Caffe代码理解-卷积层conv_layer
带下采样的卷积
输入图像X+ 卷积核 K ->卷积操作->输出特征图Y
其中,输入图像和输出特征图都是三维张量,卷积核是四维张量。![]() (1)
(1)
CNN里的卷积不是信号处理里严格的卷积。卷积核是可以不翻转的,《深度学习》书里把互相关和卷积统称为卷积。
直观来讲,卷积可以视为一种局部的线性回归。
i输出特征图通道,jk输出特征图上坐标,l输入图像通道,s步幅,b偏置标量。
输出特征图Y上的元素Y_ijk,对应输入图像X上的一个block,block的左上角左边为[(j-1)s, (k-1)s],宽高为卷积核尺寸,即m/n的最大值。
该block与卷积核做点积,即为Y_ijk的值。所以其实还是个局部线性回归,所谓的参数共享其实就是各个位置的回归权重参数相同,不用每个位置都用一个权重矩阵。
由于图像和特征图是多通道的,所以Y_ijk的计算涉及了多通道上的同一block。
步幅s代表了采样间隔,如果s>1,可视为下采样。
Caffe中矩阵形式的卷积运算
还是要用这张经典的图示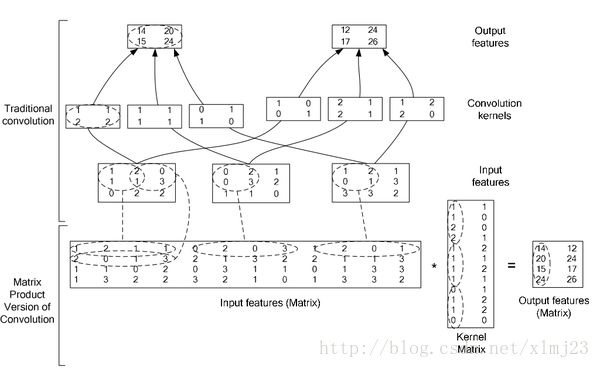
为了加速运算,用空间换时间。
利用im2col函数把多通道输入图像整理为一个单通道矩阵,为什么叫im2col,因为相当于图像中的每一个block都被拉伸为一个column,由于输入是多通道的,所以每个block对应三个串在一起的columns。
如图例所示,input feature matrix的每一行都包含了第一个block的三通道的columns的转置。总共有四行,是因为有四个block参与,即卷积在4个位置上进行了运算。
多通道的卷积核,也是被整理为一个Kernel matrix,每一列由三通道kernel展开成的colums串在一起形成。总共有两列是因为输出是2通道的。
所以,卷积运算就可以表达为矩阵相乘的形式,GEMM (general matrix multiply)![]() (2)
(2)
这里的输入特征图已经是有冗余的了,但是计算更快。
Caffe中conv_layer
由BaseConvolutionLayer继承而来,主要看一下forward和backward计算。
前向计算,由bottom计算top
void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { const Dtype* weight = this->blobs_[0]->cpu_data(); for (int i = 0; i < bottom.size(); ++i) { const Dtype* bottom_data = bottom[i]->cpu_data(); Dtype* top_data = top[i]->mutable_cpu_data(); for (int n = 0; n < this->num_; ++n) {//num_ is batch_size this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight, top_data + n * this->top_dim_); if (this->bias_term_) { const Dtype* bias = this->blobs_[1]->cpu_data(); this->forward_cpu_bias(top_data + n * this->top_dim_, bias); } } } }1. forward_cpu_gemm: 针对batch中的每张图像,调用基类的函数 forward_cpu_gemm,该函数其实先用im2col把输入转换为
multiplier
col_buffer_,然后进行矩阵相乘,caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ / group_, conv_out_spatial_dim_, kernel_dim_, (Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g, (Dtype)0., output + output_offset_ * g);即weights*col_buffer_=output。这里的weights应该是公式(2)中W的转置, col_buffer_是x的转置,output是Y的转置。
2. foward_cpu_bias: 即 bias*全1矩阵bias_multiplier+output -> output。其中,bias是长度为输出特征图通道数的向量,也就是每一个通道对应一个偏置标量。bias_multiplier是长度为输出特征图尺寸的向量的转置,bias与其相乘后便成为一个每一列元素是一个通道偏置的矩阵。
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num_output_, out_spatial_dim_, 1, (Dtype)1., bias, bias_multiplier_.cpu_data(), (Dtype)1., output);
反向计算,由top计算bottom_diff, weight_diff, bias_diff
void ConvolutionLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) { const Dtype* weight = this->blobs_[0]->cpu_data();//weight belong to this layer Dtype* weight_diff = this->blobs_[0]->mutable_cpu_diff();//to be updated for (int i = 0; i < top.size(); ++i) { const Dtype* top_diff = top[i]->cpu_diff();//propagated from upper layer const Dtype* bottom_data = bottom[i]->cpu_data(); Dtype* bottom_diff = bottom[i]->mutable_cpu_diff();//to be updated // Bias gradient, if necessary. Accumulate diffs in a batch if (this->bias_term_ && this->param_propagate_down_[1]) { Dtype* bias_diff = this->blobs_[1]->mutable_cpu_diff(); for (int n = 0; n < this->num_; ++n) { this->backward_cpu_bias(bias_diff, top_diff + n * this->top_dim_); } } if (this->param_propagate_down_[0] || propagate_down[i]) { for (int n = 0; n < this->num_; ++n) { // gradient w.r.t. weight. Note that we will accumulate diffs in a batch. if (this->param_propagate_down_[0]) { this->weight_cpu_gemm(bottom_data + n * this->bottom_dim_, top_diff + n * this->top_dim_, weight_diff); } // gradient w.r.t. bottom data, if necessary. if (propagate_down[i]) { this->backward_cpu_gemm(top_diff + n * this->top_dim_, weight, bottom_diff + n * this->bottom_dim_); } } } } }计算偏置的偏导数: bias_diff = top_diff*bias_multiplier_+bias_diff,注意最后还加了bias_diff,说明计算bias梯度时,累加了batch中的各个图像所产生的结果。 每一个通道中的top_diff累加,得到该通道中的偏置的导数。
void BaseConvolutionLayer<Dtype>::backward_cpu_bias(Dtype* bias, const Dtype* input) { caffe_cpu_gemv<Dtype>(CblasNoTrans, num_output_, out_spatial_dim_, 1., input, bias_multiplier_.cpu_data(), 1., bias); }计算权重的梯度:weights=top_diff*col_buff.transpose()+weights。注意,1,权重的梯度也是由一个batch累加的。2,这里的weights是公式(2)的转置,所以上一行的公式其实是W=X.transpose*dY的转置
void BaseConvolutionLayer<Dtype>::weight_cpu_gemm(const Dtype* input, const Dtype* output, Dtype* weights) { const Dtype* col_buff = input; if (!is_1x1_) { conv_im2col_cpu(input, col_buffer_.mutable_cpu_data()); col_buff = col_buffer_.cpu_data(); } for (int g = 0; g < group_; ++g) { caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, conv_out_channels_ / group_, kernel_dim_, conv_out_spatial_dim_, (Dtype)1., output + output_offset_ * g, col_buff + col_offset_ * g, (Dtype)1., weights + weight_offset_ * g); } }计算输入数据的梯度: bottom_diff = weights.transpose()*top_diff。完成一次反传
void BaseConvolutionLayer<Dtype>::backward_cpu_gemm(const Dtype* output, const Dtype* weights, Dtype* input) { Dtype* col_buff = col_buffer_.mutable_cpu_data(); if (is_1x1_) { col_buff = input; } for (int g = 0; g < group_; ++g) { caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, kernel_dim_, conv_out_spatial_dim_, conv_out_channels_ / group_, (Dtype)1., weights + weight_offset_ * g, output + output_offset_ * g, (Dtype)0., col_buff + col_offset_ * g); } if (!is_1x1_) { conv_col2im_cpu(col_buff, input); } }