利用 MSR Identity Toolkit v1.0 中的 GMM-UBM 做语音说话人确认
前言
最近开始搞毕设,刚完成一个小任务,趁着有空,整理一下这学期的实验。时间有点久远了,害怕时间再长一些,自己真的就全忘光了。
本实验很大一部分参考了班级里一位萌妹子的博客,在这里贴一下地址:hit说话人确认实验
实验中,就写了一些生成配置文件的 python 代码,关于说话人确认部分的代码基本没写;因此感觉,这个实验,有点,,,。。。emm,主要还是自己事情有点多,直接选了个最简单的。废话不多说,开始进入正题。
实验内容
开始之前,先放一下实验的资源文件:
链接:https://pan.baidu.com/s/1Y17P4HEvaKcU_30Om2zD8g
提取码:b5th
我的实验+报告:
链接:https://pan.baidu.com/s/1EC30P7TnTL5pBMw5gxnqGg
提取码:4pk9
为避免链接失效,放一份在csdn上,不过默认是要积分的,不知道咋设置成0(还没审核通过,等审核通过再放链接)
实验的主要内容就是生成所有的配置文件。
MFCC特征的配置文件:
- hcopy.scp
MSR 的配置文件:
- ubm.lst
- speaker_model_maps.lst
- trials.lst
注意后三个文件的路径信息,需要在代码中稍微改一下。具体的文件格式在上面的代码链接中。
语料选择
首先,第一步是语料的选择问题,实验要求中,语料的介绍如下:
117名说话人,男性
每名说话人几百条语料
Wav格式,16kHz 16bit
语料很多很短,不足3秒
开始选择数据之前,先来捋一捋GMM-UBM算法的流程。由于 UBM 算法的特点,首先要选取很多数据进行通用背景模型训练;训练好后,再训练说话人确认模型;最后进行测试。大致流程就是这样,我们要先选择 UBM 的训练数据集,再选择要训练模型的说话人数据集,最后再选择测试用的数据集,一共三部分。
我个人的选择如下:
一共 117 个说话人,每个说话人至少有 364 个语音;使用前 90 个说话人的所有语音训练通用背景模型 ubm,使用后 27 个说话人的前 300 个语音进行训练,得到 27 个模型;其余语音进行测试,测试中,从所有正确的说话人中选取 301-321 共 20 个语音作为 target,从其他 26 个说话人的 320 以外的语音中随机选取 20 个语音,共 26 * 20 = 520个,作为 imposter;然后训练,打分。
实验方案设计
这个不多说,第一步已经说了,简单列举一下:
一共分为四个步骤:
-
1、训练UBM通用背景模型
-
2、最大后验准则MAP从UBM通用背景模型里面训练每一个说话人的声学模型
-
3、交叉得分
-
4、计算最终的测试效果
代码描述
我用的 GMM-UBM 算法代码(没有改几行):
clc
clear
%% Step0: Opening MATLAB pool
nworkers = 12;
nworkers = min(nworkers, feature('NumCores'));
% 打开并行池parpool
% 注意:matlab 新版本缺少matlabpool,改用parpool
if isempty(gcp('nocreate'))
parpool;
end
%% Step1: Training the UBM
dataList = 'lists/ubm.lst';
nmix = 256;
final_niter = 10;
ds_factor = 1;
%ubm = gmm_em(dataList, nmix, final_niter, ds_factor, nworkers); % 训练通用背景模型
%save('ubm.mat','ubm') % 保存模型
ubm = load('ubm.mat'); % 加载模型
ubm = ubm.ubm
%% Step2: Adapting the speaker models from UBM
fea_dir = '';
fea_ext = '';
fid = fopen('lists/speaker_model_maps.lst', 'rt');
C = textscan(fid, '%s %s');
fclose(fid);
model_ids = unique(C{1}, 'stable');
model_files = C{2};
nspks = length(model_ids);
map_tau = 10.0;
config = 'mwv';
gmm_models = cell(nspks, 1);
for spk = 1 : nspks,
ids = find(ismember(C{1}, model_ids{spk}));
spk_files = model_files(ids);
spk_files = cellfun(@(x) fullfile(fea_dir, [x, fea_ext]),... %# Prepend path to files
spk_files, 'UniformOutput', false);
gmm_models{spk} = mapAdapt(spk_files, ubm, map_tau, config);
end
%% Step3: Scoring the verification trials
fea_dir = '';
fea_ext = '';
trial_list = 'lists/trials.lst';
fid = fopen(trial_list, 'rt');
C = textscan(fid, '%s %s %s');
fclose(fid);
[model_ids, ~, Kmodel] = unique(C{1}, 'stable'); % check if the order is the same as above!
[test_files, ~, Ktest] = unique(C{2}, 'stable');
test_files = cellfun(@(x) fullfile(fea_dir, [x, fea_ext]),... %# Prepend path to files
test_files, 'UniformOutput', false);
trials = [Kmodel, Ktest];
scores = score_gmm_trials(gmm_models, test_files, trials, ubm);
save('scores.mat','scores') % 保存模型
%scores = load('scores.mat') % 加载模型
%scores = scores.scores
%% Step4: Computing the EER and plotting the DET curve
nSpeakers = 27; % 一共 27 个模型
% 测试样本中,每个说话人选取 20 个语音,其中 20 个是 target,其余 26 * 20 个是 impostor
imagesc(reshape(scores, 270*2, nSpeakers))
title('Speaker Verification Likelihood (GMM Model)');
ylabel('Test # (Channel x Speaker)'); xlabel('Model #');
colorbar; drawnow; axis xy
figure
labels = C{3};
eer = compute_eer(scores, labels, true);
(一)提取 MFCC 特征
选择 UBM 方法,最与众不同的就是要手动生成 MFCC 特征。实验中使用的是去年的 HTK 包来从 wav 文件中提取 MFCC 特征,首先用以下代码,生成 HTK 下的 list.scp 文件:
import os
import re
filePath = '.\\Beijing'
folder_list = os.listdir(filePath)
file_scp = '.\\HTK\\list.scp'
for folder in folder_list:
if not re.match(r'm[0-9]{3}', folder): # 排除 非语音文件夹
continue
fileName_list = os.listdir(filePath + '\\' + folder)
for fileName in fileName_list: # 排除 非wav 文件
if not re.match(r'.wav', fileName[-4:]):
continue
path_src = '.' + filePath + '\\' + folder + '\\' + fileName
path_dest = '..\\Beijing_MFCC' + '\\' + folder + '\\' + fileName
path_dest = path_dest[:-4] + '.mfc'
with open(file_scp, 'a') as f:
f.write(path_src + '\t' + path_dest + '\n')
# 创建文件夹
isExists=os.path.exists('.\\Beijing_MFCC' + '\\' + folder)
if not isExists :
os.makedirs('.\\Beijing_MFCC' + '\\' + folder)
print(folder)
然后,使用命令 .\hcopy -A -D -T 1 -C tr_wav.cfg -S .\list.scp 生成所有语音的 MFCC 特征,生成结束后,显示如图效果:
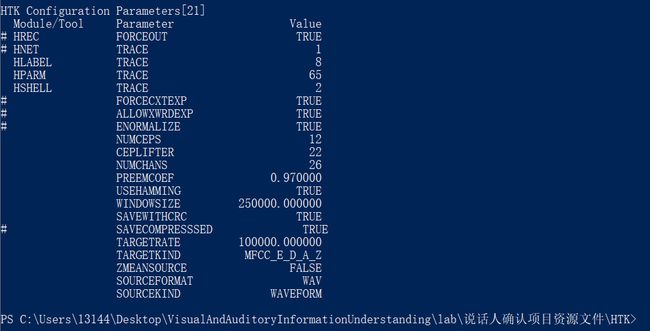
(二)使用 GMM-UBM 训练
第 0 步:打开并行线程池
由于 matlab 新版本缺少 matlabpool,因此改用parpool :
if isempty(gcp('nocreate'))
parpool;
end
第一步:训练UBM通用背景模型
由于 UBM 训练时,最好使用比较多的数据,一共 117 个说话人,每个说话人至少有 364 个语音;本实验中,我使用了前 90 个说话人的所有语音来训练通用背景模型 UBM
由于需要生成 ubm.lst 文件,我直接利用 nodepad++ 的替换功能,将刚刚生成的 list.scp 文件里的部分内容删除,即可得到所需要的文件。
-
首先删除 wav 文件的地址,利用正则表达式进行替换:将
\..\\Beijing\\m[0-9]{3}\\m[0-9]{3}\-[0-9]*\.wav\t替换为空字符串 -
再删除 m001 - m090 之外的说话人(用于自适应训练)
进行训练,大概半小时到四十分钟即可训练好
第二步:最大后验准则MAP训练每一个说话人的声学模型
这里,我使用后 27 个说话人的前 300 个语音进行训练,得到 27 个模型。
由于需要生成 speaker_model_maps.lst 文件,同样利用 nodepad++ 的替换功能,将刚刚生成的 list.scp 文件里的部分内容删除,即可得到所需要的文件。操作如下:
-
首先,还是删除 wav 文件的地址,利用正则表达式进行替换:
\..\\Beijing\\m[0-9]{3}\\m[0-9]{3}\-[0-9]*\.wav\t替换为空字符串 -
再将大于 300 的替换掉
\.\.\\Beijing_MFCC\\m[0-9]{3}\\m[0-9]{3}\-3[0-9][1-9]\.mfc替换为空字符串
\.\.\\Beijing_MFCC\\m[0-9]{3}\\m[0-9]{3}\-3[1-9]0\.mfc替换为空字符串 -
再换掉空换行
^[\s]*\n -
增加说话人标签:
将\..\\Beijing_MFCC\\(m[0-9]{3})替换为$1 \..\\Beijing_MFCC\\$1 -
最后,删除 m001-m090 说话人,得到 speaker_model_maps.lst 文件。
第三步:打分
打分可以当做一种测试操作,本实验里,我从所有正确的说话人中选取 301-321 共 20 个语音作为 target,从其他 26 个说话人的 320 以外的语音中随机选取 20 个语音,共 26 * 20 = 520个,作为 imposter;每个人,有 27 * 20 = 540个测试样例,其中20个正例,520个反例;一共27个说话人,故有 27 * 540 = 14580
需要自己生成 trails.lst文件,我使用如下代码进行生成:
import os
import re
import random
filePath = '.\\Beijing_MFCC'
folder_list = os.listdir(filePath)
file_trails = '.\\code\\lists\\trials.lst'
def write_impostor(label, forward):
# 添加非该说话人语音
for folder in folder_list:
if not re.match(r'm[0-9]{3}', folder): # 排除 非语音文件夹
continue
num = int(folder[1:])
if num <= 90: # 排除训练 UBM 的语音文件
continue
if forward:
if num >= int(label[1:]):
continue
else:
if num <= int(label[1:]):
continue
for i in random.sample(range(321,364), 20):
path = ' ..\\Beijing_MFCC\\' + folder + "\\" + folder + '-' + str(i) + '.mfc'
fl = open(path[2:],'rb')
fl.close()
with open(file_trails, 'a') as f:
f.write(label + path + ' impostor' + '\n')
def write_trail():
for folder in folder_list:
if not re.match(r'm[0-9]{3}', folder): # 排除 非语音文件夹
continue
num = int(folder[1:])
if num <= 90: # 排除训练 UBM 的语音文件
continue
print(folder)
fileName_list = os.listdir(filePath + '\\' + folder)
write_impostor(folder, True)
# 添加自适应语音文件路径
for fileName in fileName_list:
num = int(fileName[5:-4])
if num <= 300 : # 排除自适应训练的语音文件
continue
if num <= 320 : # 301-320 共 20 个语音作为测试
path = ' ..\\Beijing_MFCC\\' + folder + "\\" + fileName
fl = open(path[2:],'rb')
fl.close()
with open(file_trails, 'a') as f:
f.write(folder + path + ' target' + '\n')
# 添加非该说话人信息
# 26 * 20 = 520 个 impostor
write_impostor(folder, False)
if __name__ == "__main__":
write_trail()
生成完 trails.lst 后,即可开始训练了。
第四步:查看测试效果
使用已给的 demo 中的代码进行可视化,在下一部分中。
实验结果及分析
最终的到的实验结果如图所示:
得分效果如下:

FNR-FPR 曲线如下:

最后
这个实验主要是体验了一下怎么使用 GMM-UBM 算法,并没有太多的技术含量,主要自己也不是很想做实验,没有选择其他方法。
先在这里记录一下,毕竟也是自己一点点做出来的,或许以后某一天还会用到。
00附加11
视觉实验是二选一,我还是选了最简单的—— KCF 视觉追踪。不过我是实在不知道这个实验要写啥,直接放个我的实验链接吧,保存一下代码和报告:
链接:https://pan.baidu.com/s/1iCDxSBnjatli6TWxQQ-lAw
提取码:fz2u
最后还要提一下,CSDN 删除自己上传的资源还要发帖去找管理员,,不想上传实验了,以后上传资源还是要谨慎一些