创建,响应被发送后连接会被关闭。
flaskr/db.py
import sqlite3
import click
from flask import current_app, g
from flask.cli import with_appcontext
def get_db():
if 'db' not in g:
g.db = sqlite3.connect(
current_app.config['DATABASE'],
detect_types=sqlite3.PARSE_DECLTYPES
)
g.db.row_factory = sqlite3.Row
return g.db
def close_db(e=None):
db = g.pop('db', None)
if db is not None:
db.close()
我们在系列一种稍微提到过g对象。g对象对于每一个请求来说都是独一无二的,它的主要功能是存储数据,这些数据可能会在请求的过程中会被用到。如果get_db在同一个请求中被第二次调用的话,连接会被重用而非重新建立一个连接。
上面代码中:
- current_app是指向处理请求的flask应用的一个特殊的对象,因为你使用的是一个工厂函数,所以在你调用这个函数之前,并不会有对象出现。current_app使用的原因就在于只有当应用已经创建的时候且其正在处理一个请求的时候,get_db才会被调用。
- sqlite3.connect()建立了一个到文件的连接,这个文件被DataBase的配置键指向。这个文件在数据库初始化之后才会存在。
- sqlite3.Row 告诉连接返回的行起着字典的作用,这样就可以通过名字来访问列的数据。
创建表
SQLite中,数据是被存储在表和列中的,这些在你存储和检索数据之前就需要被创建, Flaskr将会在user表中存储user,在post表中存储评论的信息。创建Sql文件的命令:
flaskr/schema.sql
DROP TABLE IF EXISTS user;
DROP TABLE IF EXISTS post;
CREATE TABLE user (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT UNIQUE NOT NULL,
password TEXT NOT NULL
);
CREATE TABLE post (
id INTEGER PRIMARY KEY AUTOINCREMENT,
author_id INTEGER NOT NULL,
created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
title TEXT NOT NULL,
body TEXT NOT NULL,
FOREIGN KEY (author_id) REFERENCES user (id)
);
下面的函数将会返回sql命令给db.py
def init_db():
db = get_db()
with current_app.open_resource('schema.sql') as f:
db.executescript(f.read().decode('utf8'))
@click.command('init-db')
@with_appcontext
def init_db_command():
"""Clear the existing data and create new tables."""
init_db()
click.echo('Initialized the database.')
上面代码中:
- open_resource()将会打开一个与flaskr包有关的文件(schema.sql),用处在于当之后部署应用时,你不必知道这个文件的具体位置。
- get_db将会返回一个数据库连接,这被用来执行从文件中读取的命令。
- click.command()定义了一个命令行的命令(init_db),这个命令将会调用init_db()函数,并向用户展示一个执行成功的信息。
注册该应用
close_db和init_db_command函数都需要一个应用实例,但是我们所使用的是工厂函数,在写这个工厂函数时实例是不可以用的。因此,必须要写一个能够获取一个实例并注册应用的函数。
flaskr/db.py
def init_app(app):
app.teardown_appcontext(close_db)
app.cli.add_command(init_db_command)
- app.teardown_appcontext()告诉Flaskr在返回响应并且完成清理工作后调用close_db函数
- app.cli.add_command() 增加了一个能被flask命令行调用的新函数。
从工厂中导入和调用这个函数。
flaskr/init.py
ef create_app():
app = ...
# existing code omitted
from . import db
db.init_app(app)
return app
初始化数据库文件
现在init_db命令已经在应用中注册过,使用flask的命令便可以调用它。
如果你仍在之前的页面运行该服务,你最好重新再一个新的终端中运行它
运行init_db的命令
flask init-db
Initialized the database.
现在在你的项目布局中应该会有flaskr.sqlite文件出现。
好了,系列二就到这里,本次主要讲了工厂函数的创建以及数据库连接的建立。
如有错误请多指正!