常用来作空间划分及近邻搜索,是二叉空间划分树的一个特例。通常,对于维度为k,数据点数为N的数据集,kd树适用于N≫2的k次方的情形。
1维数据的查询
假设在数据库的表格T中存储了学生的语文成绩chinese、数学成绩math、英语成绩english,如果要查询语文成绩介于30~93分的学生,如何处理?假设学生数量为N,如果顺序查询,则其时间复杂度为O(N),当学生规模很大时,其效率显然很低,如果使用平衡二叉树,则其时间复杂度为O(logN),能极大地提高查询效率。平衡二叉树示意图为:

对于1维数据的查询,使用平衡二叉树建立索引即可。如果现在将查询条件变为:语文成绩介于30~93,数学成绩结余30~90,又该如何处理呢?
如果分别使用平衡二叉树对语文成绩和数学成绩建立索引,则需要先在语文成绩中查询得到集合S1,再在数学成绩中查询得到集合S2,然后计算S1和S2的交集,若|S1|=m,|S2|=n,则其时间复杂度为O(m*n),有没有更好的办法呢?
KD树
针对多维数据索引,是否也存在类似的一维的索引方法呢?先看2维数据的集合示意图:
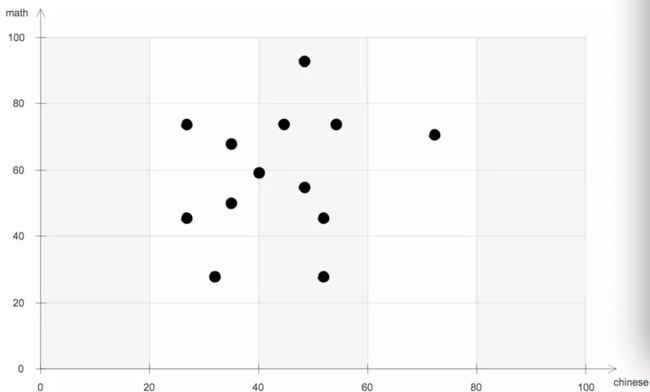
如果先根据语文成绩,将所有人的成绩分成两半,其中一半的语文成绩<=c1,另一半的语文成绩>c1,分别得到集合S1,S2;然后针对S1,根据数学成绩分为两半,其中一半的数学成绩<=m1,另一半的数学成绩>m1,分别得到S3,S4,针对S2,根据数学成绩分为两半,其中一半的数学成绩<=m2,另一半的数学成绩>m2,分别得到S5,S6;再根据语文成绩分别对S3,S4,S5,S6继续执行类似划分得到更小的集合,然后再在更小的集合上根据数学成绩继续,...
上面描述的就是构建KD树的基本思路,其构建后的KD树如下图所示

如图所示,l1左边都是语文成绩低于45分,l1右边都是语文成绩高于45分的;l2下方都是语文成绩低于45分且数学成绩低于50分的,l2上方都是语文成绩低于45分且数学成绩高于50分的,后面以此类推。下面的图示,更清晰地表示了KD树的结构及其对应的二叉树:

树的构建
a)切分维度选择优化
构建开始前,对比数据点在各维度的分布情况,数据点在某一维度坐标值的方差越大分布越分散,方差越小分布越集中。从方差大的维度开始切分可以取得很好的切分效果及平衡性。
b)中值选择优化
第一种,算法开始前,对原始数据点在所有维度进行一次排序,存储下来,然后在后续的中值选择中,无须每次都对其子集进行排序,提升了性能。
第二种,从原始数据点中随机选择固定数目的点,然后对其进行排序,每次从这些样本点中取中值,来作为分割超平面。该方式在实践中被证明可以取得很好性能及很好的平衡性。
本文采用常规的构建方式,以二维平面点(x,y)的集合(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)为例结合下图来说明k-d tree的构建过程。
a)构建根节点时,此时的切分维度为x,如上点集合在x维从小到大排序为(2,3),(4,7),(5,4),(7,2),(8,1),(9,6);其中值为(7,2)。(注:2,4,5,7,8,9在数学中的中值为(5 + 7)/2=6,但因该算法的中值需在点集合之内,所以本文中值计算用的是len(points)//2=3, points[3]=(7,2))
b)(2,3),(4,7),(5,4)挂在(7,2)节点的左子树,(8,1),(9,6)挂在(7,2)节点的右子树。
c)构建(7,2)节点的左子树时,点集合(2,3),(4,7),(5,4)此时的切分维度为y,中值为(5,4)作为分割平面,(2,3)挂在其左子树,(4,7)挂在其右子树。
d)构建(7,2)节点的右子树时,点集合(8,1),(9,6)此时的切分维度也为y,中值为(9,6)作为分割平面,(8,1)挂在其左子树。至此k-d tree构建完成。
