物体检测中的评价指标【文末赠书】
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

对于一个检测器,我们需要制定一定的规则来评价其好坏,从而选择需要的检测器。对于图像分类任务来讲,由于其输出是很简单的图像类别,因此很容易通过判断分类正确的图像数量来进行衡量。
物体检测模型的输出是非结构化的,事先并无法得知输出物体的数量、位置、大小等,因此物体检测的评价算法就稍微复杂一些。对于具体的某个物体来讲,我们可以从预测框与真实框的贴合程度来判断检测的质量,通常使用IoU(Interp of Union)来量化贴合程度。
IoU的计算方式如图1所示,使用两个边框的交集与并集的比值,就可以得到IoU,公式如式(1-1)所示。显而易见,IoU的取值区间是[0,1],IoU值越大,表明两个框重合越好。
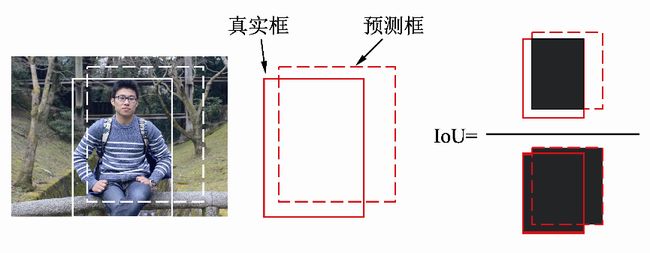
图1 IoU的计算过程

利用Python可以很方便地实现IoU的计算,代码如下:
def iou(boxA, boxB):
# 计算重合部分的上、下、左、右4个边的值,注意最大最小函数的使用
left_max = max(boxA[0], boxB[0])
top_max = max(boxA[1], boxB[1])
right_min = min(boxA[2], boxB[2])
bottom_min = min(boxA[3], boxB[3])
# 计算重合部分的面积
inter =max(0,(right_min-left_max))* max(0,(bottom_min-top_max)
Sa = (boxA[2]-boxA[0])*(boxA[3]-boxA[1])
Sb = (boxB[2]-boxB[0])*(boxB[3]-boxB[1])
# 计算所有区域的面积并计算iou,如果是Python 2,则要增加浮点化操作
union = Sa+Sb-inter
iou = inter/union
return iou
对于IoU而言,我们通常会选取一个阈值,如0.5,来确定预测框是正确的还是错误的。当两个框的IoU大于0.5时,我们认为是一个有效的检测,否则属于无效的匹配。如图2中有两个杯子的标签,模型产生了两个预测框。
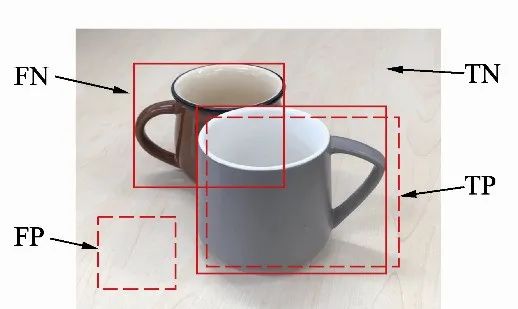
图2 正、负样本判别示例
由于图像中存在背景与物体两种标签,预测框也分为正确与错误,因此在评测时会产生以下4种样本。
·正确检测框TP(True Positive):预测框正确地与标签框匹配了,两者间的IoU大于0.5,如图2中右下方的检测框。
·误检框FP(False Positive):将背景预测成了物体,如图2中左下方的检测框,通常这种框与图中所有标签的IoU都不会超过0.5。
·漏检框FN(False Negative):本来需要模型检测出的物体,模型没有检测出,如图2中左上方的杯子。
·正确背景(True Negative):本身是背景,模型也没有检测出来,这种情况在物体检测中通常不需要考虑。
有了上述基础知识,我们就可以开始进行检测模型的评测。对于一个检测器,通常使用mAP(mean Average Precision)这一指标来评价一个模型的好坏,这里的AP指的是一个类别的检测精度,mAP则是多个类别的平均精度。评测需要每张图片的预测值与标签值,对于某一个实例,二者包含的内容分别如下:
·预测值(Dets):物体类别、边框位置的4个预测值、该物体的得分。
·标签值(GTs):物体类别、边框位置的4个真值。
在预测值与标签值的基础上,AP的具体计算过程如图3所示。我们首先将所有的预测框按照得分从高到低进行排序(因为得分越高的边框其对于真实物体的概率往往越大),然后从高到低遍历预测框。
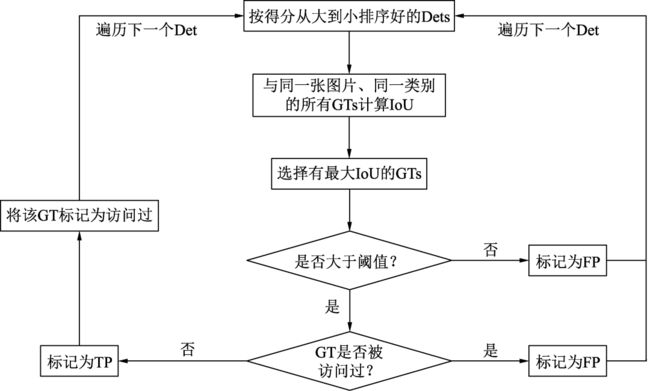
图3 AP的计算过程
对于遍历中的某一个预测框,计算其与该图中同一类别的所有标签框GTs的IoU,并选取拥有最大IoU的GT作为当前预测框的匹配对象。如果该IoU小于阈值,则将当前的预测框标记为误检框FP。
如果该IoU大于阈值,还要看对应的标签框GT是否被访问过。如果前面已经有得分更高的预测框与该标签框对应了,即使现在的IoU大于阈值,也会被标记为FP。如果没有被访问过,则将当前预测框Det标记为正确检测框TP,并将该GT标记为访问过,以防止后面还有预测框与其对应。
在遍历完所有的预测框后,我们会得到每一个预测框的属性,即TP或FP。在遍历的过程中,我们可以通过当前TP的数量来计算模型的召回率(Recall,R),即当前一共检测出的标签框与所有标签框的比值,如式(1-2)所示。

除了召回率,还有一个重要指标是准确率(Precision,P),即当前遍历过的预测框中,属于正确预测边框的比值,如式(1-3)所示。

遍历到每一个预测框时,都可以生成一个对应的P与R,这两个值可以组成一个点(R, P),将所有的点绘制成曲线,即形成了P-R曲线,如图4所示。

图4 物体检测的P-R曲线
然而,即使有了P-R曲线,评价模型仍然不直观,如果直接取曲线上的点,在哪里选取都不合适,因为召回率高的时候准确率会很低,准确率高的时候往往召回率很低。这时,AP就派上用场了,计算公式如式(1-4)所示。

从公式中可以看出,AP代表了曲线的面积,综合考量了不同召回率下的准确率,不会对P与R有任何偏好。每个类别的AP是相互独立的,将每个类别的AP进行平均,即可得到mAP。严格意义上讲,还需要对曲线进行一定的修正,再进行AP计算。除了求面积的方式,还可以使用11个不同召回率对应的准确率求平均的方式求AP。
下面从代码层面详细讲述AP求解过程。假设当前经过标签数据与预测数据的加载,我们得到了下面两个变量:
·det_boxes:包含全部图像中所有类别的预测框,其中一个边框包含了[left, top, right, bottom, score, NameofImage]。
·gt_boxes:包含了全部图像中所有类别的标签,其中一个标签的内容为[left, top, right, bottom, 0]。需要注意的是,最后一位0代表该标签有没有被匹配过,如果匹配过则会置为1,其他预测框再去匹配则为误检框。
下面是所有类别的评测过程。
for c in classes:
# 通过类别作为关键字,得到每个类别的预测、标签及总标签数
dects = det_boxes[c]
gt_class = gt_boxes[c]
npos = num_pos[c]
# 利用得分作为关键字,对预测框按照得分从高到低排序
dects = sorted(dects, key=lambda conf: conf[4], reverse=True)
# 设置两个与预测边框长度相同的列表,标记是True Positive还是False Positive
TP = np.zeros(len(dects))
FP = np.zeros(len(dects))
# 对某一个类别的预测框进行遍历
for d in range(len(dects)):
# 将IoU默认置为最低
iouMax = sys.float_info.min
# 遍历与预测框同一图像中的同一类别的标签,计算IoU
if dects[d][-1] in gt_class:
for j in range(len(gt_class[dects[d][-1]])):
iou = Evaluator.iou(dects[d][:4], gt_class[dects[d][-1]][j][:4])
if iou > iouMax:
iouMax = iou
jmax = j # 记录与预测有最大IoU的标签
# 如果最大IoU大于阈值,并且没有被匹配过,则赋予TP
if iouMax >= cfg['iouThreshold']:
if gt_class[dects[d][-1]][jmax][4] == 0:
TP[d] = 1
gt_class[dects[d][-1]][jmax][4] = 1 # 标记为匹配过
# 如果被匹配过,赋予FP
else:
FP[d] = 1
# 如果最大IoU没有超过阈值,赋予FP
else:
FP[d] = 1
# 如果对应图像中没有该类别的标签,赋予FP
else:
FP[d] = 1
# 利用NumPy的cumsum()函数,计算累计的FP与TP
acc_FP = np.cumsum(FP)
acc_TP = np.cumsum(TP)
rec = acc_TP / npos # 得到每个点的Recall
prec = np.divide(acc_TP, (acc_FP + acc_TP)) # 得到每个点的Precision
# 利用Recall与Precision进一步计算得到AP
[ap, mpre, mrec, ii] = Evaluator.CalculateAveragePrecision(rec, prec)
本文节选自机械工业出版社出版的《深度学习之PyTorch物体检测实战》一书,略有编辑。
赠书福利
2020年1月,百度自动驾驶高级算法工程师重磅力作《深度学习之PyTorch物体检测实战》出版啦!本书从概念、发展、经典实现方法等几个方面系统地介绍了物体检测的相关知识,重点介绍了Faster RCNN、SDD和YOLO这三个经典的检测器,并利用PyTorch框架从代码角度进行了细致讲解。另外,本书进一步介绍了物体检测的轻量化网络、细节处理、难点问题及未来的发展趋势,从实战角度给出了多种优秀的解决方法,便于读者更深入地掌握物体检测技术,从而做到在实际项目中灵活应用。

原价89元,现向3D视觉工坊公众号读者免费赠送5本,并且包邮送到家。
如何免费获得该书呢?
参与方式:请在公众号后台回复“抽奖”,参与抽奖活动
截止时间:2020年8月17日20:00
结果公布:8月17日20:00准时公布获奖名单,请参与者注意小程序抽奖结果,获奖者及时与小助理(微信号:CV3Der)取得联系,谢谢!
如果没有中奖,喜欢本书的粉丝也可以在如下链接优惠购买
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉优质源码,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 