CNN网络中卷积层的正向传播与反向传播理解
1. 基础理论
1.1 网络结构梳理
在CNN网络模型是建立在传统神经网络结构上的,对于一个传统的神经网络其结构是这样的:
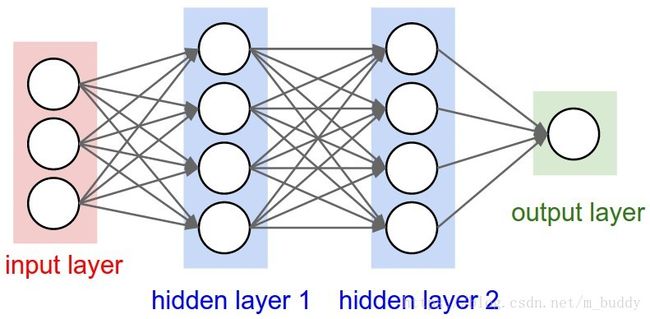
从上面可以看出,其模型是全连接的。若是使用一幅512*512大小的图像作为输入,隐层1中含有10000个神经元,那么在不算偏置项的情况下,权值参数的个数就是512*512*10000个,如此巨大的参数量不计较内存其优化也是比较困难的。
在此基础上学者推出了CNN网络模型,其较为经典的运用便是LeNet,下面是其结构展示:
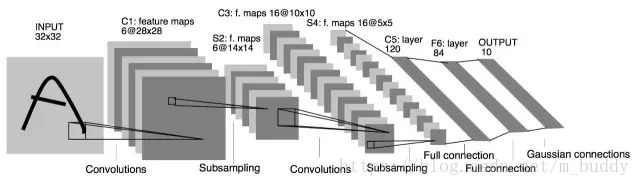
可以从上图中看出,其网络结构中主要存在两个之前没有的成分:卷积层(ConvNet)、池化层(PoolNet)。对于上图中的卷积层C1可以看到它包含的是6个卷积核,每个卷积核的大小是5*5,因而其参数量是6*(5*5+1)。相比之前的传统神经网络在参数量上就小了很多。说道卷积其具体的含义就是对图像使用掩膜进行运算,与传统图像处理中的中值滤波、均值滤波有类似性,可以使用下图进行解释:
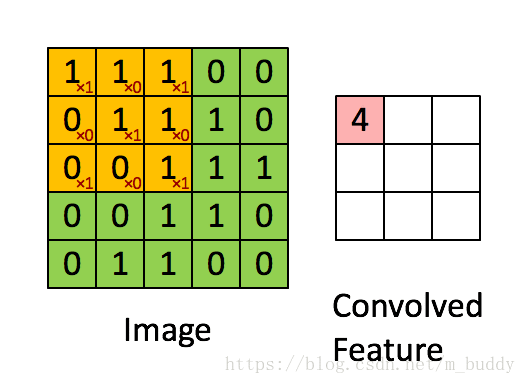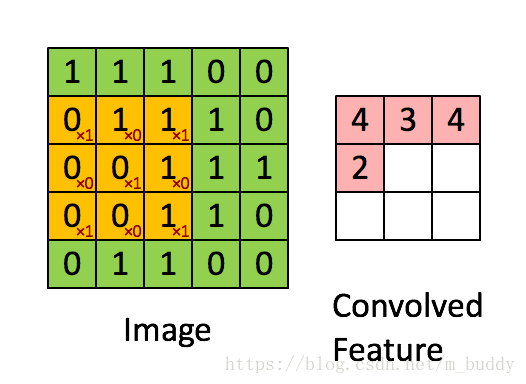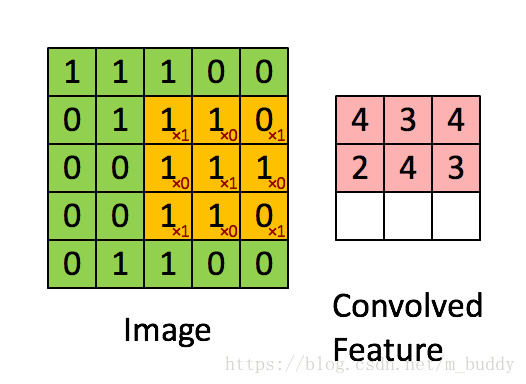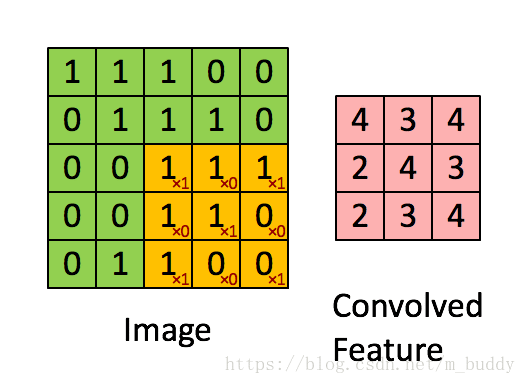
在上图中可以看到黄色的滑动窗口在图像矩阵中进行滑动,从而得到了最后的卷积结果。对于卷积之后图像的尺寸是有一个计算公式的,当下假设输入图像的尺寸 W∗H W ∗ H ,卷积核的尺寸为 Wk∗Hk W k ∗ H k ,填充用的 padding=p p a d d i n g = p ,卷积的步长为 stride=s s t r i d e = s 。则生成的卷积结果尺寸 Wc∗Hc W c ∗ H c 的计算公式为:
那么为什么需要卷积层呢?全连接层通过相应参数的变换也能获得类似的效果,着这样做处于以下两点:
(1)在使用了卷积层之后,网络中的参数会少很多,这一点在外文中有叙述
(2)卷积层在运算的过程中使用了图像的局部相关性。这是因为一个像素通常是和其周围的像素的相关性较大,从而组成诸如角点、边缘之类的特征。但是,相对较远的像素其相关性就不是那么大了,因而在卷积计算的过程中关注了像素附近的像素,忽略较远的像素。其实在卷积之后一般会跟上一层Pooling层,它是从附近的卷积结果中提取更具有价值的信息,进一步丢弃掉冗余信息。
1.2 传统模型的推导
对于传统的神经网络中正向传播与反向传播不是很了解的朋友,可以看看下面的内容:
1. 神经网络
2. 反向传导算法
2. 卷积层正向传播
2.1 模型参数
一般来讲定义的CNN模型参数是:
(1)一般我们的卷积核不止一个,比如有K个,那么我们输入层的输出,或者说第二层卷积层的对应的输入就K个。
(2)卷积核中每个子矩阵的的大小,一般我们都用子矩阵为方阵的卷积核,比如FxF的子矩阵。
(3)填充padding,我们卷积的时候,为了可以更好的识别边缘,一般都会在输入矩阵在周围加上若干圈的0再进行卷积,加多少圈则P为多少。
(4)步幅stride(以下简称S),即在卷积过程中每次移动的像素距离大小。
2.2 Caffe中的正向传播
通过前面1.1节的讲解已经能够很清楚的知道CNN网络卷积层正向传播的过程就是卷积的过程,我们可以很方便地使用4重for循环就可以搞定,但是在Caffe中的卷积计算却并不是这么回事。那么其计算时怎么回事呢?首先来看Caffe中的前向传播函数:
template <typename Dtype>
void ConvolutionLayer::Forward_cpu(const vector 在其函数中使用了this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,...这个地方就是调用进行卷积运算了。再来看看这个函数里面发生的了什么
template type>
void BaseConvolutionLayertype>::forward_cpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
const Dtype* col_buff = input;
if (!is_1x1_) {
if (!skip_im2col) {
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data()); //图像转换为“列向量”
}
col_buff = col_buffer_.cpu_data();
}
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemmtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
} 从上面的代码中可以看到,这里首先对输入的数据使用conv_im2col_cpu函数进行处理,这个函数到最后其实就是调用了下面这个函数
//将图像转换为“列向量”
template <typename Dtype>
void im2col_cpu(const Dtype* data_im, const int channels,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
const int dilation_h, const int dilation_w,
Dtype* data_col) {
const int output_h = (height + 2 * pad_h -
(dilation_h * (kernel_h - 1) + 1)) / stride_h + 1;
const int output_w = (width + 2 * pad_w -
(dilation_w * (kernel_w - 1) + 1)) / stride_w + 1;
const int channel_size = height * width;
for (int channel = channels; channel--; data_im += channel_size) {
for (int kernel_row = 0; kernel_row < kernel_h; kernel_row++) {
for (int kernel_col = 0; kernel_col < kernel_w; kernel_col++) {
int input_row = -pad_h + kernel_row * dilation_h;
for (int output_rows = output_h; output_rows; output_rows--) {
if (!is_a_ge_zero_and_a_lt_b(input_row, height)) {
for (int output_cols = output_w; output_cols; output_cols--) {
*(data_col++) = 0;
}
} else {
int input_col = -pad_w + kernel_col * dilation_w;
for (int output_col = output_w; output_col; output_col--) {
if (is_a_ge_zero_and_a_lt_b(input_col, width)) {
*(data_col++) = data_im[input_row * width + input_col];
} else {
*(data_col++) = 0;
}
input_col += stride_w;
}
}
input_row += stride_h;
}
}
}
}
}这个函数就是将数据转换成为了“列向量”,其输出的维度是 (Wk∗Wk)∗(Wo∗Ho) ( W k ∗ W k ) ∗ ( W o ∗ H o ) ,在进行卷积运算的时候上面转换得到的“列向量”是在右边,卷积核在运算的左边。上面输出矩阵的每一行存储的是和卷积核某一个参数相乘的所有图像数据,每一列存储的是一个卷积子操作所需要的数据。
3. 卷积层反向传播
上面说到了在进行卷积操作之前需要将图像转换成为“列向量”,这是为什么呢?我的一个直观的理解便是方便进行反向传播,也可以看做是对卷积层反向传播的更加直观的理解,相当于就是之前将的传统神经网络的相连关系,这样带来的效果便是更加直观,像Caffe这样的库也是使用这样的方式进行的。但是这样的矩阵转换与运算会消耗内存也耗时,因而Caffe中使用了快速的CuDNN库来实现。
在反向传播中使用的原理与传统神经网络的反向传播原理类似。这里先写到这里,后面再来补充。
4. 参考资料
1.UFLDL教程
2. 卷积神经网络(CNN)前向传播算法
3. 卷积神经网络(CNN)反向传播算法