from scratch implement crnn using pytorch :读取训练数据
知识点:
-
python特殊函数 __call__() 实现类变成一个可调用对象
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
def __call__(self, friend):
print 'My name is %s...' % self.name
print 'My friend is %s...' % friend
现在可以对 Person 实例直接调用:
>>> p = Person('Bob', 'male')
>>> p('Tim')
My name is Bob...
My friend is Tim...
单看 p('Tim') 你无法确定 p 是一个函数还是一个类实例,所以,在Python中,函数也是对象,对象和函数的区别并不显著-
opencv中图像的坐标

pyopencv 函数 def resize(src, dsize, dst=None, fx=None, fy=None, interpolation=None): 故参数dsize输入格式应该是(width,height)
-
torch.nn.ReLU(inplace=True)中inplace的作用
在文档中解释是:
参数: inplace-选择是否进行覆盖运算
意思是是否将得到的值计算得到的值覆盖之前的值,比如:x = x +1即对原值进行操作,然后将得到的值又直接复制到该值中,而不是覆盖运算的例子如:y = x + 1x = y这样就需要花费内存去多存储一个变量y,所以nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True)
意思就是对从上层网络Conv2d中传递下来的tensor直接进行修改,这样能够节省运算内存,不用多存储其他变量
-
各个深度框架读入图像的顺序
N: batch;
C: channel
H: height
W: width
Caffe 的Blob通道顺序是:NCHW;
Tensorflow的tensor通道顺序:默认是NHWC, 也支持NCHW,使用cuDNN会更快;
Pytorch中tensor的通道顺序:NCHW
TensorRT中的tensor 通道顺序: NCHW
-
pytorch加载数据
常用到的工具有 torchvision 里的 transforms
torch.utils.data 里的 Dataset,DataLoaderdataloader本质是一个可迭代对象,使用iter()访问,不能使用next()访问;
使用iter(dataloader)返回的是一个迭代器,然后可以使用next访问;
也可以使用`for inputs, labels in dataloaders`进行可迭代对象的访问;
一般我们实现一个datasets对象,传入到dataloader中;然后内部使用yeild返回每一次batch的数据
Dataloader的处理逻辑是先通过Dataset类里面的 __getitem__ 函数获取单个的数据,然后组合成batch。使用上主要是重构dataset,必须继承自torch.utils.data.Dataset,内部要实现两个函数一个是__lent__用来获取整个数据集的大小,一个是__getitem__用来从数据集中得到一个数据片段item。
- SyntheticChineseStringDataset
该数据集是中文识别数据集,包含360多万张训练图片,5824个字符,场景比较简单,图片是白底黑字
图片:
![]()
![]()
![]()
标签:前一部分为图像名称,后一部分数字为图片上字符对应的字符编码
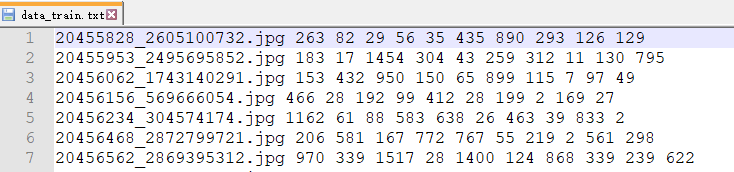
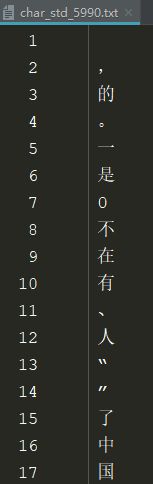
字符编码:char_std_5990.txt
- 使用pytorch读取SyntheticChineseStringDataset 数据集:
import torch
import os
import cv2
from torchvision import transforms
from torch.utils.data import Dataset,DataLoader
def readfile(fileName):
res = []
with open(fileName,'r') as f:
lines = f.readlines()
for line in lines:
res.append(line.strip())
dic = {}
for line in res:
part = line.split(' ')
dic[part[0]] = part[1:]
return dic
# 调整图像大小和归一化操作
class resizeAndNormalize():
def __init__(self,size,interpolation=cv2.INTER_LINEAR):
# 注意对于opencv,size的格式是(w,h)
self.size = size
self.interpolation = interpolation
# ToTensor属于类 """Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
self.toTensor = transforms.ToTensor()
def __call__(self, image):
# (x,y) 对于opencv来说,图像宽对应x轴,高对应y轴
image = cv2.resize(image,self.size,interpolation=self.interpolation)
#转为tensor的数据结构
image = self.toTensor(image)
#对图像进行归一化操作
image = image.sub_(0.5).div_(0.5)
return image
class CRNNDataSet(Dataset):
def __init__(self,imageRoot,labelRoot):
self.image_root = imageRoot
self.image_dict = readfile(labelRoot)
self.image_name = [fileName for fileName,_ in self.image_dict.items()]
def __getitem__(self, index):
image_path = os.path.join(self.image_root,self.image_name[index])
keys = self.image_dict.get(self.image_name[index])
label = [int(x) for x in keys]
image = cv2.imread(image_path,cv2.IMREAD_GRAYSCALE)
(height,width) = image.shape
#由于crnn网络输入图像的高为32,故需要resize原始图像的height
size_height = 32
ratio = 32/float(height)
size_width = int(ratio * width)
transform = resizeAndNormalize((size_width,size_height))
#图像预处理
image = transform(image)
#标签格式转换为IntTensor
label = torch.IntTensor(label)
return image,label
def __len__(self):
return len(self.image_name)
trainData = CRNNDataSet(imageRoot="D:\BaiduNetdiskDownload\Synthetic_Chinese_String_Dataset\images\\",
labelRoot="D:\BaiduNetdiskDownload\Synthetic_Chinese_String_Dataset\lables\data_train.txt")
trainLoader = DataLoader(dataset=trainData,batch_size=1,shuffle=True)
for i,(data,label) in enumerate(trainLoader):
print(i)
print(data.shape)
print(label)