论文笔记_2018-BMVC-Light-Weight RefineNet for Real-Time Semantic Segmentation
目录
论文基本情况
内容
摘要
介绍
相关工作
语义分割 Semantic segmentation
实时分割 Real-Time Segmentation
其他领域的实时推断 Real-Time Inference in Other Domains
RefineNet的网络架构
Light-Weight RefineNet 改进方法
1)替换3*3卷积为1*1卷积
2)省略RCU模块
3)使用轻量级骨干网
实验结果
总结
参考
论文基本情况
- 题目:Light-Weight RefineNet for Real-Time Semantic Segmentation
- 作者:
- Vladimir Nekrasov [email protected]
- Chunhua Shen [email protected]
- Ian Reid [email protected]
- 出 处:2018 BMVC ?
- Nekrasov, V., Shen, C., & Reid, I. (2018). Light-weight refinenet for real-time semantic segmentation. arXiv preprint arXiv:1810.03272.
- 代码地址:https://github.com/DrSleep/light-weight-refinenet
- 论文地址:http://bmvc2018.org/contents/papers/0494.pdf
内容
该文的目的很简单,在CVPR2017的RefineNet语义分割算法基础上减少模型参数和计算量。
摘要
我们认为有效和高效的语义图像分割是一项重要的任务。特别是,我们将一种功能强大的语义分段架构(称为RefineNet [46])改编为更加紧凑的架构,甚至适用于需要在高分辨率输入上实现实时性能的任务。为此,我们在原始设置中确定了计算上昂贵的块,并提出了两种旨在减少参数数量和浮点运算的修改。通过这样做,我们实现了两倍以上的模型缩减,同时保持了几乎完整的性能水平。我们最快的模型在512×512输入的通用GPU卡上经历了从20 FPS到55 FPS的显着提升,在PASCAL VOC的测试装置上平均性能达到81:1%[18],而最慢的模型具有32 FPS(来自原始的17 FPS)在同一数据集上显示的平均值为82:7%。另外,我们展示了我们的方法可以轻松地与轻量级分类网络混合:使用仅包含3:3M参数并且仅执行9:3B浮点运算的模型,PASCAL VOC的平均均值达到79:2%。
介绍
深度学习的经验成功数量不断增加,几乎每个月都有新的技术和架构突破可用。特别是,深度学习已成为计算机视觉,自然语言处理,机器人技术,音频处理等大多数领域的默认选择[21,22,24,37,40,44,57,61,65,67,69,70, 72、75]。然而,这些突破通常以昂贵的计算需求为代价,这阻碍了它们在需要实时处理的任务中的直接适用性。这个故事的优点在于,许多研究人员已根据经验证明,经常有很多冗余操作[1、16、17、27、31、36、68],并且这种冗余可以(并且应该是)为了在保持性能不变的同时获得速度优势而进行开发。故事的坏处在于,在大多数情况下,还没有(通用的)通用方法来利用这种冗余。例如,诸如知识蒸馏[1、3、31、58]和修剪[26、27、29、42]之类的方法需要我们访问已经预先训练的大型模型,以便训练较小的模型。相同(或接近)的效果。显然,有时可能不可行。相比之下,为高分辨率输入的特定场景设计新颖的体系结构[54,76]限制了同一架构在具有完全不同的属性的数据集上的适用性,并且经常需要从头开始进行昂贵的训练。...
相关工作
语义分割 Semantic segmentation
语义分割的早期方法依赖于手工制作的功能,例如
- HOG [14]和SIFT [50],
- 以及简单的分类器[13,20,62,63]和
- 分层图形模型[39,41,56]。
这一直持续到深度学习的复兴,以及Long等人的一项关键性工作。
- [49]中,作者将深度图像分类网络转换为完全卷积的网络,能够对不同大小的输入进行操作。此外,通过使用膨胀卷积和概率图形模型扩展了这一工作范围[4、45、48、74、78]。
- 其他工作集中在编码器-解码器范式[46、53、54]周围,在该模型中,首先对图像进行逐步降采样,然后逐步进行升采样,以生成与输入大小相同的分割掩码。
- 最近,Lin等 [46]提出了RefineNet,该方法通过在编码器和解码器之间的跳过连接内添加残差单元来扩展编码器-解码器方法。赵等。
- [77]附加了一个多尺度的池化层,以改善本地和全局(上下文)信息之间的信息流;
- Fu等 [19]利用以沙漏方式(in an hour glass manner)排列的多个编码器-解码器块[73],并使用DenseNet [33]获得了竞争性结果。
流行的基准数据集PASCAL VOC [18]上的最新技术属于DeepLab-v3 [7](测试集上86:9%的平均交集)和DeepLab-v3 + [8](分别基于ResNet [30]和Xception [10]的89:0%),其中作者在无用的空间金字塔池块(ASPP)[5]内包括批处理归一化[35]层,并使用了大型的标记数据集[66],并添加了最新版本的解码器。
实时分割 Real-Time Segmentation
上面概述的大多数方法都可能遭受大量参数[46],大量浮点运算[4、5、7、77]或两者[49、53、54、73]的困扰。这些问题构成了在需要实时处理的应用程序中利用此类模型的重大缺陷。
为了减轻它们,有几种特定于任务的方法,例如
- ICNet [76],作者采用PSPNet [77]逐步处理多种图像比例。他们在1024×2048图像上达到30 FPS的速度,在CityScapes的验证集上有67%的平均值[12],但尚不清楚这种方法是否仍将在具有低分辨率输入的其他数据集上获得可靠的性能。
- 或者,Li等 [43]提出了一种级联方法,其中,通过在中间分类器输出上显式设置硬阈值,在级联的每个递进级别中仅处理像素的特定部分。他们展示了在512×512输入分辨率下14:3 FPS的性能,PASCAL VOC的平均值为78:2%[18]。
我们还注意到,其他几个实时分段网络也遵循了编解码器范例,但是还无法获得不错的性能水平。具体来说,
- SegNet [2]在360×480的输入上达到40 FPS,而CityScapes的平均只有57:0%,
- 而ENet [54]在1920×1080的输入上可以使用58在20 FPS推论: 3%的意思是在CityScapes上。
其他领域的实时推断 Real-Time Inference in Other Domains
已经提出了多种与任务无关的解决方案,以通过压缩来加速神经网络中的推理。当前的方法实现了超过100倍的压缩率[34]。其中,最流行的方法包括
- 量化[23、79、81],
- 修剪[26、27、29、42]
- 和知识蒸馏[1、3、31、58]。
- 其他值得注意的例子集中在低秩因式分解和分解(low-rank factorisation and decomposition)的概念上[17,36],其中可以通过利用(线性)结构将较大的层分解为较小的层。
尽管以上所有方法均已证明可有效实现显着的压缩率,但必须首先获取针对当前任务的功能强大但规模较大的预训练模型。我们进一步注意到,这些方法可以用作我们方法基础上的后处理步骤,但是我们将这个方向留给以后进行探索。
最后,最近,提出了许多新的轻量级体系结构[32、34],并且凭经验表明,具有较少数量参数的模型能够获得可靠的性能。为了强调我们的方法与分类网络设计的这种进步是正交的,
- 我们使用两种轻量级体系结构(NASNet-Mobile [82]和MobileNet-v2 [60])进行了实验,并展示了极具竞争力的结果很少的参数和浮点运算。
RefineNet的网络架构

RefineNet使用经典的编码器-解码器架构,CLF为3*3卷积,卷积核个数为语义类的个数,编码器的骨干网可以是任意图像分类特征提取网络,重点是解码器部分含有RCU、CRP、FUSION三种重要结构。
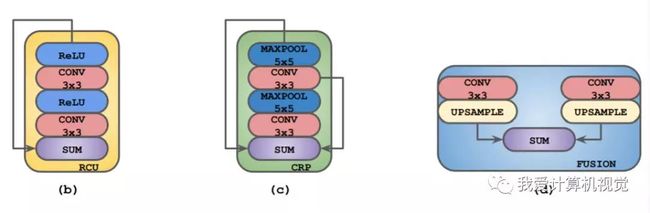
- RCU即residual convolutional unit(残差卷积单元),为经典残差网络ResNet中的residual block去掉batch normalisation部分,由ReLU和卷积层构成。
- CRP为链式残差池化(chained residual pooling),由一系列的池化层与卷积层构成,以残差的形式排列。
- RCU与CRP中使用3*3卷积和5*5池化。
- FUSION部分则是对两路数据分别执行3*3卷积并上采样后求和SUM。
Light-Weight RefineNet 改进方法
改进图示:

1)替换3*3卷积为1*1卷积
虽然理论3*3卷积理论上有更大的感受野有利于语义分割任务,但实际实验证明,对于RefineNet架构的网络其并不是必要的。
2)省略RCU模块
作者尝试去除RefineNet网络中部分及至所有RCU模块,发现并没有任何的精度下降,并进一步发现原来RCU blocks已经完全饱和。

- 表格中RefineNet-101为原始RefineNet网络,RefineNet-101-LW-WITH-RCU为使用了1)中的改进替换卷积,RefineNet-101-LW为使用了1)与2)中的改进替换卷积并省略RCU。
- 从上图表格中可知,1)的改进直接减少了2倍的参数量降低了3倍的浮点计算量,2)的改进则进一步使参数更少浮点计算量更小。
3)使用轻量级骨干网
- 作者发现即使使用轻量级NASNet-Mobile 、MobileNet-v2骨干网,网络依旧能够达到非常稳健的性能表现,性能不会大幅下降。
实验结果
软硬件平台:8GB RAM, Intel i5-7600 处理器, 一块GT1080Ti GPU,CUDA 9.0 ,CuDNN 7.0。
作者首先在NYUDv2 和 PASCAL Person-Part数据集上进行了实验,结果如下:
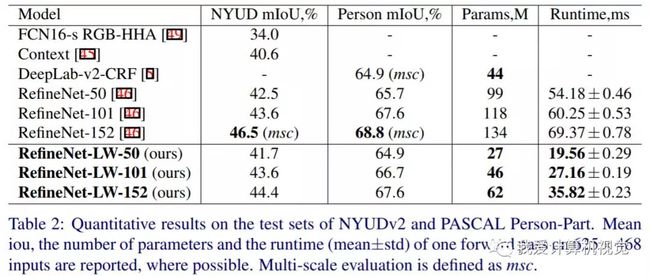
可以看到虽性能略有下降,但参数量和计算时间大幅降低。
同时作者也在PASCAL VOC数据库上进行了实验,并加入NASNet-Mobile 、MobileNet-v2骨干网,发现对比于使用相同骨干网路的目前几乎是最先进的语义分割架构DeepLab-v3,RefineNet-LW的性能表现更具优势。

语义分割结果对比图示:

总结
- 这篇文章的改进非常简单,几乎所有想法都来自于实验摸索出来的。原来通过实验发现现有模型中的计算冗余也很有价值啊!
参考
- [30] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
- [33] Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q. Weinberger. Densely connected convolutional networks. In CVPR, 2017.
- [46] Guosheng Lin, Anton Milan, Chunhua Shen, and Ian D. Reid. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In CVPR, 2017
- [82] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V. Le. Learning transferable architectures for scalable image recognition. CoRR, abs/1707.07012, 2017.
- 新开源!实时语义分割算法Light-Weight RefineNet : https://www.sohu.com/a/258282358_100279313