Hadoop-1.2.1安装与配置
学习hadoop也是有一段时间了,但是都是纸上谈兵,再加上当今云计算工具的不断更新换代,也不知现在的hadoop还能干什么。不过作为基础,拿来作为大数据上手还是可以的。
接着,上一篇文《hadoop》,大致了解了hadoop的起源之后,我们便开始hadoop的安装配置吧。
这次安装配置的前提是,安装的是ubuntu14.04版本系统,不管是用wubi还是硬盘启动,都可以。以下是安装的伪分布式。
可以参考文章:http://www.cnblogs.com/tippoint/archive/2012/10/23/2735532.html
一、准备材料
jdk-7u17-linux-x64.tar.gz
hadoop-1.2.1.tar.gz
eclipse-jee-kepler-SR2-linux-gtk-x86_64.tar.gz
hadoop-eclipse-plugin-1.2.1.jar
二、安装jdk
关于jdk可以到官网下载 http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html ,这里我使用的是jdk-7u17-linux-x64.tar.gz。
1、先把jdk的包放在桌面。按下Ctrl +Alt + T 组合键,打开一个终端。使用cd命令进到/usr/lib/文件夹下面。然后创建一个java文件夹,作为安装jdk的目录。当然,你也可以安装在其他地方,不过这里面,我装在/usr/lib/java/目录下。
cd /usr/lib/
sudo mkdir java
2、接着,我们在打开一个终端,使用cd来到桌面,输入命令将jdk包拷到我们要安装的/usr/lib/java/目录下面。
Cd Desktop
sudo cp jdk-7u17-linux-x64.tar.gz /usr/lib/java
3、将jdk-7u17-linux-x64.tar.gz解压安装在该目录之下
tar -zxcf jdk-7u17-linux-x64.tar.gz
然后就出现一个jdk1.7.0_17文件夹。
`4、这个时候,就该设置java系统变量了。打开/etc/profile文件,添加JAVA_HOME变量。
sudo gedit /etc/profile
然后就会出现如下: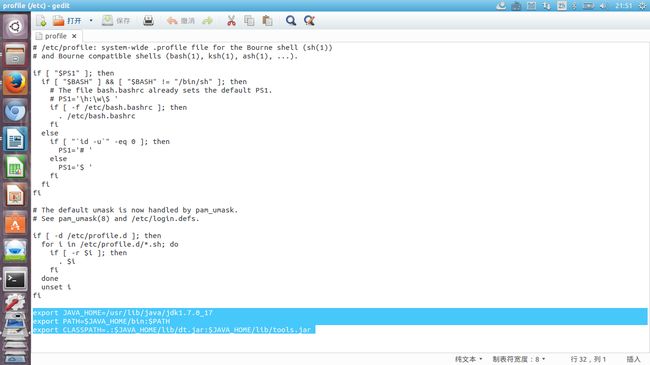
在最后面添加一下字段(注意句号):
export JAVA_HOME=/usr/lib/java/jdk1.7.0_17
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
5、关闭/etc/profile文件之后,使其立即能够被使用
source /etc/profiel
接着,注销用户,重新登录。
6、再一次打开终端,输入:
java -version
java
出现以下输出即可。
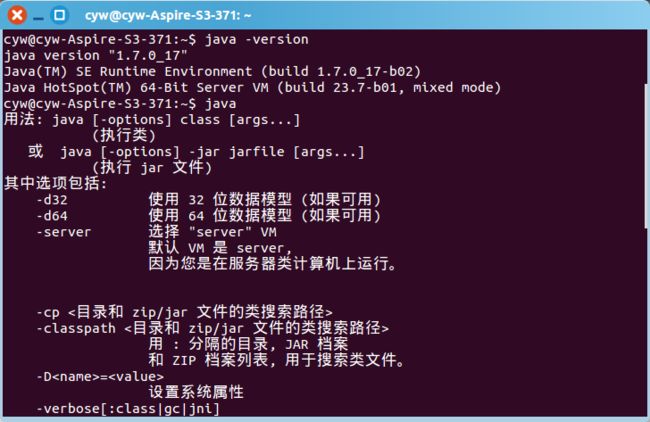
三、安装ssh
sh可以实现远程登录和管理,使hadoop各节点之间通信的桥梁。
1、使用命令行安装ssh
sudo apt-get install ssh
sudo apt-get install rsync
2、实现无密码登录
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
export HADOOP\_PREFIX=/usr/local/hadoop
这是参照官网上面来的。当然你也可以参考前面的链接.
3、登录
ssh localhost
4、退出
exit
四、安装hadoop
1、我们把hadoop-1.2.1.tar.gz放在桌面,把其拷贝到要安装的目录之下,我安装在/home/hadoop/目录下面。
sudo cp hadoop-0.20.203.0rc1.tar.gz /home/hadoop
2、解压安装
cd /home/hadoop/
sudo tar -zxvf hadoop-1.2.1.tar.gz
然后可以得到hadoop-1.2.1文件夹
3、将hadoop-1.2.1文件夹改名为hadoop
mv hadoop-1.2.1 hadoop
4、打开hadoop/conf/hadoop-env.sh文件
sudo gedit hadoop/conf/hadoop-env.sh
配置conf/hadoop-env.sh(找到#export JAVA_HOME=...,去掉#,然后加上本机jdk的路径):
export JAVA_HOME=/usr/lib/java/jdk1.7.0_17
5、打开hadoop/conf/core-site.xml
sudo gedit hadoop/conf/core-site.xml
设置的是namenode节点的ip及其端口号,还有设置hadoop的临时文件,编辑一下内容:(configuration标签里面添加property)
hadoop.tmp.dir
/home/hadoop/hadoop-1.2.1/hadoop_tmp
A base for other temporary directories.
fs.default.name
hdfs://localhost:9000
6、打开hadoop/conf/mapred-site.xml
sudo gedit hadoop/conf/mapred-site.xml
设置的是MapReduce的jobTracker的ip及其端口号,编辑内容如下:
mapred.job.tracker
localhost:9001
7、打开hadoop/conf/hdfs-site.xml
sudo gedit hadoop/conf/hdfs-site.xml
设置namenode、datanode的文件夹,以及replication 表示datanode的数目,编辑如下:
dfs.name.dir
/home/hadoop/hadoop-1.2.1/hadoop_tmp/datalog
dfs.data.dir
/home/hadoop/hadoop-1.2.1/hadoop_tmp/data1
dfs.replication
1
8、打开hadoop/conf/masters,设置的是secondarynamenode的ip地址,因为这是伪分布式,所以添加localhost即可。
Sudo gedit hadoop/conf/masters
9、打开hadoop/conf/slaves,设置的是slaves,即datanode的主机ip地址,一行一个,因为这是伪分布式,所以也是填localhost即可。
Sudo gedit hadoop/conf/slaves
10、进入hadoop文件夹
bin/hadoop
如果输出如下,即说明安装成功(ง •̀_•́)ง: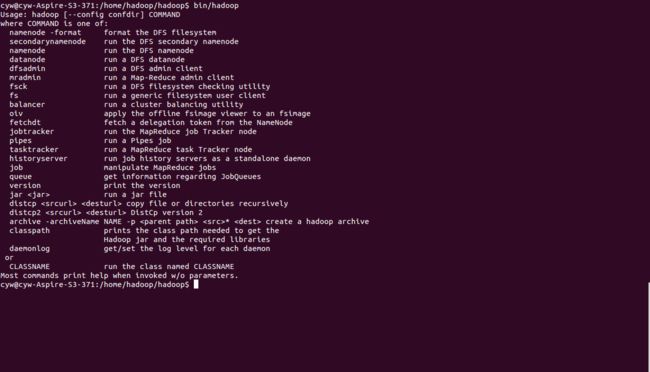
五、运行hadoop
#远程登录
ssh localhost
#初始化nomenode
bin/hadoop nomenode -format
#启动所有节点
bin/start-all.sh
#显示当前进程
jps
如果有Namenode,SecondaryNameNode,TaskTracker,DataNode,JobTracker五个进程,就说明你的hadoop伪分布式环境配置好了!
还可以在浏览器上输入url:
localhost:50030
localhost:50060
localhost:50070
进行管理。
六、安装eclipse插件
这里使用的是eclipse-jee-kepler-SR2-linux-gtk-x86_64.tar.gz、hadoop-eclipse-plugin-1.2.1.jar。注意,hadoop-eclipse-plugin-1.2.1.jar 要与hadoop的版本号一致,不然会出现问题。
1、打开终端,将eclipse-jee-kepler-SR2-linux-gtk-x86_64.tar.gz移到安装目录,这里我安装在/usr/lib/java目录下。
sudo cp eclipse-jee-kepler-SR2-linux-gtk-x86_64.tar.gz /usr/lib/java
解压安装,即可,得到eclipse文件夹:
sudo tar -zxvf eclipse-jee-kepler-SR2-linux-gtk-x86_64.tar.gz
2、进入eclipse文件夹,点击eclipse,即可使用,然后配置eclipse的工作目录workspace,该目录可以任意设置在喜欢的地方。设置之后,即可使用。
3、将 hadoop-eclipse-plugin-1.2.1.jar,放在eclipse文件夹下的plugins文件夹下。然后,重启eclipse。会看到左边project Explorer里面会出现一行图标DFS Locations.
4、然后在Window->Preferences->Hadoop Map/Reduce中添加Hadoop的安装目录。
5、配置hadoop环境:在Window–>Show View中打开Map/Reduce Locations,在底部会看到新的选项。然后右键–>New Hadoop Location。
其中,
Location name:可以填写任意值,表示一个MapReduce Location标识。
Map/Reduce Matser选项组:
Host:localhost(Maters:Hadoop的ip地址)
Port:9001
DFS Master选项组:
Use M/R Master host:勾选该复选框(因为用户的NameNode和JobTracker都在一个机器上面)
Port:9000
User name:hadoop(系统管理员)
这里面的Host、Port分别是mapred-site.xml、core-site.xml中配置的地址以及端口。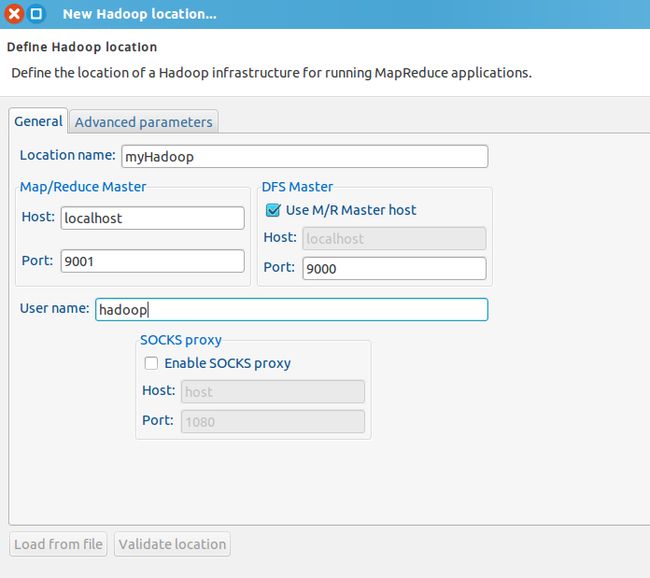
接下来,单击Advanced parameters选项卡中的hadoop.tmp.dir选项,修改为Hadoop集群中设置的地址,Hadoop集群是/home/hadoop/hadoop-1.2.1/hadoop_tmp。这个参数在core-site.xml中进行了设置。如图:
![]()
然后单击finish。
6、然后在下面就会出现如下图标:
7、右边的DFS Locations处。先在终端之中开启hadoop。出现如下: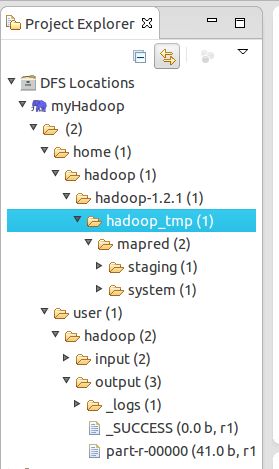
以上,便安装完毕了。如有问题,请指正。
下面是,相关安装包链接:
http://pan.baidu.com/s/1jGuATam
至于关于最新版本的hadoop-2.7.1的安装配置,可参考:
http://zhitongbat.com/?/article/209