基于内容的图像检索技术(3):部分论文阅读总结
[1] Ng Y H , Yang F , Davis L S . Exploiting Local Features from Deep Networks for Image Retrieval[J]. 2015.
传统的VLAD算法从sift特征中进行计算,这篇文章从卷积网络中进行提取特征,然后使用vlad方法。除此之外,文章有两个贡献 (1)从不同层中提取卷积特征,并采用VLAD将特征编码为每一个图像的单个矢量。 (2)使用了两个OxfordNet和GoogleNet研究输入图像的不同层和尺度对卷积性能的影响。实验表明,与之后一层提取特征相比,前面的层可能产生更好的检索结果。
[2] Arandjelovic R , Gronat P , Torii A , et al. NetVLAD: CNN architecture for weakly supervised place recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017:1-1.
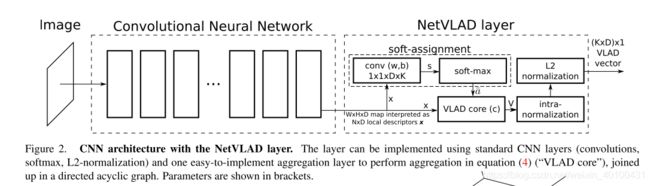
本文是进行图像地点检索,其主要是将VLAD的计算方式纳入到了深度网络之中(通过典型深度网络层,例如softmax层,卷积层,正则化就能将vlad实现),形成一个端到端的网络,其通过数学方式将VLAD与卷积网络结合,形成网络的一个中间层,损失函数使用了图像检索中常常使用的triplet loss,是一篇很优秀的文章。
[3] Liu H , Tian Y , Wang Y , et al. Deep Relative Distance Learning: Tell the Difference between Similar Vehicles[C]// Computer Vision & Pattern Recognition. IEEE, 2016.
本文中作者的主要做了两方面的改进:
(1)原始的三元组损失函数如果锚点的选择不合适,将会对网络训练产生极大的干扰,使得网络收敛速度变慢,并且需要更多的样本去修正它,因此作者提出一种新的coupled Cluster loss函数。其将单个样本的输入改变为一组正的或者负的样本输入。在锚点选择上,使用正的样本特征的“平均中心点”作为锚点。选择距离锚点最近的负样本进行欧式距离计算。其他的与原始的triple loss一致。
这样做相对于三元组损失的好处是可以得到更为稳定的样本移动方向,并且保证了所有不接近中心的正样本将更加靠近,已经接近的被忽略。
(2)融合的差异性网络架构 该网络属于多任务训练网络,其包含两个部分,一个是判断是否属于同一种汽车型号,另外一个是判断是否属于同一个类型。并将这两个部分的输出进行融合,得到一个加强版的是否属于同一类型的结果检索结果。
[4] SIFT Meets CNN: A Decade Survey of Instance Retrieval[J].2018
中文翻译:
https://www.jianshu.com/p/ebf6fbdb44e9
https://www.jianshu.com/p/cda7aec5ff0c
万字长文,介绍图像检索十年的发展
图像检索中用于预训练的两个数据集:ImageNet和PASES-205(一个以场景为主的数据集,描绘了各种室内场景和室外场景)以及HybridNet。
迁移问题:不同的层提取出特征具有不同的检索性能。高层网络的泛化能力低于低层网络。原始的训练集不同也会影响模型的准确率。
之前的研究方法侧重于在全连接层进行特征提取,其具有全局表示性,在欧式距离下具有较好的检索精度,并且可以通过指数归一化提高检索精度。
新的一些研究侧重于中间局部的描述符。其对于诸如截断和遮挡更具有鲁棒性。对局部描述符使用局部不变量检测器。
将描述符聚合为全局表示。可以通过两种方式,其一是使用编码方法,例如,VLAD与FV,其二是直接池化。
ps :在中间特征映射上采用最大或平均池化,其中Razavian等人的《Visual instance retrieval with deep convolutional networks》是打开先河的工作。同时大家也发现最后一层卷积层(如VGGNet的pool5)在池化后达到的准确率要高于FC描述符描述符以及其他卷积层。
Learning visual similarity for product design with convolutional neural networks 采用了基于AlexNet的孪生网络和对比损失函数
在《Faster r-cnn features for instance search》中使用区域建议网络(RPN)来对目标进行定位。
[5] Gordo A , Almazan J , Revaud J , et al. Deep Image Retrieval: Learning global representations for image search[J]. 2016.
这篇文章除了进行检索以外,还提供了检索实例的定位功能。
[6] Lin K , Yang H F , Hsiao J H , et al. Deep learning of binary hash codes for fast image retrieval[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2015.
这篇文章并非图像的实例型检索,而是图像的类别检索,其主要包括两个部分,一个是网络结构的构造,另外一个是使用粗检索与细检索结合的方式。具体如下:
(1)其使用的CNN网络最后两层为全连接层,用F7和F8表示,整个网络在imagenet上进行预训练。在两个全连接层之间加入一个隐层,其激活函数使用sigmoid函数,这样在最后的输出层就变成了(0,1)之间的表示,最后在通过设定阈值组成哈希编码(就是转变成了使用二进制编码表示图像类别)
(2)粗检索使用汉明距离(汉明距离指的是两个二进制数中不相同位的数量)进行检索图像,设定一个距离阈值,当小于这个阈值的时候,被纳入到细致的待检测环节中。在细致的检索中,使用FC7层进行新的特征,以及欧式距离进行进一步的检索。
原文给出了caffe的实现,这里是pytorch的实现:https://github.com/flyingpot/pytorch_deephash
[7] Radenović, Filip, Iscen A , Tolias G , et al. Revisiting Oxford and Paris: Large-Scale Image Retrieval Benchmarking[J]. 2018.
这是较新的一篇CVPR论文,其对比了目前的图像检索相关方法,并且对图像检索的周边(例如,数据集,评估方法等)做了一些新的调整。也是一篇综述,论文中对相关图像检索方法进行评估【8】仍然被认为是当前最优秀的方法。
[8] Noh H , Araujo A , Sim J , et al. Large-Scale Image Retrieval with Attentive Deep Local Features[C]// 2017 IEEE International Conference on Computer Vision (ICCV). IEEE Computer Society, 2017.
这篇文章提出了一种DELF的方法,可以通过tensorflow进行安装DELF包,其在2018年的论文[7]中被认为是目前最好的基于内容的图像检索方法。这里捋一下论文思路,具体内容还需要看论文。

前面一篇文章中已经说过,图像检索核心方法分为特征提取与特征搜索。上图的左边的图像是特征提取方法,右边是图像检索方法。首先看一下特征提取方法,
- 使用在ImageNet上预训练好的resnet50网络
- 在地标数据集上微调网络,之后保留resnet50的conv4_x作为局部稠密特征
- 之后使用注意力集中网络提取关键特征,上图中黄色区域是注意力网络,提取出稀疏的局部特征
- 使用维度约(L2正则化,PCA降维等)得到由特征点(数量不固定)与特征描述符组成的图像特征。每一个特征点由一个40维的向量组成
接下来是查询方法
- 首先生成图像的特征,通过k-d数进行与特征点匹配。
- 匹配完成后,在通过ransac算法进行几何约束,进一步优化匹配点。
- 得到图像的匹配结果,以及匹配点个数。
[9] Arandjelovic R . Three things everyone should know to improve object retrieval[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2012.
这是一篇较早的文章,因为前期的图像实例检索主要使用的是sift特征,并且当时深度网络的检索效果不如传统的sift特征,所以这里对shift进行了改进,是一篇比较经典的方法。
这篇文章的贡献有三点
(1)没有增加处理和存储需要且相对于SIFT效果更好的RootSIFT被提出。其通过平方根内核(square root kernel)代替标准的欧氏距离去测量SIFT特征的相似性。
(2)一种新的扩展查询方法,其中以适合通过有效使用倒排索引立即检索的形式区别地学习查询的更丰富的模型;用于查询扩展的当前方法组合了空间验证结果的BoW向量,例如, 通过平均,实验表明,使用线性SVM来区别地学习用于重新查询的权重向量,与标准平均查询扩展方法相比产生了显着的改进[6],同时通过有效使用倒排索引保持了立即检索速度。
(3)一个更加完善的图像增强模型被提出。 论文[29]中的数据库端功能增强功能非常强大,但不考虑增强功能的空间配置。文章表明,如果考虑增强特征的可见性(使用单应性的空间验证),那么与原始方法相比,这种简单的扩展提供了显着的性能改进。