golang解析xml神器etree
Golang原生的encoding/xml
原生的encoding/xml库中的Unmarshal函数可以解析xml格式的信息
但往往需要我们需要先定义相应的结构体,如果xml结构复杂,我们还需要定义多个结构体。这在解析一些多层嵌套xml中显得非常被动
例:
AdminServer
10.1.0.10
App
10.1.0.11
type Recurlyservers struct {
XMLName xml.Name `xml:"Weblogic"`
Version string `xml:"version,attr"`
Svs []server `xml:"server"`
Description string `xml:",innerxml"`
}
type server struct {
XMLName xml.Name `xml:"server"`
ServerName string `xml:"serverName"`
ServerIP string `xml:"serverIP"`
}
func main() {
file, err := os.Open("servers.xml") // For read access.
if err != nil {
fmt.Printf("error: %v", err)
return
}
defer file.Close()
data, err := ioutil.ReadAll(file)
if err != nil {
fmt.Printf("error: %v", err)
return
}
v := Recurlyservers{}
err = xml.Unmarshal(data, &v)
if err != nil {
fmt.Printf("error: %v", err)
return
}
fmt.Println(v)
}
像上面这样结构较为简单的还好,但遇到像下面这种(WAS RESTApi)返回信息
xml view:

其复杂程度可见一斑。
于是我想应该有类似gabs解析JSON串那样灵活的轮子
果然github上有这么一个还算不错的轮子 etree
可以动态解析xml,拿到你想要的结果,而且不需要定义相应的结构体。
让我们回到第一个例子里面
我们需要拿到weblogic中的第一个服务器的服务器名:
func main() {
// 初始化根节点
doc := etree.NewDocument()
if err := doc.ReadFromFile("node.xml"); err != nil {
panic(err)
}
root := doc.SelectElement("Weblogic")
res := root.FindElement("./server[0]/serverName").Text()
fmt.Println(res)
}
FindElement(“支持X-path”)
官方demo:
doc := etree.NewDocument()
if err := doc.ReadFromFile("test.xml"); err != nil {
panic(err)
}
root := doc.SelectElement("Weblogic") // 首先获取最外层作为根节点
下面介绍一些匹配常用的函数:
- FindElement(path)
我们先来看说明
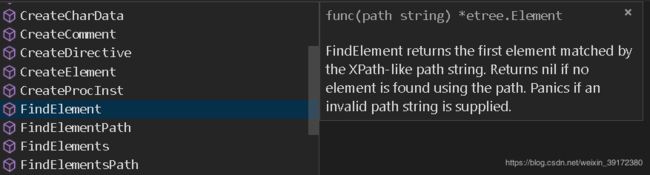
FindElement方法支持X-path搜索,几乎可以匹配任何满足条件的标签。
2 FindElementPath与前者类似,但路径有误时不会panic

注意这里获取到目标节点后并没有获取到真正的标签内容。函数返回的还是一个*etree.Element类型。如果我们需要拿到标签中的内容需要Text方法

就像我们在之前的用例中那样:
res := root.FindElement("./server[0]/serverName").Text()
获取到string类型结果
如果你不确定该标签最多只有一个的话
可以用FindElements方法

3 FindElementsPath的区别与前面FindElementPath一样,不再赘述。
4 SelectElement方法也是搜索子节点,但是仅限于搜索孩子节点

返回结果同样是*etree.Element类型
5 SelectElements返回节点列表,我们可以拿来遍历
servers := root.SelectElement("servers")
for _, server := range servers.SelectElements("server") {
fmt.Println(server.SelectElement("serverName").Text())
}
结果
AdminServer
App
以下为官方README
etree
The etree package is a lightweight, pure go package that expresses XML in
the form of an element tree. Its design was inspired by the Python
ElementTree
module. Some of the package’s features include:
- Represents XML documents as trees of elements for easy traversal.
- Imports, serializes, modifies or creates XML documents from scratch.
- Writes and reads XML to/from files, byte slices, strings and io interfaces.
- Performs simple or complex searches with lightweight XPath-like query APIs.
- Auto-indents XML using spaces or tabs for better readability.
- Implemented in pure go; depends only on standard go libraries.
- Built on top of the go encoding/xml
package.
Creating an XML document
The following example creates an XML document from scratch using the etree
package and outputs its indented contents to stdout.
doc := etree.NewDocument()
doc.CreateProcInst("xml", `version="1.0" encoding="UTF-8"`)
doc.CreateProcInst("xml-stylesheet", `type="text/xsl" href="style.xsl"`)
people := doc.CreateElement("People")
people.CreateComment("These are all known people")
jon := people.CreateElement("Person")
jon.CreateAttr("name", "Jon")
sally := people.CreateElement("Person")
sally.CreateAttr("name", "Sally")
doc.Indent(2)
doc.WriteTo(os.Stdout)
Output:
<People>
<Person name="Jon"/>
<Person name="Sally"/>
People>
Reading an XML file
Suppose you have a file on disk called bookstore.xml containing the
following data:
<bookstore xmlns:p="urn:schemas-books-com:prices">
<book category="COOKING">
<title lang="en">Everyday Italiantitle>
<author>Giada De Laurentiisauthor>
<year>2005year>
<p:price>30.00p:price>
book>
<book category="CHILDREN">
<title lang="en">Harry Pottertitle>
<author>J K. Rowlingauthor>
<year>2005year>
<p:price>29.99p:price>
book>
<book category="WEB">
<title lang="en">XQuery Kick Starttitle>
<author>James McGovernauthor>
<author>Per Bothnerauthor>
<author>Kurt Cagleauthor>
<author>James Linnauthor>
<author>Vaidyanathan Nagarajanauthor>
<year>2003year>
<p:price>49.99p:price>
book>
<book category="WEB">
<title lang="en">Learning XMLtitle>
<author>Erik T. Rayauthor>
<year>2003year>
<p:price>39.95p:price>
book>
bookstore>
This code reads the file’s contents into an etree document.
doc := etree.NewDocument()
if err := doc.ReadFromFile("bookstore.xml"); err != nil {
panic(err)
}
You can also read XML from a string, a byte slice, or an io.Reader.
Processing elements and attributes
This example illustrates several ways to access elements and attributes using
etree selection queries.
root := doc.SelectElement("bookstore")
fmt.Println("ROOT element:", root.Tag)
for _, book := range root.SelectElements("book") {
fmt.Println("CHILD element:", book.Tag)
if title := book.SelectElement("title"); title != nil {
lang := title.SelectAttrValue("lang", "unknown")
fmt.Printf(" TITLE: %s (%s)\n", title.Text(), lang)
}
for _, attr := range book.Attr {
fmt.Printf(" ATTR: %s=%s\n", attr.Key, attr.Value)
}
}
Output:
ROOT element: bookstore
CHILD element: book
TITLE: Everyday Italian (en)
ATTR: category=COOKING
CHILD element: book
TITLE: Harry Potter (en)
ATTR: category=CHILDREN
CHILD element: book
TITLE: XQuery Kick Start (en)
ATTR: category=WEB
CHILD element: book
TITLE: Learning XML (en)
ATTR: category=WEB
Path queries
This example uses etree’s path functions to select all book titles that fall
into the category of ‘WEB’. The double-slash prefix in the path causes the
search for book elements to occur recursively; book elements may appear at any
level of the XML hierarchy.
for _, t := range doc.FindElements("//book[@category='WEB']/title") {
fmt.Println("Title:", t.Text())
}
Output:
Title: XQuery Kick Start
Title: Learning XML
This example finds the first book element under the root bookstore element and
outputs the tag and text of each of its child elements.
for _, e := range doc.FindElements("./bookstore/book[1]/*") {
fmt.Printf("%s: %s\n", e.Tag, e.Text())
}
Output:
title: Everyday Italian
author: Giada De Laurentiis
year: 2005
price: 30.00
This example finds all books with a price of 49.99 and outputs their titles.
path := etree.MustCompilePath("./bookstore/book[p:price='49.99']/title")
for _, e := range doc.FindElementsPath(path) {
fmt.Println(e.Text())
}
Output:
XQuery Kick Start
Note that this example uses the FindElementsPath function, which takes as an
argument a pre-compiled path object. Use precompiled paths when you plan to
search with the same path more than once.
Other features
These are just a few examples of the things the etree package can do. See the
documentation for a complete
description of its capabilities.
Contributing
This project accepts contributions. Just fork the repo and submit a pull
request!
更详细用法见文档https://godoc.org/github.com/beevik/etree