python案例---正则表达式:re模块
#Python通过re模块提供对正则表达式的支持。
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'hello.*\!')
# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
match = pattern.match('hello, mryang! How are you?')
if match:
# 使用Match获得分组信息
print (match.group())运行结果:hello, mryang!
#match属性和方法
import re
m = re.match(r'(\w+) (\w+)(?P.*)' , 'hello hanxiaoyang!')
print("m.string:", m.string)
print("m.re:", m.re)
print("m.pos:", m.pos)
print("m.endpos:", m.endpos)
print("m.lastindex:", m.lastindex)
print("m.lastgroup:", m.lastgroup)
print("m.group(1,2):", m.group(1, 2))
print("m.groups():", m.groups())
print("m.groupdict():", m.groupdict())
print("m.start(2):", m.start(2))
print("m.end(2):", m.end(2))
print("m.span(2):", m.span(2))
print(r"m.expand(r'\2 \1\3'):", m.expand(r'\2 \1\3'))运行结果: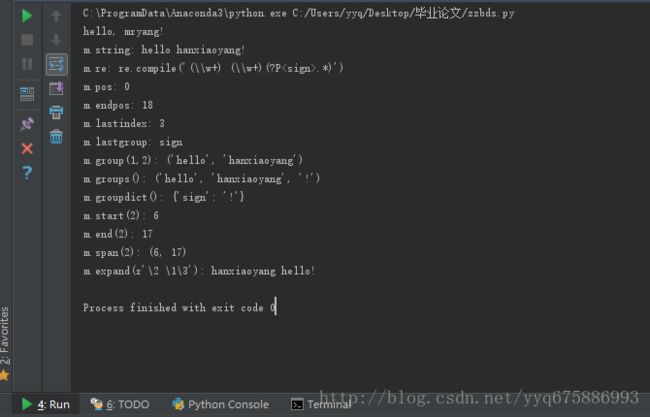
#Pattern
#Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
import re
p = re.compile(r'(\w+) (\w+)(?P.*)' , re.DOTALL)
print("p.pattern:", p.pattern)
print("p.flags:", p.flags)
print("p.groups:", p.groups)
print("p.groupindex:", p.groupindex)运行结果:
p.pattern: (\w+) (\w+)(?P.*)
p.flags: 48
p.groups: 3
p.groupindex: {‘sign’: 3}
#pattern的search方法
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'H.*g')
# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None
# 这个例子中使用match()无法成功匹配
match = pattern.search('hello hanxiaoyang!')
if match:
# 使用Match获得分组信息
print(match.group() )运行结果:hello hanxiaoyang
import re
p = re.compile(r'\d+')
print( p.split('one1two2three3four4'))[‘one’, ‘two’, ‘three’, ‘four’, ”]
import re
p = re.compile(r'\d+')
print p.findall('one1two2three3four4')[‘1’, ‘2’, ‘3’, ‘4’]
import re
p = re.compile(r'\d+')
for m in p.finditer('one1two2three3four4'):
print(m.group())1
2
3
4
#sub 替换
import re
p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello yang!'
print(p.sub(r'\2 \1', s))
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print(p.sub(func, s))结果:
say i, yang hello!
I Say, Hello Yang!
#subn 替换次数
import re
p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello hanxiaoyang!'
print(p.subn(r'\2 \1', s))
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print(p.subn(func, s))结果:
(‘say i, hanxiaoyang hello!’, 2)
(‘I Say, Hello Hanxiaoyang!’, 2)