Batch Normalization:加速神经网络训练的通用手段
Batch Normalization:加速神经网络训练的通用手段
原理虽然并不复杂,但是BN(Batch Normalization)越发成为深度学习领域的必备杀器。
1.什么是Batch Normalization?
Batch Normalization于2015年由Sergey Ioffe和Christian Szegedy首次提出,出处为以下的这篇论文。
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
在此之前,基本的一些防止梯度消失、梯度爆炸的方法包括:
1. 换用其他激活函数(比如ReLU)
2. 预学习得到神经网络的初始参数
3. 降低学习速率
4. 限制神经网络的学习自由度(比如Dropout)
更进一步地,本文的Batch Normalization的普适性要更强一些,能使整个学习过程平稳化,从而达到加快学习的效果。
2.内部协变量位移(Internal Covariate Shift)
首先我要先理解协变量位移(Covariate Shift),它一般是指在机器学习和模式识别领域,采样得到的训练集数据的特征值分布通常跟最终的预测数据的特征值分布存在一定的偏差,因此导致算法模型的最终预测效果会产生或多或少的下降。
然而,我们今天要讲解的重点是内部协变量位移(Internal Covariate Shift),则是指深度学习领域进行神经网络模型学习时,常使用随机小批量梯度下降算法,此时每一批从训练集采样得到的数据它们的特征值分布也会存在差异。而这些差异会随着神经网络层数不断的深入而不断增大,这就使得整个神经网络(尤其是饱和非线性的部分)的参数难以收敛。
3.白化(whitening)
所谓白化,其实就是先进行PCA,求出新特征空间中X的新坐标,然后再对新的坐标进行方差归一化操作。
对于输入数据集X,经过白化处理后,新的数据X’满足两个性质:
(1)特征之间相关性较低;
(2)所有特征具有相同的方差。
该算法常用于图像处理当中,由于图像中相邻像素之间具有很强的相关性(一个像素的颜色值往往跟它周围的像素的颜色值十分接近),因此常使用白化对输入的像素特征向量进行白化,从而降低输入的冗余性。
同样地,白化也能起到抑制内部协变量位移(Internal Covariate Shift)的作用。我们接下来要详细介绍的Batch Normalization跟白化有点异曲同工之妙。
4.NB算法实现
首先,假设我们模型的某一层接受一个有m个数据的mini-batch
而这一层要学习的参数为
计算均值和方差
对数据进行等均值等方差变换
那么得到的 Y=y1⋅⋅⋅ym 则是这一层网络的数据输出
5.Batch Normalization的好处
①可以使用较大的学习速率
在一般的深度学习中,如果强行提高学习速率,会因为每层网络都会对参数的梯度进行缩放,从而导致梯度消失/梯度爆炸。而使用了Batch Normalization之后,每一次的放缩将不会相互叠加,从而可以大胆地使用更大的学习速率,而不用担心引起梯度消失/梯度爆炸。
②带有正则化的效果
之前,深度学习防止过拟合的最常用的两种方法包括L2正则化和Dropout,但它们都会使模型的训练所需时间增加,而且往往会增加一定的调参工作。而Batch Normalization则可以很好地规避掉这个问题
③不受网络参数初始值的影响
对于一些特定分布的数值(比如像素一般位0-255),模型的训练时间和最终训练效果将十分依赖于网络参数初始值。但是经过Batch Normalization归一化处理后,我们就不需要针对某一维度的数据进行网络参数初始值进行精心调优,统一使用标准正态分布随机初始化即可。
6.编程验证
接下来我们,将对比使用Batch Normalization前后,模型的性能表现差异。
①安装IFLearn
首先先安装TensorFlow,然后安装深度学习前端框架TFlearn
$ pip install tflearn②对CIFAR-10数据集进行分类
这个数据集是从80 Million Tiny Images当中选取6W张图片。
它们均为32*32的RGB彩色图片,共10个分类。

③Python编程实现(没有使用Batch Normalization)
首先先加载后续需要用到的库
from __future__ import division, print_function, absolute_import
import tflearn
from tflearn.data_utils import shuffle, to_categorical
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.estimator import regression
from tflearn.data_preprocessing import ImagePreprocessing
from tflearn.data_augmentation import ImageAugmentation接着下载CIFAR-10数据集
from tflearn.datasets import cifar10
(X, Y), (X_test, Y_test) = cifar10.load_data()
X, Y = shuffle(X, Y)
Y = to_categorical(Y, 10)
Y_test = to_categorical(Y_test, 10)增加白化处理和数据增强预处理环节。所谓数据增强(Data Augmentation)就是对于某一张图片通过各种操作(镜像、旋转、加高斯噪声)产生很多张“新图片”的技巧,是一种在图像处理领域增加训练样本的常用方法。
img_prep = ImagePreprocessing()
img_prep.add_featurewise_zero_center()
img_prep.add_featurewise_stdnorm()
img_aug = ImageAugmentation()
img_aug.add_random_flip_leftright()
img_aug.add_random_rotation(max_angle=25.)卷积神经网络建模
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
network = conv_2d(network, 32, 3, activation='tanh')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='tanh')
network = conv_2d(network, 64, 3, activation='tanh')
network = max_pool_2d(network, 2)
network = fully_connected(network, 512, activation='tanh')
network = fully_connected(network, 10, activation='softmax')
network = regression(network, optimizer='sgd',
loss='categorical_crossentropy',
learning_rate=0.001)
model = tflearn.DNN(network, tensorboard_verbose=0)
model.fit(X, Y, n_epoch=50, shuffle=True, validation_set=(X_test, Y_test),
show_metric=True, batch_size=96, run_id='Normal')运行程序,并使用TensorBoard观察模型性能
$ python normal.py
$ tensorboard --log_dir=/tmp/tflearn_logs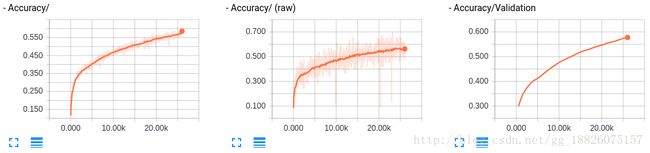
④Python编程实现(使用Batch Normalization)
加载TFLearn的Batch Normalization处理函数
from tflearn.layers.normalization import batch_normalization加入Batch Normalization处理,并把学习速率增大30倍
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
network = conv_2d(network, 32, 3, activation='tanh')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='tanh')
network = conv_2d(network, 64, 3, activation='tanh')
network = batch_normalization(network)
network = max_pool_2d(network, 2)
network = fully_connected(network, 512, activation='tanh')
network = batch_normalization(network)
network = fully_connected(network, 10, activation='softmax')
network = regression(network, optimizer='sgd',
loss='categorical_crossentropy',
learning_rate=0.03)运行结果对比
$ python batch_norm.py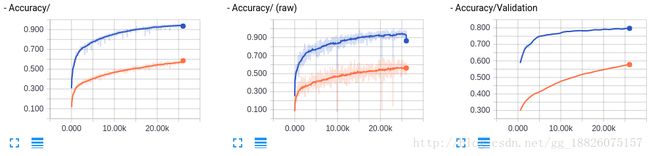
橙色的曲线为没有加入BN,蓝色的曲线为加入了BN
我们不仅可以大胆地增大学习速率,使得训练时长大大缩短,而且整个模型的性能也得到大大提高。但是,我们可以注意到右下角的Loss/Validation的蓝色曲线出现了先降后升的现象,这是典型的过拟合的表现,下面考虑加入Dropout看下有无改善。
⑤Python编程实现(使用Batch Normalization,并加上Dropout)
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
network = conv_2d(network, 32, 3, activation='tanh')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='tanh')
network = conv_2d(network, 64, 3, activation='tanh')
network = batch_normalization(network)
network = max_pool_2d(network, 2)
network = fully_connected(network, 512, activation='tanh')
network = dropout(network, 0.8)
network = fully_connected(network, 10, activation='softmax')
network = regression(network, optimizer='sgd',
loss='categorical_crossentropy',
learning_rate=0.03)运行结果对比
$ python batch_norm_dropout.py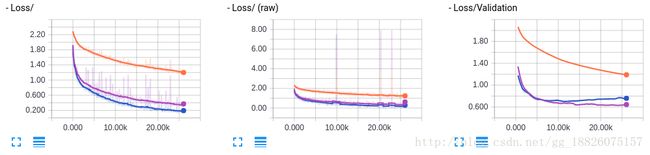
紫色的曲线便是增加了Dropout之后的模型性能表现曲线。