League-X:深度学习+英雄联盟,英雄联盟小地图识别器,标定对面打野位置
League-X:使用深度学习的英雄联盟小地图辅助器
简介
本人是一个英雄联盟爱好者,同时对人工智能,深度学习之类的课题很感兴趣,去年心血来潮,使用图像识别写了一个识别英雄联盟小地图的代码:
这是第一代的演示
第一代文章链接:Python Tensorflow + CNN + Opencv 英雄联盟小地图识别,LOL Minimap Scanner
今年初我又开始收集更多数据(玩英雄联盟),并且优化了第一代的神经网络和流程,做出了第二代,我将它命名为 League-X. 这代程序可以将对方打野上次出现的位置用透明颜色标定,我放一张演示图上来:
这是第二代 “League-X” 的演示
本项目已经在github上公开,可以访问 League-X获得。
相似项目:
在我之前,Farza Majeed 与 Ian Shoneveld 已经做过类似的项目,有兴趣的可以去点击下面的链接来看他们写的文章:
Deep League
Getting Champion Coordinates from the LoL Minimap using Deep Learning
思路
如果已经读过我的第一篇文章,可以直接挑到“训练神经网络“”部分
总的来说,我的目标就是针对在小地图中区分并标定英雄图标。有两种识别方式可以完成我的目的:
- 图片分类(Image Classification)
- 物体识别(Object Recognition)
其中,图片分类要求在向神经网络输入图片前处理图像,并将英雄的头像提取,从而尽可能地减少图像中的相似之处,这种方法的优点是速度快,准确率高。 而以物体识别为目的的神经网络不需要提前提取英雄的图像,可以将整个小地图输入进神经网络,得到的是一系列的英雄名字以及他们的坐标。 物体识别好在不需要提前手写图像处理算法,弱在需要处理更多的像素,速度慢,且更多的相似特征将使其准确率降低。
我的选择是采用图片分类算法基于本人对此算法更有经验且提取英雄的头像的图像处理算法并不复杂,利用OpenCV可以高速运行。
整的流程如下图所示
第一步:图像处理
1. 获取图像并转换
首先,在 python 中,截取屏幕并处理图像需要的拓展库为:PIL, Opencv, Numpy。我们依次引用,第一个函数是截取电脑屏幕的一部分的代码。PIL 的截图输入位置为我们显示器的像素位置,入代码中注释。
# 图像处理
#引用
from PIL import ImageGrab
from PIL import Image
import cv2
import numpy as np
def getimg():
image = ImageGrab.grab((1645,805,1920,1080))
image_array = np.array(image)
image_bgr = cv2.cvtColor(image_array,cv2.COLOR_RGB2BGR)
return image_bgr
"""
(x1,y1)
________________________
| |
| |
| |
| |
| Minimap |
| |
| |
| |
| |
|________________________|
(x2,y2)
"""
#x1 = 1645
#y1 = 805
#x2 = 1920
#y2 = 1080
Opencv 默认的图像是以 np.ndarray 的格式存在的,并且它的三通道分别是 Blue, Green, Red. 要想利用 Opencv 处理 PIL 获取的图片,我们首先需要将其转换成numpy的矩阵格式,然后利用 cv2.cvtColor 函数将原本的 RGB 格式 转换成 opencv 默认的 BGR 格式。
2. 过滤出图像中的红色通道
首先,玩过英雄联盟的朋友都知道,小地图中敌方英雄的头像都是用红色圆圈框住的,队友则是用蓝色框框住的,所以如果我们利用英雄联盟的这一特征我们是不是可以提取对方英雄的头像框?请看下图。
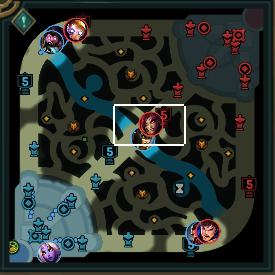
这张图片抓取的是一把正在进行的英雄联盟游戏的小地图,可以看到,游戏里敌方 ‘机器人’,‘婕拉’, ‘盖伦’ 头像旁都有一个红色的圈。这一特征为我们创造了极大的便利,也许在 3色道图中不够明显,请接着看下面的单个通道拆开的图片,注意观察 ‘机器人’ ,‘婕拉’ , ‘盖伦’ 这三个英雄在三个颜色通道里头像框的区别。

注意到了吗? 如果没有的话继续仔细观察这三个英雄头像框在三个通道里的区别。 这三个敌方英雄的头像框在 Red 通道里近乎是白色的,也就是说它拥有比它周围所有色块都显著的高的值。 如果我们把注意力集中到红色通道,设置一个阀值然后把它二值化(所有低于阈值的 = 0, 高于阀值 = 255),我们将得到理想的 ROI (Region of Interest, 感兴趣区域)。
但是首先我们得过滤掉红色通道中由其他颜色附加的红色值,在计算机视觉中,越是亮丽的颜色会更多的包含其他颜色的 RGB 值。什么意思呢? 打个比方,在图片的 (x,y), 坐标,它呈现给我们的是亮丽的绿色,它的 RGB 值为 (150,249,120). 在同图片的另一个坐标(x2,y2), 我们看见了深沉的红色,其 RGB 为 (140,50,50)。 如果我们单纯的看这张图片的红色通道,我们会认为 (x,y) 比 (x2,y2) 更红,因为 150 > 140。然而,很明显这是错的。 所以我们在提取红色通道之前需要考虑到这些亮丽的非红色很有可能被我们错误地认为是红色。
 RGB (150,255,100)
RGB (150,255,100)
 RGB (140,20,20)
RGB (140,20,20)
要避免这种情况很简单,代码如下
b,g,r = cv2.split(image) #提取 RGB 通道
#将图像二值化
inranger = cv2.inRange(r,120,255)
inrangeg = cv2.inRange(g,120,255)
inrangeb = cv2.inRange(b,120,255)
#用红色二值图减去其他两个通道的二值图
Red_channel = inranger - inrangeg - inrangeb
cv2.imshow('Red_channel',Red_channel)
运行后得到以下图片
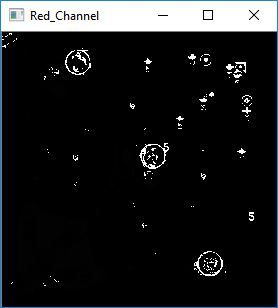
利用红色通道减去其他通道可以有效地抵消非红色在红色通道中占有的值,得到理想的图片,这里的 (120,255)是博主反复测试后得到的最佳值。图片中白色的圈均为上文中的英雄头像的红色框。接下来,我们只需要运行圆圈检测来获得这些白色圆圈的坐标。
3. 识别圆圈
对于识别圆圈, Opencv 提供了自己的算法 cv2.HoughCircle 就是利用霍夫算法检测圆圈的,因为本人对此算法没有了解这里就不多作评论了下面是代码的实现:
对霍夫算法感兴趣的可以看一下这一篇文章: https://blog.csdn.net/qq_25254777/article/details/78811342
coord = [] #list 保存找到的英雄的坐标
champion_list = [] #list 保存找到的英雄的头像
champion_list_text = [] #list 保存神经网络识别后的英雄名称
circles = cv2.HoughCircles(Red_channel,cv2.HOUGH_GRADIENT,1,10,param1 = 30,param2 =15,minRadius = 9, maxRadius = 30)
if(circles is not None):
for n in range(circles.shape[1]):
x = int(circles[0][n][0])
y = int(circles[0][n][1])
coords.append([x,y])
radius = int(circles[0][n][2])
cropped = image[y-radius:y+radius,x-radius:x+radius].copy()
to_append = cv2.resize(cropped,(24,24))
champion_list.append(to_append)
cv2.rectangle(image,(x - radius , y - radius),(x + radius , y + radius),(255,255,255),1)
champion_list = np.stack(champion_list,axis = 0,)
champion_list = champion_list.reshape((champion_list.shape[0], 24, 24, 3))
"""
以下代码是使用训练好的神经网络识别截取的英雄头像
champion_list_text = league_scanner.predict(champion_list)
for n in range(len(champion_list_text)):
cv2.putText(image,class_names[champion_list_text[n]],(coords[n][0]-12,coords[n][1]-12), cv2.FONT_HERSHEY_SIMPLEX,1,(255,255,255),1)
"""
其中red channel 是上一步骤图像处理后的的小地图图像,这一步骤完成后,执行
champs = np.concatenate((champion_list[0],champion_list[1],champion_list[2]),axis = 1)
cv2.imshow('champions', champs)
cv2.waitKey(0)
获得以下结果

好的,现在我们已经完成了利用图像处理提取英雄联盟中的英雄图像,下一步就是将他们放入神经网络,进行卷积以及训练了。
第二步:训练神经网络
获得大量的可训练数据
这个问题最初难倒了我,虽然我有一个可以从小地图中提取英雄头像的算法,我总不可能疯狂地打英雄联盟并且手动标定每个图像是什么英雄吧?但是当我试过所有其他方法获取英雄头像之后,发现之后当真人玩游戏的时候录制的数据训练之后准确率最高。所以,我只能很难为地开始一局一局地打英雄联盟,来收集数据,嘿嘿。
每开始一把英雄联盟游戏之前,我都会开始录屏。游戏结束之后我就会运行我的python脚本,把我刚刚那一把游戏里的小地图里的所有英雄都提取出来。然后我会一个一个地看这些图像,手动标定这些图片,最终我有了以下的数据库:
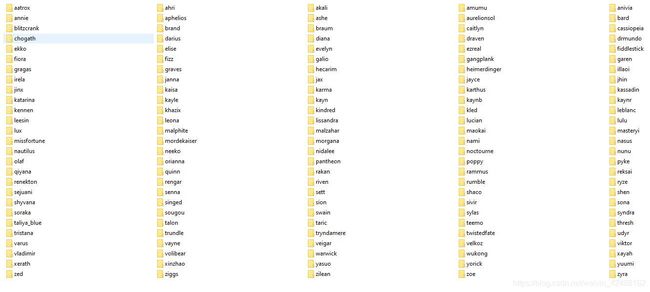
其中,每一个文件夹中都是这样的
为了收集这些数据,我打了200多场英雄联盟,嘿嘿。
整理获得的数据
让我们想象我们在一局英雄联盟中,我方有 寒冰,阿木木,安妮,机器人,牛头,对方有 女警,蛇女,大虫子,诺手,蒙多
我们可以肯定的是,任何在这十个英雄以外的英雄的出现几率为0%。所以我们可以利用这个特征,我们的目标是在小地图里识别对面的五个英雄,我们是要在149个英雄之间选呢?还是在5个已知英雄之间选呢?数学告诉我们:
P e r m u t a t i o n ( 149 , 5 ) ≈ 6.5 × 1 0 9 , Permutation(149,5) \approx 6.5\times10^9, Permutation(149,5)≈6.5×109,
同时 P e r m u t a t i o n ( 5 , 5 ) ≈ 120 。 Permutation(5,5) \approx 120。 Permutation(5,5)≈120。
所以如果我们训练的神经网络只在游戏里的英雄中做选择,理论上来讲,这个神经网络的任务的复杂程度将会比在所有英雄之间选择减少 54,000,000 倍。所以我们需要让用户在每次开局之前选择本局中的英雄,然后在游戏加载的时候将神经网络训练完成。为此,我搭建了一个窗体程序:
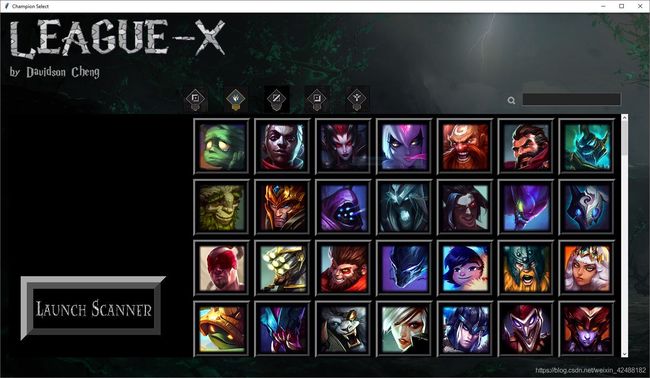
这个窗体允许使用者在每场游戏开始之前选择本局中的英雄,然后它会将所有被选择的英雄的数据整合,标定,进行训练。这整个过程在我的笔记本上需要大概一分钟,所以完全可以在加载的时间内将神经网络训练完成。
搭建并训练神经网络
使用tensorflow搭建神经网络并不复杂,本人觉得还不如安装 tensorflow gpu 复杂。 本人推荐大家使用 anaconda 在 windows 和 mac 上配置 python 的环境,非常方便,几行代码。这里使用的是 tensorflow-gpu,训练用的是 Acer Predator Helios 500 笔记本电脑,显卡是英伟达的 GTX 1070。
如果使用的是 GTX 系列显卡,配置tensorflow-gpu前首先需要安装 CUDA,安装 CUDA 后需要查看你的gpu 驱动是否支持你的CUDA 版本,不支持的话需要更新gpu驱动。
用 conda 配置 tensorflow gpu:https://towardsdatascience.com/tensorflow-gpu-installation-made-easy-use-conda-instead-of-pip-52e5249374bc , 这个是英文版,之后我看看有没有时间把它概括一下翻译成中文。
废话不多说,下面开始搭建并训练网络—>
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
import numpy as np
from tensorflow import keras
#导入处理好的训练数据以及测试数据
train_images = np.load("training_set/train_images.npy")
train_labels = np.load("training_set/train_labels.npy")
test_images = np.load("training_set/test_images.npy")
test_labels = np.load("training_set/test_labels.npy")
使用了 tensorflow 的 keras 模块来搭建模型。 keras 是tensorflow 底下第一个函数库,它的目的是将创建模型,神经网络层,处理数据简化。使用keras搭建神经网络模型常用的层只需要一行代码就可以,非常适合初学者。
#i = train_images[0]
#确保导入的数据中没有空的矩阵,一个空的矩阵数据可以把使整次训练失败
assert not np.any(np.isnan(train_images))
assert not np.any(np.isnan(test_images))
#Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
在tensorflow中如果训练中有一个训练数据的矩阵的值为空,它会对整个模型的weights造成极大的错误的改变,所以需要用 assert 来确认训练及测试数据集中没有为 ‘nan’ 的数据。
为了防止模型过度拟合(模型中的变量远大于它实际所需的变量,优化器过快的优化),这里将每个图片的值都从 0-255 整数 调整到了 0-1 的 float。一般来说如果一个神经网络过度拟合,它会在前几个轮回快速达到很高的准确率然后在接下来的所有轮回中止步不前。过度拟合也很有导致一个神经网络找到数据集标定的小漏洞,使其在训练集中达到高准确率但是面临实际数据低准确率。
#以下的神经网络有参照 AlexNet,但是由于我处理的数据单个尺寸很小,训练集相似度极高,做了一点更改
model = keras.models.Sequential()
#卷积层
model.add(keras.layers.Conv2D(16, (3, 3), activation='relu', input_shape=(24, 24,3)))
#Maxpooling 层
model.add(keras.layers.MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='valid'))
#卷积层
model.add(keras.layers.Conv2D(32, (3, 3), activation='relu'))
#MaxPooling 层
model.add(keras.layers.MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='valid'))
#将数据展开,方便放入神经网络
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(12,kernel_regularizer=keras.regularizers.l2(0.001), activation='relu'))
#最终输出的node数为五个,毕竟我们只需要识别五个英雄
model.add(keras.layers.Dense(5, activation='softmax'))
model.summary()
model.compile(optimizer= "Adadelta",
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
因为输入的数据比较小,所以只采用了2层卷积以及MaxPooling,然后直接展开放入 Fully Connected 训练。 这个网络非常简单,第一层 Convolution 将图像的像素转换成成特征,flatten 将卷积后的 22*22 图像展开并且将一张张的图片输入进fully connected,然后使用‘’sparse_categorical_crossentropy‘’方法计算‘’loss‘’并且利用 ‘’adam’优化器来优化dense层中的比重。
至于为什么利用 33 的矩阵卷积 2424 的图像后输出会为 22*22 请看下图:
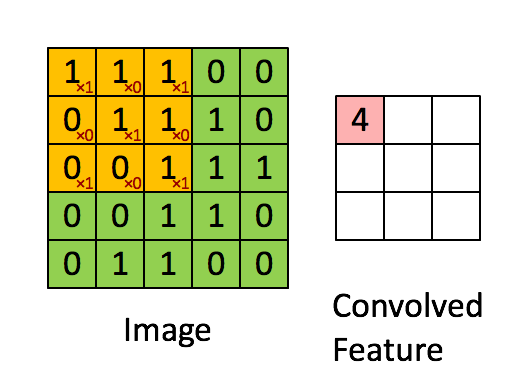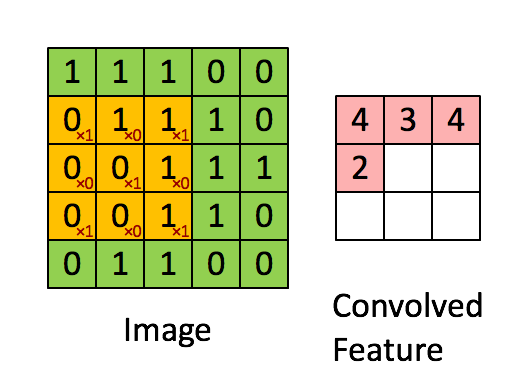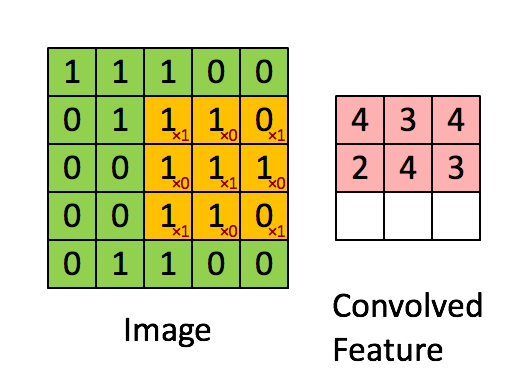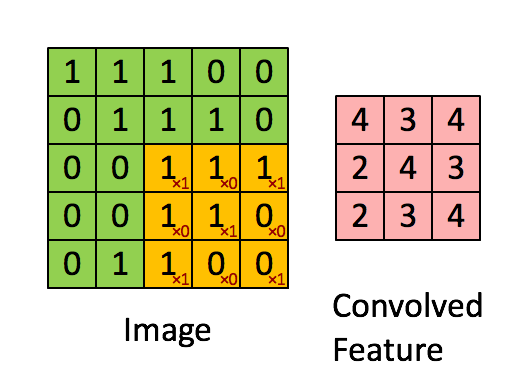
这就是CNN(卷积神经网络)的基础,卷积层。卷积在图像识别及图像分类的神经网络中被广泛应用,它可以提取出方便机器识别的图片特征。同时会随着卷积核的维度将原本图片缩小。
检测以及保存模型
好了大功告成,让我们利用训练数据集来检测一下我们训练完的模型的准确率吧!
#训练神经网络
history = model.fit(train_images, train_labels, epochs=100, callbacks=[cp_callback])
#测试神经网络
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test Accuracy:' + str(test_acc*100) + '%')
model.save('my_model.h5')
Console:Test Accuracy: 100.0%
记录对面打野位置
好了,我们现在已经完成了技术上最具挑战的部分:识别对方英雄坐标。接下来我们只需要新增一个变量,对方英雄上次出现坐标,然后每次检测到这个英雄都将这个变量刷新一次就行了。然后将对面的打野特殊对待以下,将对面打野的位置在小地图上标定出来。
class leagueChampion:
def __init__(self,champName):
"""
创立一个英雄的 class
"""
self.name = champName
self.coord = None #这个变量将存储这个英雄上次被检测到的坐标
self.jungler = False #这个boolean表示这个英雄是不是打野
self.time_recorded = None
self.image = np.zeros([24,24,3],dtype=np.uint8)
self.minimap_image = cv2.imread("minimap_head/"+champName+".png")
然后,将这个新创的英雄class结合到我原来的代码,我在一把蒙多是打野的游戏中测试了一下,蒙多上一次在地图中出现的位置我用透明的蒙多标定了:
总结:
亮丽之处:
- 利用图像处理提取 roi,效率高
- 训练数据量少,训练速度快
- 针对本局英雄,进一步提升效率
- 标定对方打野上次出现的位置
缺点:
- 需要人手动选择本局游戏的对方英雄
- 目前支持131/149 个英雄联盟英雄,还需要 “收集更多数据”
目前这个英雄联盟小地图识别器可以达到输入一张小地图图片,输出里面存在的敌方英雄以及他们的位置,并标定对方打野上次出现的位置。将来还有更多拓展研究空间,比如:
- 根据已知敌方英雄位置,结合对方玩家的段位,预测gank,游走,以及偷龙的举动 (CNN,RNN)
- 在职业赛场上学习某一个选手或者队伍的操作风格,帮助职业队伍针对这一风格 (RNN)
- 创建更加智能的AI,以供人类玩家锻炼提升 (RNN)
- 运用到更多的游戏,为游戏公司提供游戏中计算机无法直接获得的信息
谢谢你阅读到这里,我很开心你能读到这里。将来我会将AI用在更加有意义的方向。如果看完后对我有问题,想交流可以评论,私信,或者发邮件到 [email protected]. 谢谢!