MySQL: GROUP BY 语句并且搭配HAVING
来源:
https://www.runoob.com/mysql/mysql-group-by-statement.html
建表:
SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `employee_tbl`
-- ----------------------------
DROP TABLE IF EXISTS `employee_tbl`;
CREATE TABLE `employee_tbl` (
`id` int(11) NOT NULL,
`name` char(10) NOT NULL DEFAULT '',
`date` datetime NOT NULL,
`singin` tinyint(4) NOT NULL DEFAULT '0' COMMENT '登录次数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `employee_tbl`
-- ----------------------------
BEGIN;
INSERT INTO `employee_tbl` VALUES ('1', '小明', '2016-04-22 15:25:33', '1'), ('2', '小王', '2016-04-20 15:25:47', '3'), ('3', '小丽', '2016-04-19 15:26:02', '2'), ('4', '小王', '2016-04-07 15:26:14', '4'), ('5', '小明', '2016-04-11 15:26:40', '4'), ('6', '小明', '2016-04-04 15:26:54', '2');
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;
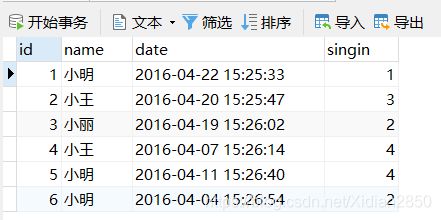
测试记录(不要全部运行,要一条一条单独运行):
SELECT * FROM employee_tbl;
SELECT name, COUNT(*) FROM employee_tbl GROUP BY name;
SELECT date, COUNT(*) FROM employee_tbl GROUP BY date;
SELECT singin, COUNT(*) FROM employee_tbl GROUP BY singin;
SELECT name, SUM(singin) as singin_count FROM employee_tbl GROUP BY name;
SELECT name, SUM(singin) as singin_count FROM employee_tbl GROUP BY name WITH ROLLUP;
SELECT COALESCE(name, '总数'), SUM(singin) as singin_count FROM employee_tbl GROUP BY name WITH ROLLUP;
GROUP BY + 字段 ,更像是根据字段把字段当做表(也就是分组)
group by 搭配having
https://blog.csdn.net/qq_35269216/article/details/90812872
where、聚合函数、having 在from后面的执行顺序:
where>聚合函数(sum,min,max,avg,count)>having
若须引入聚合函数来对group by 结果进行过滤 则只能用having。( 是先执行聚合函数还是先过滤 然后比对我上面列出的执行顺序 一看便知)
HAVING语句通常与GROUP BY语句联合使用,用来过滤由GROUP BY语句返回的记录集。
HAVING语句的存在弥补了WHERE关键字不能与聚合函数联合使用的不足。
SELECT name, COUNT(*) FROM employee_tbl GROUP BY name;
结果:

SELECT name, COUNT(*) FROM employee_tbl GROUP BY name HAVING COUNT(*) < 2;
结果:
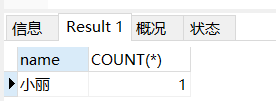
说明:having是在GROUP BY之后返回的结果集的基础上再运算的。也就是having用来过滤GROUP BY执行之后的内容。