云原生时代, Kubernetes 多集群架构初探
为什么我们需要多集群?
近年来,多集群架构已经成为“老生常谈”。我们喜欢高可用,喜欢异地多可用区,而多集群架构天生就具备了这样的能力。另一方面我们也希望通过多集群混合云来降低成本,利用到不同集群各自的优势和特性,以便使用不同集群的最新技术(如 AI、GPU 集群等)。
就是因为这种种原因,多集群几乎成为了云计算的新潮流,而被谈及最多并且落地的多集群场景主要有这三类:
一类用于应对“云突发”。如下图 1 所示,正常情况下用户使用自己的 IDC 集群提供服务,当应对突发大流量时,迅速将应用扩容到云上集群共同提供服务,将多集群作为备用资源池。该模式一般针对无状态的服务,可以快速弹性扩展,主要针对使用 CPU、内存较为密集的服务,如搜索、查询、计算等类型的服务。
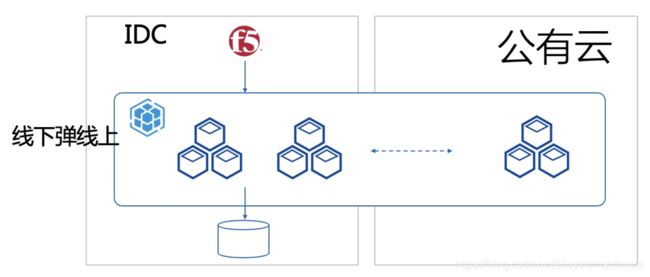
图 1:多集群“云突发”场景
第二类用于“云容灾”。如下图 2 所示,通常主要服务的集群为一个,另一个集群周期性备份。或者一个集群主要负责读写,其他备份集群只读。在主集群所在的云出现问题时可以快速切换到备份集群。该模式可用于数据量较大的存储服务。
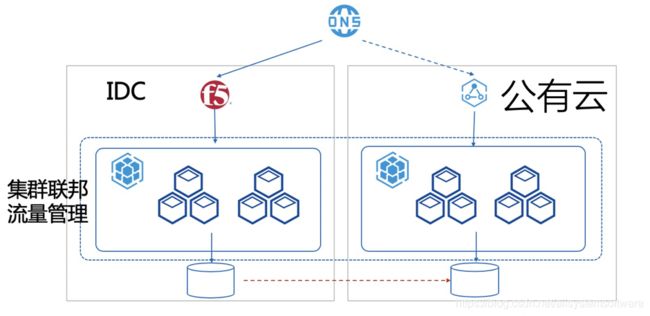
图 2:多集群“云容灾”场景
第三类则用于“异地多活”。如图 3 所示,与“云容灾”的主要区别是数据是实时同步的,多集群都可以同时读写。这种模式通常针对极其重要的数据,如全局统一的用户账号信息等。
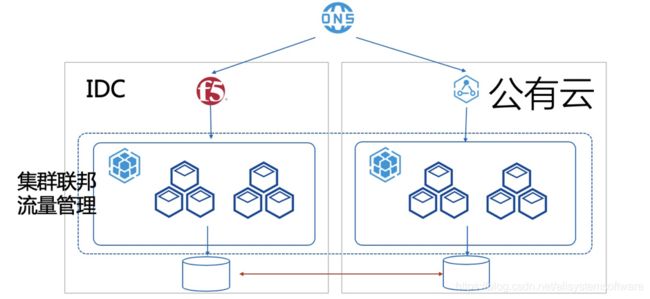
图 3:多集群,异地多活场景
但是多集群同时也带来了巨大的复杂性,一方面如何让应用可以面向多集群部署分发,另一方面是希望应用真正能做到多集群之间灵活切换,想到传统应用迁移的难度可能就已经让我们望而却步了。面向多集群,我们依然缺乏足够成熟的应用交付和管理的能力。
多集群的最后一公里
早在 2013 年,不少老牌云计算厂商就已经在聊“为什么要多集群”,并开始倡导多集群是“Next Big Thing”。
然而残酷的现实却是,每一个不同的云、每一个数据中心都是一套自己的 API 与设计方式,所谓“多集群”多数情况下只是厂商 A 主动集成不同类型集群的一套接入层。
这种背景下的多集群一直以来都以架构复杂著称,具体表现就是各个厂商发布会上令人眼花缭乱的多集群 / 混合云解决方案架构图,如下 图 4 就是一个传统的多集群企业级解决方案架构图,不得不说,我们很难完全理解图中的所有细节。
图 4:传统的多集群企业级解决方案架构图
这种背景下的多集群技术,其实更像是厂商对一个封闭产品的代名词。不同厂商的云有不同的 API、不同的能力特性,厂商们在这之上架构的多集群、混合云解决方案,大量的精力都是在适配和整合不同集群平台上的各类能力。
而对于用户,最终的结果又会是另一种形式的绑定。这样的多集群无法形成生态,也许这就是我们迟迟无法面向这种多集群构建统一的应用交付、构建真正多集群能力的原因。
Kubernetes:全世界数据中心的统一 API
不过,伴随着云原生理念的迅速普及,“步履蹒跚”的多集群理念却迎来了一个非常关键的契机。
从 2015 年 CNCF 成立到现在,短短四年多的时间,其组织下就孵化了数十个项目,吸引了近四百位企业级会员的加入,项目贡献人数达到六万三千多人,而每年参与 CNCF 官方活动的人数也早已超过了十万人, CNCF Lanscape 下符合云原生标准的项目已经达到了上千个。
这种 Kubernetes 以及云原生技术体系迅速崛起的直接结果,就是在所有公有云之上, Kubernetes 服务都已经成为了毋庸置疑的一等公民;而全世界几乎所有的科技公司和大量的企业终端用户,也都已经在自己的数据中心里使用 K8s 来进行容器化应用的编排与管理。
不难看到,Kubernetes 正在迅速成为全世界数据中心的统一 API。

图 5:云原生的曙光
这层统一而标准的 API 之下,多集群和混合云的能力才开始真正体现价值。
Kubernetes 和它所推崇的声明式容器编排与管理体系,让软件交付本身变得越来越标准化和统一化,并且实现了与底层基础设施的完全解耦;而另一方面,云原生技术体系在所有公有云和大量数据中心里的落地,使得软件面向一个统一的 API 实现“一次定义,到处部署”成为了可能。
Kubernetes API 在全世界数据中心里的普及,终于让多集群和混合云理念有了一个坚实的事实基础。而伴随着软件产业对提升效率、降低成本的巨大渴望,云原生加持下的云计算飞轮终于启动,并将越飞越快。
多集群时代的 “ The Platform for Platform”
大家可能听说过,Kubernetes 项目的本质其实是 Platform for Platform,也就是一个用来构建“平台”的“平台”。
相比于 Mesos 和 Swarm 等容器管理平台,Kubernetes 项目最大的优势和关注点,在于它始终专注于如何帮助用户基于 Kubernetes 的声明式 API ,快速、便捷的构建健壮的分布式应用,并且按照统一的模型(容器设计模式和控制器机制)来驱动应用的实际状态向期望状态逼近和收敛。
而当 The Platform for Platform 的特质和多集群连接在一起, Kubernetes 的用户实际上直接拥有了面向多集群统一构建平台级服务的宝贵能力。
比如, kubeCDN 项目就是这样的一个典型案例,它的核心思想,就是直接基于全世界公有云上的 K8s 集群来自建 CDN。借助云原生技术,巧妙的解决了使用传统 CDN 厂商服务的很多痛点(包括安全性没有保障、服务质量依赖外部厂商、CDN 厂商看重利润忽视部分用户需求、商业机密可能被泄露洞察等等)。在实现上,kubeCDN 在不同的区域构建 K8s 集群,并通过 Route53 来根据延迟智能路由用户的请求到最优的集群。而作为搭建 CDN 的基础,Kubernetes 则帮助用户整合了基础设施,其本身统一的 API 又使得用户可以快速分发内容部署应用。

图 6:CDN 场景的 K8s 多集群
不难看到,基于 Kubernetes 的多集群给了 kubeCDN 灾备和统一多集群资源的能力;而统一标准的 Kubernetes API 层,则把构建一个全球级别 CDN 的代价减少到了几百行代码的工作量。基于 K8s 的多集群混合云,正在为不同的产业带来了新的活力和更多的想象空间。
云的未来,是面向多集群的应用交付
如果说多集群是云计算的未来,那么多集群的未来又是什么呢?
云原生技术的发展路径是持续输出“事实标准的软件”,而这些事实标准中,应用的弹性(resiliency)、易用性(usability)和可移植性(portability)是其所解决的三大本质问题。
-
应用的弹性对于云产品的客户来说等价于业务可靠性和业务探索与创新的敏捷性,体现的是云计算所创造的客户价值,应用弹性的另一个关注点在于快速部署、交付、以及在云上的扩缩容能力。这就需要完善的应用交付链路以及应用的云原生开发框架支撑;
-
其次,良好易用性才能更好地发挥应用的弹性。在微服务软件架构成为主流的情形下,易用性需要考虑通过技术手段实现对应用整体做全局性的治理,实现全局最优。这凸显了 Service Mesh 的服务能力;
-
最后,当应用具备良好的可移植性,实现多集群和混合云的战略将成为必然趋势。
就像 K8s 是云时代的操作系统,而在这操作系统之上构建的应用还需要一系列的开发、交付、管理工具。云计算的价值,最终会回归到应用本身的价值。而如何服务好这些应用,将成为云厂商们新一轮能力的体现。
在这条路径上,统一的云原生应用标准定义和规范,通用的应用托管和分发中心,基于 Service Mesh 的、跨云的应用治理能力,以及 K8s 原生的、面向多集群的应用交付和管理体系,将会持续不断的产生巨大的价值。
Kubernetes 项目在“多集群”上的探索
当前 K8s 围绕多集群也已经开始了许多项目,如 Federation V2,Cluster Registry,Kubemci 等。在这之前更早开始的项目是 Federation v1,但是如今已经逐渐被社区所废弃。这其中的主要原因,在于 v1 的设计试图在 K8s 之上又构建一层 Federation API,直接屏蔽掉了已经取得广泛共识的 K8s API ,这与云原生社区的发展理念是相悖的。
而 RedHat 后来牵头发起的 Federation V2 项目, 则以插件的形式融入到 K8s API 中(即我们熟悉的 CRD)。它提供了一个可以将任何 K8s API type 转换成有多集群概念的 federated type 的方法,以及一个对应的控制器以便推送这些 federated 对象 (Object)。而它并不像 V1 一样关心复杂的推送策略(V1 的 Federation Scheduler),只负责把这些 Object 分发到用户事先定义的集群去。
需要注意的是,这里被推送到这些集群上的对象,都来自于一个相同的模板,只有一些元数据会有差别。另外,被推送的 type 都需要制作 Fedrated type,这在 type 类型比较有限的时候才比较方便。
这也就意味着 Federation v2 的主要设计目标,其实是向多集群推送 RBAC,policy 等集群配置信息:这些可推送资源类型是固定的,而每个集群的配置策略格式也是基本类似的。
所以说,Federation v2 的定位暂时只是一个多集群配置推送项目。
然而,面向多集群交付应用背后往往是有着复杂的决策逻辑的。比如:集群 A 当前负载低,就应该多推一些应用上去。再比如,用户可能有成百上千个来自二方、三方的软件( 都是 CRD + Operator)要面向多集群交付,在目前 Fed v2 的体系下,用户要去维护这些 CRD 的 Fedreted type,代价是非常大的。
面向应用的 Kubernetes 多集群架构初探
那么一个以应用为中心、围绕应用交付的多集群多集群管理该具备何种能力呢?这里面有三个技术点值得深入思考:
-
用户 Kubernetes 集群可能是没有公网 IP、甚至在私有网络当中的:而无论用户的 Kubernetes 集群部署在任何位置,多集群服务都应该能够将它们接入进来,并且暴露完整的、没有经过任何修改的 Kubernetes API。这是用户进行应用交付的重要基础。
-
以 GitOps 驱动的多集群配置管理中心:用户接入集群的配置管理,需要通过一个中心化的配置管理中心来推送和同步。但更重要的是,这些配置信息应该通过 GitOps、 以对用户完全公开、透明、可审计的方式进行托管,通过 Git 协议作为多集群控制中心与用户协作的标准界面。
-
“托管式”而非“接管式”的统一鉴权机制:无论用户是在使用的是公有云上的 Kubernetes 服务,还是自建 IDC 集群,这些集群接入使用的鉴权证书是由统一机构颁发的。云提供商,不应该存储用户集群的任何秘钥 (Credentials) 信息,并且应该提供统一的授权权限管理能力,允许用户对接入的任何集群做子用户授权。
多集群架构的基石:Kubernetes API 隧道
要将 Kubernetes 集群以原生 API 的托管方式接入到多集群管理体系当中,这背后主要的技术难点是“集群隧道”。
集群隧道会在用户的 Kubernetes 集群里安装一个 agent,使得用户的集群无需公网 IP,就可以被用户像使用公有云上的 Kubernetes 服务一样在公网访问,随时随地愉快的使用、管理、监控自己的集群,拥有统一的鉴权、权限、日志、审计、控制台等等一系列的功能。
集群隧道的架构也应该是简洁的。如下图 7 所示,其核心分为两层,下层是被托管的集群,在其中会有一个 Agent,Agent 一方面在被托管的集群中运行,可以轻易的在内网访问被托管的集群,另一方面它通过公网与公有云接入层中的节点 (Stub) 构建一个隧道 (tunnel)。在上层,用户通过公有云统一的方式接入审计、鉴权、权限相关功能,通过访问 Stub,再通过隧道由 Agent 向用户自己的 Kubernetes 集群转发命令。
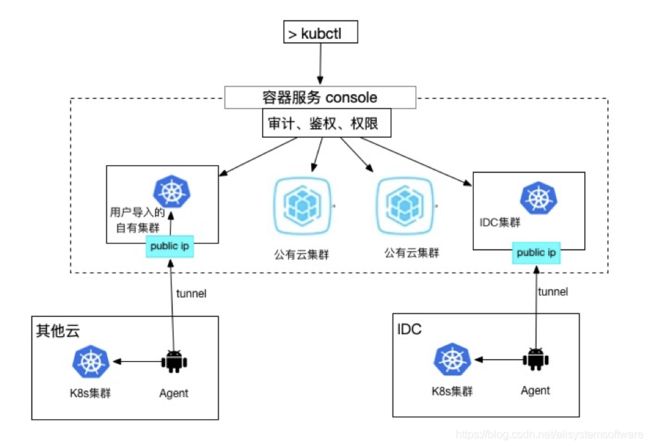
图 7:多集群 K8s 隧道架构
通过这样的层层转发,用户可以使用公有云统一的鉴权方式透明的使用被托管的集群,并且公有云本身不应该触碰和存储用户的鉴权信息。要实现这样的集群隧道,多集群架构必须要能克服两大难题:
- 在用户访问时,API 接入公有云统一的证书管理,包括鉴权、权限、子用户授权等等。
- 在 API 转发到用户 Agent 时,再将请求变为 K8s 集群原有的授权访问,被托管集群的鉴权永远只存在集群本身。
这两大难题,是现有的开源 Tunnel 库、以及原生的四层转发与七层转发都不能完全解决的,这里一一列举如下:
- ngrok:一个曾经很有名,但是目前已经被废弃的项目,github 的 Readme 中明确的写着,“不要在生产环境使用”;
- go-http-tunnel:很简洁的项目,但是一方面源码的协议是 AGPL-3.0,意味着代码无法商用,另一方面,在 kubectl 执行 exec 等命令时需要 hijack 连接,基于 http2 的 tunnel 在协议原理上就天然不满足这个功能;
- chisel: 同样很简洁的项目,底层基于 TCP 构建连接,然后巧妙的利用了 ssh 实现 tcp 连接的 session 管理和多路复用。但是依然无法解决在 tunnel 的一端 (Stub) 对接解析公有云的证书,验证后又在另一端 (Agent) 使用 K8s 的 token 发起新的请求;
- rancher/remotedialer:rancher 的这个项目功能与 chisel 相似,基于 websocket,agent 直接把集群的 token 传递到了 Server 端,需要存储用户自己的集群鉴权信息,与我们的目标不符;
- frp: 一个大而全的项目,有很多如 UI、Dashboard 等功能,但是依然没有直接满足我们在 stub 端证书解析、agent 端 token 访问需求;
- apiserver-network-proxy:与 chisel 的功能很像,基于 grpc,刚开始没多久的项目,同样不能直接满足需求。
阿里云 Kubernetes 服务多集群架构
目前,在阿里云 Kubernetes 服务中( ACK )提供的多集群能力,遵循的正是上述“以应用为中心”的多集群架构。这个功能,以“接入已有集群”作为入口,如下图所示:

图 8:在阿里云容器服务 Kubernetes 版上使用“接入已有集群”能力
集群隧道

图 9:阿里云的集群隧道架构
这个多集群架构如图 9 所示,跟上一节所述是基本一致的。具体来说,阿里云的 ACK 服务(容器服务 Kubernetes 版)会在用户集群上安装一个 Agent,安装完毕后 Agent 只需要能够公网访问,用户就可以在 ACK 上使用自己的集群,通过 ACK 统一的鉴权方式体验原生的 K8s API。
长连接与长响应
在 Kubernetes 控制操作中,存在诸如 kubectl exec , kubectl port-forward 基于非 HTTP 协议的长连接以及 kubectl logs -f 这种反馈持续时间较长的长响应。它们对于通信链路的独占使得 HTTP/2 的多路复用无法运作,Go 语言官方库中的 HTTP/1.1 本身也不支持协议升级,故而无法采用原生七层 HTTP 转发。
为了解决这两大难题,ACK 的隧道技术上采用了一系列策略进行应对:
- 使用原生七层转发,对转发数据进行证书识别,将 Kubernetes 权限注入,解决鉴权问题;
- 对于协议升级请求,劫持七层链路,使用四层链路,进而使用原生四层无感知转发,解决长连接问题;
- 只在发送请求方向上复用链路,每次反馈建立新链路,防止阻塞,解决长响应问题。
隧道高可用
除此之外,在 ACK 的隧道设计中,由于中间的链路(Agent 与 Stub)对于用户而言是透明的,在客户端以及目标集群的 API Server 正常运转的情况下,不能因为中间链路的故障导致无法连接,因此 ACK 隧道还提供了 Agent 与 Stub 的高可用能力,提高容错力,降低故障恢复时间。
Agent 高可用
允许多个 Agent 同时连接 Stub,多个 Agent 的存在不仅可以高可用,还可以作为负载均衡来使用。
- 多 Agent 负载均衡 :一方面,每个 Agent 会定时向 Stub 发送当前的可用状态,另一方面,Stub 进行数据包转发时,采用随机轮询的方式,选择一个可用的 Agent 转发;
- 多集群防干扰、集群切换:在多 Agent 的存在下,可能会涉及到 Agent 来自不同的 Kubernetes 集群造成干扰,所以同样需要加入 Agent 的集群唯一 ID。当原先集群的所有连接都断开时,会进行集群切换。
Stub 高可用
在 Stub 端,由于客户端只会向同一个 IP 发送,多个 Stub 的存在需要使用 Kubernetes 的 Service 进行协调,例如可以使用 LoadBalancer。但是,如果使用 LoadBalancer 对请求进行分流,一个重要问题是,由于长连接的存在,从客户端发出的信息可能是上下文相关的而非互相独立的。TCP 四层分流会破坏上下文,所以 Stub 在同一时刻应当只能有一个在起作用。
在只有一个 Stub 运行的情况下,依然要保证其高可用,这里 ACK 隧道采用了 Kubernetes 的 Lease API 等高可用能力。因此 Stub 端的高可用虽然不能像 Agent 端一样起到分流分压作用,但是它提供滚动升级等能力。
结语
云的边界正在被技术和开源迅速的抹平。越来越多的软件和框架从设计上就不再会跟某云产生直接绑定。毕竟,你没办法抚平用户对商业竞争担忧和焦虑,也不可能阻止越来越多的用户把 Kubernetes 部署在全世界的所有云上和数据中心里。
在未来云的世界里,K8s 会成为连通“云”与“应用”的高速公路,以标准、高效的方式将“应用”快速交付到世界上任何一个位置。而这里的交付目的地,既可以是最终用户,也可以是 PaaS/Serverless ,甚至会催生出更加多样化的应用托管生态。“云”的价值,一定会回归到应用本身。
多集群与混合云的时代已经来临,以应用为中心的多集群多集群架构,才是云计算生态发展的必然趋势,你的云可以运行在任何地方,而我们帮你管理。让我们一起迎接面向应用的云原生多集群时代,一起拥抱云原生,一起关注应用本身的价值!
作者介绍:
孙健波,阿里云容器平台技术专家,Kubernetes 项目社区成员,负责 ACK 容器服务相关开发工作。
殷达,清华大学与卡内基梅隆大学计算机专业在读研究生,于阿里云容器平台部实习,主要参与 ACK 容器服务多云技术及云原生应用开发。