TensorFlow中batch norm原理,使用事项与踩坑
一、机器学习领域有个重要假设:独立同分布independent and identically distributed (i.i.d.)
- 在概率统计理论中,指随机过程中,任何时刻的取值都为随机变量,如果这些随机变量服从同一分布,并且互相独立,那么这些随机变量是独立同分布。如果随机变量X1和X2独立,是指X1的取值不影响X2的取值,X2的取值也不影响X1的取值且随机变量X1和X2服从同一分布,这意味着X1和X2具有相同的分布形状和相同的分布参数,对离随机变量具有相同的分布律,对连续随机变量具有相同的概率密度函数,有着相同的分布函数,相同的期望、方差。如实验条件保持不变,一系列的抛硬币的正反面结果是独立同分布。
- 关于独立同分布,西瓜书这样解释道:输入空间
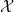 中的所有样本服从一个隐含未知的分布,训练数据所有样本都是独立地从这个分布上采样而得。
中的所有样本服从一个隐含未知的分布,训练数据所有样本都是独立地从这个分布上采样而得。 - 好了,那为啥非要有这个假设呢?我们知道,机器学习就是利用当前获取到的信息(或数据)进行训练学习,用以对未来的数据进行预测、模拟。所以都是建立在历史数据之上,采用模型去拟合未来的数据。因此需要我们使用的历史数据具有总体的代表性。
- 为什么要有总体代表性?我们要从已有的数据(经验) 中总结出规律来对未知数据做决策,如果获取训练数据是不具有总体代表性的,就是特例的情况,那规律就会总结得不好或是错误,因为这些规律是由个例推算的,不具有推广的效果。通过独立同分布的假设,就可以大大减小训练样本中个例的情形。机器学习并不总是要求数据同分布。在不少问题中要求样本(数据)采样自同一个分布是因为希望用训练数据集训练得到的模型可以合理用于测试集,使用同分布假设能够使得这个做法解释得通。由于现在的机器学习方向的内容已经变得比较广,存在不少机器学习问题并不要求样本同分布,比如一些发表在机器学习方向上的online算法就对数据分布没啥要求,关心的性质也非泛化性。
二、Batch Normalization原理
- 动机:神经网络在训练过程中,随着深度加深,输入值分布会发生偏移,向取值区间上下两端靠近,如Sigmoid函数,就会导致反向传播时低层神经网络的梯度消失,这是深层网络收敛越来越慢的重要原因;神经网络随着深度加深,训练变得困难。relu激活函数, 残差网络,BN层都是解决梯度消失等由于深度带来的问题。
- BN概念:传统的神经网络,只是在将样本x输入输入层之前对x进行标准化处理,以降低样本间的差异性。BN是在此基础上,不仅仅只对输入层的输入数据x进行标准化,还对每个隐藏层的输入进行标准化。(那为什么需要对每个隐藏层的输入进行标准化呢?或者说这样做有什么好处呢?这就牵涉到一个Covariate Shift问题)
- Covariate Shift(平移不变性):Convariate shift是BN论文作者提出来的概念,指的是具有不同分布的输入值对深度网络学习的影响。当神经网络的输入值的分布不同是,我们可以理解为输入特征值的scale差异较大,与权重进行矩阵相乘后,会产生一些偏离较大地差异值;而深度学习网络需要通过训练不断更新完善,那么差异值产生的些许变化都会深深影响后层,偏离越大表现越为明显;因此,对于反向传播来说,这些现象都会导致梯度发散,从而需要更多的训练步骤来抵消scale不同带来的影响,也就是说,这种分布不一致将减缓训练速度。
- BN的作用:主要两方面: 缓解DNN训练中的梯度消失问题与 加快模型的训练速度;就是将这些输入值进行标准化,降低scale的差异至同一个范围内。这样做的好处在于一方面提高梯度的收敛程度,加快模型的训练速度;另一方面使得每一层可以尽量面对同一特征分布的输入值,减少了变化带来的不确定性,也降低了对后层网路的影响,各层网路变得相对独立,缓解了训练中的梯度消失问题。
三、Tensorflow中BN使用方法
BN层的设定一般是按照conv->bn->relu的顺序来形成一个block,在 TensorFlow 中,Batch Normlization 有以下几个实现(API):
tf.layers.BatchNormalization
tf.layers.batch_normalization
tf.keras.layers.BatchNormalization
tf.nn.batch_normalization
上述四个 API 按层次可分为两类:
高阶 API:tf.layers.BatchNormalization、tf.layers.batch_normalization、tf.keras.layers.BatchNormalization
低阶 API:tf.nn.batch_normalization
上述四个 API 按行为可以分为两类:
TensorFlow API:tf.layers.BatchNormalization、tf.layers.batch_normalization、tf.nn.batch_normalization
Keras API:tf.keras.layers.BatchNormalization
- TensorFlow中batch norm踩坑
- 头号大坑
当is_training = True时,意味着创建Update ops,利用当前batch的均值和方差去更新moving averages(即某层累计的平均均值和方差)。这里提供两种方式创建update_ops,一是自己显式的创建update_ops,手动更新。update_ops默认放置在tf.GraphKeys.UPDATE_OPS中,因此这里在执行train_ops的同时更新均值方差即可,对于单卡来说很容易理解,对于多卡来说,相当于collection所有卡的batch的均值方差后统一更新,也可以只collection第一块卡的均值方差(理论上需要积累其他卡,但是由于这操作积累得很快,所以只取第一块卡也不影响性能,在TensorFlow高阶API的样例代码cifar10_main.py中如是说)。代码如下:
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):#保证train_op在update_ops执行之后再执行。
train_op = optimizer.minimize(loss)或者
update_ops = tf.group(*tf.get_collection(tf.GraphKeys.UPDATE_OPS))
train_op = tf.group(train_op, update_ops)二是自动的更新, 只需在初始化前 bn = BatchNorm(update_ops_collection=None)即可。不过这种方式下,会在完成更新前阻塞网络的forward,因此会带来时间上的成本。具体而言,这时bn的参数mean,var是立即更新的,也是计算完当前layer的mean,var就更新,然后进行下一个layer的操作。这在单卡下没有问题的, 但是多卡情况下就会写等读的冲突,因为可能存在GPU0更新(写)mean但此时GPU1还没有计算到该层,所以GPU0就要等GPU1读完mean才能写。
- 第二大坑--BN层模型pb转化为tflite时
若代码通过创建输入标志位来判断BN层是否训练,代码形式如下:
# 定义模型的输入输出
x = tf.placeholder(dtype=tf.float32, shape=[None, height, width, 3], name='input') # 输入的图像48*16
y = tf.placeholder("float", shape=(None, FLAGS.classes), name="output") # 输出的标签 1*2
is_training = tf.placeholder(tf.bool, name="flag") # 标志位,是训练还是预测
......
......
......
for i in range(total_batch):
images, labels = sess.run([train_batch_xs, train_batch_ys])
feeds = {x: images, y: labels, is_training: True}
......
......
......
for j in range(test_photo_batch_cnt):
images, labels = sess.run([test_batch_xs, test_batch_ys])
test_feeds = {x: images, y: labels, is_training: False}
这种用法会诱发两个错误问题,查找了很多资料,也没找出相应的最佳解决方案
1.Ckpt转化为pb
在使用命令冻结时候:python reeze_graph.py \--input_graph=./model/graph.pbtxt --input_checkpoint=./model/model- 10000.ckpt \--output_graph=./model/output_graph.pb --output_node_names=softmax_tensor;会出现这样的现象:训练过程中准确率很高,用ckpt的模型进行测试,准确率也高;可是使用pb模型在前向推断时候,得到概率得分值特别低,即pb模型中BN层并未被真正冻结,is_training并没有真正设置为False。
2.转化为TFlite时
import tensorflow as tf
saved_model_dir = '/content/generated/'
converter = tf.contrib.lite.TFLiteConverter.from_saved_model(saved_model_dir, input_arrays=['phase_train'], input_shapes=(1,160,160,3),
output_arrays=['embeddings'])
tflite_model = converter.convert()
open("converted_model_savedModel.tflite", "wb").write(tflite_model)错误如下:19 operators, 369 arrays (0 quantized)\n2019-05-08 18:28:23.560264: I tensorflow/contrib/lite/toco/graph_transformations/graph_transformations.cc:39] After Removing unused ops pass 1: 146 operators, 255 arrays (0 quantized)\n2019-05-08 18:28:23.561756: I tensorflow/contrib/lite/toco/graph_transformations/graph_transformations.cc:39] Before general graph transformations: 146 operators, 255 arrays (0 quantized)\n2019-05-08 18:28:23.561883: F tensorflow/contrib/lite/toco/graph_transformations/resolve_batch_normalization.cc:42] Check failed: IsConstantParameterArray(*model, bn_op->inputs[1]) && IsConstantParameterArray(*model, bn_op->inputs[2]) && IsConstantParameterArray(*model, bn_op->inputs[3]) Batch normalization resolution requires that mean, multiplier and offset arrays be constant.\nAborted (core dumped)\n';
问题参考链接TOCO failed Batch normalization resolution requires that mean, multiplier and offset arrays be constant. #23253 与TFLiteConverter.from_saved_model - batchNorm is not supported? #23627
- 解决方案
中心思想:不要使用is_training = tf.placeholder(tf.bool, name="flag") 这种形式,而是在代码中使用bool变量类型,判断是网络是否训练;首先把网络bool变量中设置为False,其次构建网络图模型,最后,先恢复已经保存好的模型,然后用新构建的网络图模型进行保存;这样可以用新保存的ckpt模型进行冻结,以及用构建好的pb模型转化为TFlite模型;以下是伪代码:
.....
model= tf.estimator.Estimator(
model_fn=train.my_model_fn,
model_dir=model_dir)
features,labels = eval_input_fn(image_path)
predictions = train.my_model_fn(
features,
labels,
tf.estimator.ModeKeys.PREDICT).predictions
# Manually load the latest checkpoint
saver = tf.train.Saver()
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(model_dir)
saver.restore(sess, ckpt.model_checkpoint_path)
savename = ckpt.model_checkpoint_path
tf.train.write_graph(sess.graph_def, model_dir, 'graph.pbtxt', as_text=True)
saver.save(sess=sess, save_path=savename)
.....附录:
- 独立同分布 IID
- 解读Batch Normalization
- Batch Normalization 学习笔记
- 深度学习Batch Normalization作用与原理
- Batch Normalization原理与使用过程
- tensorflow 应用之路]Batch Normalization 原理详解及应用方法
- Inception v2/BN-Inception:Batch Normalization 论文笔记
- Tensorflow系列:Batch-Normalization层
- TensorFlow中batch norm踩坑
- tensorflow batch_normalization的正确使用姿势
- tensorflow中Batch Normalization的实现
- tensorflow中batch normalization模型加载方法
- tensorflow使用BN—Batch Normalization
- Tensorflow训练和预测中的BN层的坑
- 使用tensorflow 的slim模块fine-tune resnet/densenet/inception网络,解决batchnorm问题