SpringCloud微服务-服务注册发现-负载均衡-服务调用-服务降级-服务网关-配置中心-消息总线-消息驱动-链路追踪-alibaba-nacos-sentinel-seata理论原理分析
SpringCloud理论技术
概述
Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring Cloud并没有重复制造轮子,它只是将各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
----来自百度
主流技术栈
服务注册中心 Eureka,Zookeeper,Consul
服务调用 openFeign
负载均衡 Ribbon
服务降级/服务熔断 Hystrix
服务网关 GetWay,Zuul
配置中心 Config
消息总线 Bus
消息驱动 Stream
链路跟踪 Sleuth
服务注册与发现
1、为什么使用服务发现?
想象一下,如果你在写代码调用一个有REST API或Thrift API的服务,你的代码需要知道一个服务实例的网络地址(IP地址和端口)。运行在物理硬件上的传统应用中,服务实例的网络地址是相对静态的,你的代码可以从一个很少更新的配置文件中读取网络地址。但是在一个现代的,基于云的微服务应用中,这个问题就变得复杂多了,如下图所示:
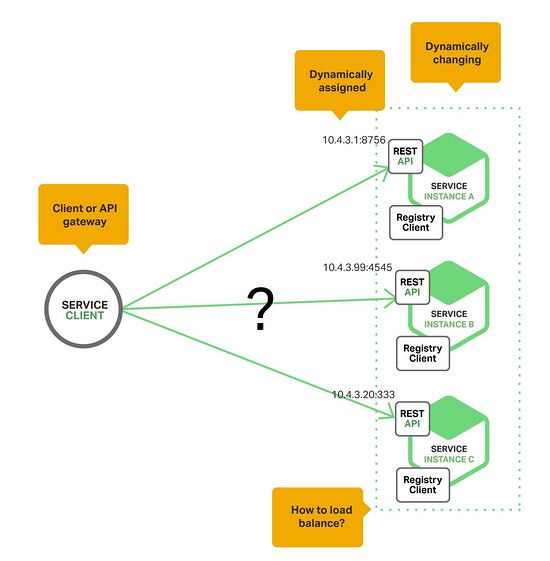
服务实例的网络地址是动态分配的。而且,由于自动扩展,失败和更新,服务实例的配置也经常变化。这样一来,你的客户端代码需要一套更精细的服务发现机制。
有两种主要的服务发现模式:客户端服务发现(client-side discovery)和服务器端服务发现(server-side discovery)。我们首先来看下客户端服务发现。
2、客户端服务发现模式
当使用客户端服务发现的时候,客户端负责决定可用的服务实例的网络地址,以及围绕他们的负载均衡。客户端向服务注册表(service registry)发送一个请求,服务注册表是一个可用服务实例的数据库。客户端使用一个负载均衡算法,去选择一个可用的服务实例,来响应这个请求,下图展示了这种模式的架构:
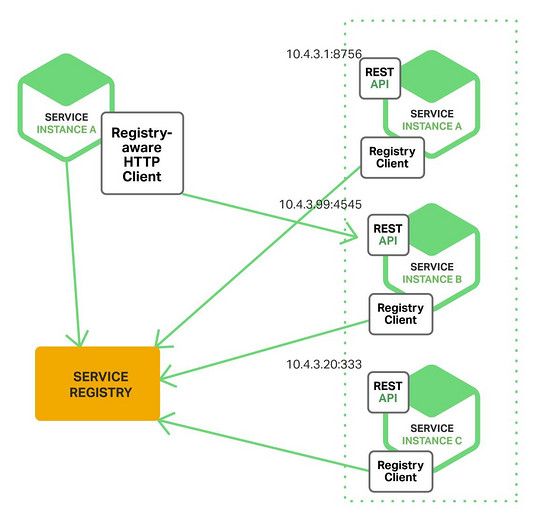
一个服务实例被启动时,它的网络地址会被写到注册表上;当服务实例终止时,再从注册表中删除。这个服务实例的注册表通过心跳机制动态刷新。
客户端的服务发现模式有优势也有缺点。这种模式相对直接,但是除了服务注册表,没有其它动态的部分了。而且,由于客户端知道可用的服务实例,可以做到智能的,应用明确的负载均衡决策,比如一直用hash算法。这种模式的一个重大缺陷在于,客户端和服务注册表是一一对应的,必须为服务客户端用到的每一种编程语言和框架实现客户端服务发现逻辑。
3、服务器端服务发现模式
下图展示了这种模式的架构
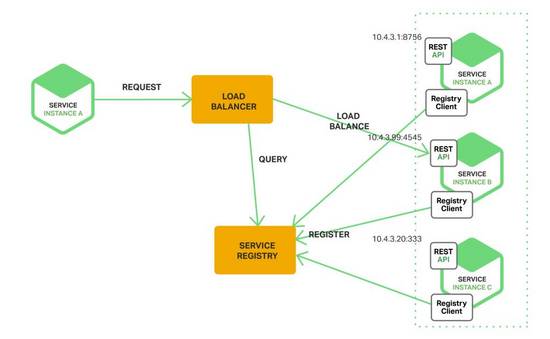
客户端通过负载均衡器向一个服务发送请求,这个负载均衡器会查询服务注册表,并将请求路由到可用的服务实例上。通过客户端的服务发现,服务实例在服务注册表上被注册和注销。
AWS的ELB(Elastic Load Blancer)就是一个服务器端服务发现路由器。一个ELB通常被用来均衡来自互联网的外部流量,也可以用ELB去均衡流向VPC(Virtual Private Cloud)的流量。一个客户端通过ELB发送请求(HTTP或TCP)时,使用的是DNS,ELB会均衡这些注册的EC2实例或ECS(EC2 Container Service)容器的流量。没有另外的服务注册表,EC2实例和ECS容器也只会在ELB上注册。
HTTP服务器和类似Nginx、Nginx Plus的负载均衡器也可以被用做服务器端服务发现负载均衡器。例如,Consul Template可以用来动态配置Nginx的反向代理。
Consul Template定期从存储在Consul服务注册表的数据中,生成任意的配置文件。每当文件变化时,会运行一个shell命令。比如,Consul Template可以生成一个配置反向代理的nginx.conf文件,然后运行一个命令告诉Nginx去重新加载配置。还有一个更复杂的实现,通过HTTP API或DNS去动态地重新配置Nginx Plus。
有些部署环境,比如Kubernetes和Marathon会在集群中的每个host上运行一个代理。这个代理承担了服务器端服务发现负载均衡器的角色。为了向一个服务发送一个请求,一个客户端使用host的IP地址和服务分配的端口,通过代理路由这个请求。这个代理会直接将请求发送到集群上可用的服务实例。
服务器端服务发现模式也是优势和缺陷并存。最大的好处在于服务发现的细节被从客户端中抽象出来,客户端只需要向负载均衡器发送请求,不需要为服务客户端使用的每一种语言和框架,实现服务发现逻辑;另外,这种模式也有一些问题,除非这个负载均衡器是由部署环境提供的,又是另一个高需要启动和管理的可用的系统组件。
4、服务注册表(Service Registry)
服务注册表是服务发现的关键部分,是一个包含了服务实例的网络地址的数据库,必须是高可用和最新的。客户端可以缓存从服务注册表处获得的网络地址。但是,这些信息最终会失效,客户端会找不到服务实例。所以,服务注册表由一个服务器集群组成,通过应用协议来保持一致性。
正如上面提到的,Netflix Eureka是一个服务注册表的好例子。它提供了一个REST API用来注册和查询服务实例。一个服务实例通过POST请求来注册自己的网络位置,每隔30秒要通过一个PUT请求重新注册。注册表中的一个条目会因为一个HTTP DELETE请求或实例注册超时而被删除,客户端通过一个HTTP GET请求来检索注册的服务实例。
Netflix通过在每个EC2的可用区中,运行一个或多个Eureka服务器实现高可用。每个运行在EC2实例上的Eureka服务器都有一个弹性的IP地址。DNS TEXT records用来存储Eureka集群配置,实际上是从可用区到Eureka服务器网络地址的列表的映射。当一个Eureka服务器启动时,会向DNS发送请求,检索Eureka集群的配置,定位节点,并为自己分配一个未占用的弹性IP地址。
Eureka客户端(服务和服务客户端)查询DNS去寻找Eureka服务器的网络地址。客户端更想使用这个可用区内的Eureka服务器,如果没有可用的Eureka服务器,客户端会用另一个可用区内的Eureka服务器。
其它服务注册的例子包括:
- Etcd:一个高可用,分布式,一致的key-value存储,用来共享配置和服务发现。Kubernetes和Cloudfoundry都使用了etcd;
- Consul:一个发现和配置服务的工具。客户端可以利用它提供的API,注册和发现服务。Consul可以执行监控检测来实现服务的高可用;
- Apache Zookeeper:一个常用的,为分布式应用设计的高可用协调服务,最开始Zookeeper是Hadoop的子项目,现在已经顶级项目了。
下面我们来看看服务实例如何在注册表中注册。
5、服务注册(Service Registration)
前面提到了,服务实例必须要从注册表中注册和注销,有很多种方式来处理注册和注销的过程。一个选择是服务实例自己注册,即self-registration模式。另一种选择是其它的系统组件管理服务实例的注册,即第third-party registration模式。
自注册模式(The Self-Registration Pattern)
在self-registration模式中,服务实例负责从服务注册表中注册和注销。如果需要的话,一个服务实例发送心跳请求防止注册过期。下图展示了这种模式的架构:
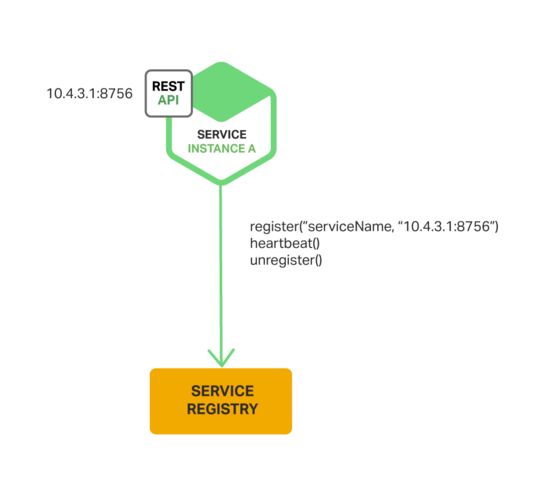
Netflix OSS Eureka客户端是这种方式的一个好例子。Eureka客户端处理服务实例注册和注销的所有问题。Spring Cloud实现包括服务发现在内的多种模式,简化了Eureka的服务实例自动注册。仅仅通过@EnableEurekaClient注释就可以注释Java的配置类
self-registration模式同样也是优劣并存。优势之一在于简单,不需要其它组件。缺点是服务实例和服务注册表相对应,必须要为服务中用到的每种编程语言和框架实现注册代码。
第三方注册模式(The Third-Party Registration Pattern)
在third-party registration模式中,服务实例不会自己在服务注册表中注册,由另一个系统组件service registrar负责。service registrar通过轮询部署环境或订阅事件去跟踪运行中的实例的变化。当它注意到一个新的可用的服务实例时,就会到注册表中去注册。service registrar也会将停止的服务实例注销,下图展示了这种模式的架构。
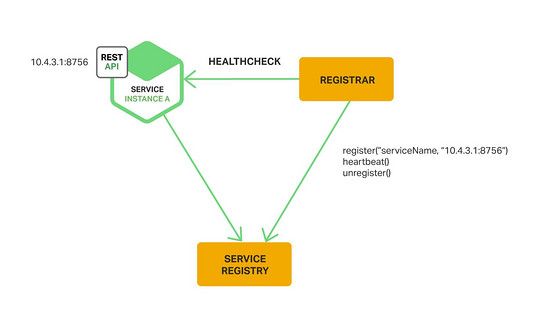
service registrar的一个例子是开源的Registrator项目。它会自动注册和注销像Docker容器一样部署的服务。Registrator支持etcd和Consul等服务注册。
另一个service registrar的例子是NetflixOSS Prana。主要用于非JVM语言编写的服务,它是一个和服务实例配合的『双轮』应用。Prana会在Netflix Eureka上注册和注销实例。
service registrar是一个部署环境的内置组件,由Autoscaling Group创建的EC2实例可以被ELB自动注册。Kubernetes服务也可以自动注册。
third-party registration模式主要的优势在于解耦了服务和服务注册表。不需要为每个语言和框架都实现服务注册逻辑。服务实例注册由一个专用的服务集中实现。缺点是除了被内置到部署环境中,它本身也是一个高可用的系统组件,需要被启动和管理。
6、总结
在一个微服务应用中,服务实例在运行时的配置也会动态变化,包括他们的网络地址。为了满足客户端向服务发送请求的需要,必须要实现服务发现机制。
服务发现的关键部分是服务注册表。服务注册表是一个可用的服务实例的数据库。服务注册表提供了一个管理API和一个查询API。服务实例的注册和注销通过管理API实现,查询API用来寻找可用的服务实例。
有两种主要的服务发现模式:客户端服务发现和服务器端服务发现。客户端服务发现系统中,客户端查询服务注册表,选择一个可用的实例,响应一个请求;在服务器端服务发现系统中,客户端通过一个路由器发送请求,这个路由器会去查询服务注册表,并将请求发送给可用的实例。
有两种形式可以实现服务实例的注册和注销,一种是self-registration模式,一种是third-party registration模式。
一些部署环境中,需要通过类似Netflix Eureka,etcd或Apache Zookeeper的组件,启动自己的服务发现基础设施。其它的部署环境中,服务发现是内置的。比如,Kubernetes和Marathon处理服务实例的注册和注销,还会在每个集群host上运行一个代理,作为服务器端服务发现路由器的角色。
一个HTTP反向代理和Nginx也可以被用做服务器端服务发现负载均衡器。服务注册表可以推送路由信息到Nginx,引起配置更新,比如可以用Consul Template。Nginx Plus支持动态的重配置机制,可以从注册表中拉取服务实例相关的信息,还提供了远程配置的API。
Eureka
1、概述
Spring Cloud 封装了 Netflix 公司开发的 Eureka 模块来实现服务注册和发现。Eureka包含两个组件:Eureka Server和Eureka Client
Eureka 采用了 C-S 的设计架构。Eureka Server 作为服务注册功能的服务器,它是服务注册中心。 而系统中的其他微服务,使用 Eureka 的客户端连接到 Eureka Server并维持心跳连接。这样系统的维护人员就可以通过 Eureka Server 来监控系统中各个微服务是否正常运行。SpringCloud 的一些其他模块(比如Zuul)就可以通过 Eureka Server 来发现系统中的其他微服务,并执行相关的逻辑。
Eureka Server提供服务注册服务:各个节点启动后,会在Eureka Server中进行注册,这样EurekaServer中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观的看到。Eureka Client是一个Java客户端,用于简化Eureka Server的交互,客户端同时也具备一个内置的、使用轮询(round-robin)负载算法的负载均衡器。在应用启动后,将会向Eureka Server发送心跳(默认周期为30秒)。如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,EurekaServer将会从服务注册表中把这个服务节点移除(默认90秒)。
行为状态
-
Register:服务注册
当Eureka客户端向Eureka Server注册时,它提供自身的元数据,比如IP地址、端口,运行状况指示符URL,主页等。 -
Renew:服务续约
Eureka客户会每隔30秒发送一次心跳来续约。 通过续约来告知Eureka Server该Eureka客户仍然存在,没有出现问题。 正常情况下,如果Eureka Server在90秒没有收到Eureka客户的续约,它会将实例从其注册表中删除。 建议不要更改续约间隔。 -
Fetch Registries:获取注册列表信息
Eureka客户端从服务器获取注册表信息,并将其缓存在本地。客户端会使用该信息查找其他服务,从而进行远程调用。该注册列表信息定期(每30秒钟)更新一次。每次返回注册列表信息可能与Eureka客户端的缓存信息不同, Eureka客户端自动处理。如果由于某种原因导致注册列表信息不能及时匹配,Eureka客户端则会重新获取整个注册表信息。 Eureka服务器缓存注册列表信息,整个注册表以及每个应用程序的信息进行了压缩,压缩内容和没有压缩的内容完全相同。Eureka客户端和Eureka 服务器可以使用JSON / XML格式进行通讯。在默认的情况下Eureka客户端使用压缩JSON格式来获取注册列表的信息。 -
Cancel:服务下线
Eureka客户端在程序关闭时向Eureka服务器发送取消请求。 发送请求后,该客户端实例信息将从服务器的实例注册表中删除。该下线请求不会自动完成,它需要调用以下内容:
DiscoveryManager.getInstance().shutdownComponent(); -
Eviction 服务剔除
在默认的情况下,当Eureka客户端连续90秒没有向Eureka服务器发送服务续约,即心跳,Eureka服务器会将该服务实例从服务注册列表删除,即服务剔除。
三大角色
- Eureka Server 提供服务注册和发现
- Service Provider 服务提供方将自身服务注册到Eureka,从而使服务消费方能够找到
- Service Consumer 服务消费方从Eureka获取注册服务列表,从而能够消费服务
功能
Eureka Server
- 提供服务注册:各个微服务启动时,会通过Eureka Client向Eureka Server进行注册自己的信息(例如服务信息和网络信息),Eureka Server会存储该服务的信息。
- 提供服务信息提供:服务消费者在调用服务时,本地Eureka Client没有的情况下,会到Eureka Server拉取信息。
- 提供服务管理:通过Eureka Client的Cancel、心跳监控、renew等方式来维护该服务提供的信息以确保该服务可用以及服务的更新。
- 信息同步:每个Eureka Server同时也是Eureka Client,多个Eureka Server之间通过P2P(Peer To Peer)复制的方式完成服务注册表的同步。同步时,被同步信息不会同步出去。也就是说有3个Eureka Server,Server1有新的服务信息时,同步到Server2后,Server2和Server3同步时,Server2不会把从Server1那里同步到的信息同步给Server3,只能由Server1自己同步给Server3。
- 每个可用区有一个Eureka集群,并且每个可用区至少有一个eureka服务器来处理区内故障。为了实现高可用,一般一个可用区中由三个Eureka Server组成。
Eureka Client
- Eureka Client是一个Java客户端,用于简化与Eureka Server的交互。并且管理当前微服务,同时为当前的微服务提供服务提供者信息。
- Eureka Client会拉取、更新和缓存Eureka Server中的信息。即使所有的Eureka Server节点都宕掉,服务消费者依然可以使用缓存中的信息找到服务提供者。
- Eureka Client在微服务启动后,会周期性地向Eureka Server发送心跳(默认周期为30秒)以续约自己的信息。如果Eureka Server在一定时间内没有接收到某个微服务节点的心跳,Eureka Server将会注销该微服务节点(默认90秒)。
- Eureka Client包含服务提供者Applicaton Service和服务消费者Application Client
- Applicaton Service:服务提供者,提供服务给别个调用。
- Application Client:服务消费者,调用别个提供的服务。
- 往往大多数服务本身既是服务提供者,也是服务消费者。
2、eureka如何管理服务调用
eureka如何管理服务调用的?我们先来看个图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xgAuXGD9-1596214225821)(C:\Users\CR553\Pictures\20190531194608903.png)]
- 在Eureka Client启动的时候,将自身的服务的信息发送到Eureka Server。然后进行2调用当前服务器节点中的其他服务信息,保存到Eureka Client中。当服务间相互调用其它服务时,在Eureka Client中获取服务信息(如服务地址,端口等)后,进行第3步,根据信息直接调用服务。(注:服务的调用通过http(s)调用)
- 当某个服务仅需要调用其他服务,自身不提供服务调用时。在Eureka Client启动后会拉取Eureka Server的其他服务信息,需要调用时,在Eureka Client的本地缓存中获取信息,调用服务。
- Eureka Client通过向Eureka Serve发送心跳(默认每30秒)来续约服务的。 如果客户端持续不能续约,那么,它将在大约90秒内从服务器注册表中删除。注册信息和续订被复制到集群中的Eureka Serve所有节点。 以此来确保当前服务还“活着”,可以被调用。
- 来自任何区域的Eureka Client都可以查找注册表信息(每30秒发生一次),以此来确保调用到的服务是“活的”。并且当某个服务被更新或者新加进来,也可以调用到新的服务。
3、Eureka 自我保护模式
进入自我保护模式最直观的体现就是Eureka Server首页的警告,如下图红色:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7zrkbmzL-1596214225825)(C:\Users\CR553\Pictures\20190531200353344.png)]
默认情况下,如果Eureka Server在一定时间内没有接收到某个微服务实例的心跳,Eureka Server将会注销该实例(默认90秒)。但是当网络分区故障发生时,微服务与Eureka Server之间无法正常通信,这就可能变得非常危险了----因为微服务本身是健康的,此时本不应该注销这个微服务。
Eureka Server通过“自我保护模式”来解决这个问题----当Eureka Server节点在短时间内丢失过多客户端时(可能发生了网络分区故障),那么这个节点就会进入自我保护模式。一旦进入该模式,Eureka Server就会保护服务注册表中的信息,不再删除服务注册表中的数据(也就是不会注销任何微服务)。当网络故障恢复后,该Eureka Server节点会自动退出自我保护模式。
自我保护模式是一种对网络异常的安全保护措施。使用自我保护模式,而已让Eureka集群更加的健壮、稳定。
4、作为服务注册中心,Eureka比Zookeeper好在哪里
著名的CAP理论指出,一个分布式系统不可能同时满足C(一致性)、A(可用性)和P(分区容错性)。由于分区容错性在是分布式系统中必须要保证的,因此我们只能在A和C之间进行权衡。在此Zookeeper保证的是CP, 而Eureka则是AP。
Zookeeper保证CP
ZooKeeper(注:ZooKeeper是著名Hadoop的一个子项目,旨在解决大规模分 布式应用场景下,服务协调同步(Coordinate Service)的问题;它可以为同在一个分布式系统中的其他服务提供:统一命名服务、配置管理、分布式锁服务、集群管理等功能)是个伟大的开源项目,它 很成熟,有相当大的社区来支持它的发展,而且在生产环境得到了广泛的使用;但是用它来做Service发现服务解决方案则是个错误。
在分布式系统领域有个著名的 CAP定理(C- 数据一致性;A-服务可用性;P-服务对网络分区故障的容错性,这三个特性在任何分布式系统中不能同时满足,最多同时满足两个);ZooKeeper是个 CP的,即任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性;但是它不能保证每次服务请求的可用性(注:也就 是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。但是别忘了,ZooKeeper是分布式协调服务,它的 职责是保证数据(注:配置数据,状态数据)在其管辖下的所有服务之间保持同步、一致;所以就不难理解为什么ZooKeeper被设计成CP而不是AP特性 的了,如果是AP的,那么将会带来恐怖的后果(注:ZooKeeper就像交叉路口的信号灯一样,你能想象在交通要道突然信号灯失灵的情况吗?)。而且, 作为ZooKeeper的核心实现算法Zab,就是解决了分布式系统下数据如何在多个服务之间保持同步问题的。
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但是zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因网络问题使得zk集群失去master节点是较大概率会发生的事,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。
Eureka保证AP
在Eureka平台中,如果某台服务器宕机,Eureka不会有类似于ZooKeeper的选举leader的过程;客户端请求会自动切换 到新的Eureka节点;当宕机的服务器重新恢复后,Eureka会再次将其纳入到服务器集群管理之中;而对于它来说,所有要做的无非是同步一些新的服务 注册信息而已。所以,再也不用担心有“掉队”的服务器恢复以后,会从Eureka服务器集群中剔除出去的风险了。
Eureka看明白了这一点,因此在设计时就优先保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点**,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的**(不保证强一致性)。
除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用)
- 当网络稳定时,当前实例新的注册信息会被同步到其它节点中
因此, Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪。
负载均衡
什么是负载均衡
LB(Load Balance,负载均衡)是一种集群技术,它将特定的业务(网络服务、网络流量等)分担给多台网络设备(包括服务器、防火墙等)或多条链路,从而提高了业务处理能力,保证了业务的高可靠性。
为什么需要负载均衡
互联网的发展,业务流量越来越大并且业务逻辑也越来越复杂,单台机器的性能问题以及单点问题凸显了出来,因此需要多台机器来进行性能的水平扩展以及避免单点故障。但是要如何将不同的用户的流量分发到不同的服务器上面呢?早期的方法是使用DNS做负载,通过给客户端解析不同的IP地址,让客户端的流量直接到达各个服务器。但是这种方法有一个很大的缺点就是延时性问题,在做出调度策略改变以后,由于DNS各级节点的缓存并不会及时的在客户端生效,而且DNS负载的调度策略比较简单,无法满足业务需求,因此就出现了负载均衡。
负载均衡的原理
所谓四层就是基于IP+端口的负载均衡;七层就是基于URL等应用层信息的负载均衡;同理,还有基于MAC地址的二层负载均衡和基于IP地址的三层负载均衡。 换句换说,二层负载均衡会通过一个虚拟MAC地址接收请求,然后再分配到真实的MAC地址;三层负载均衡会通过一个虚拟IP地址接收请求,然后再分配到真实的IP地址;四层通过虚拟IP+端口接收请求,然后再分配到真实的服务器,七层通过虚拟的URL或主机名接收请求,然后再分配到真实的服务器。所谓的四到七层负载均衡,就是在对后台的服务器进行负载均衡时,依据四层的信息或七层的信息来决定怎么样转发流量。 比如四层的负载均衡,就是通过发布三层的IP地址(VIP),然后加四层的端口号,来决定哪些流量需要做负载均衡,对需要处理的流量进行NAT处理,转发至后台服务器,并记录下这个TCP或者UDP的流量是由哪台服务器处理的,后续这个连接的所有流量都同样转发到同一台服务器处理。七层的负载均衡,就是在四层的基础上(没有四层是绝对不可能有七层的),再考虑应用层的特征,比如同一个Web服务器的负载均衡,除了根据VIP加80端口辨别是否需要处理的流量,还可根据七层的URL、浏览器类别、语言来决定是否要进行负载均衡。举个例子,如果你的Web服务器分成两组,一组是中文语言的,一组是英文语言的,那么七层负载均衡就可以当用户来访问你的域名时,自动辨别用户语言,然后选择对应的语言服务器组进行负载均衡处理。负载均衡器通常称为四层交换机或七层交换机。四层交换机主要分析IP层及TCP/UDP层,实现四层流量负载均衡。七层交换机除了支持四层负载均衡以外,还有分析应用层的信息,如HTTP协议URI或Cookie信息。这里我们主要谈一下软件负载均衡中的我们最常用的四层个七层负载均衡。
所谓四层负载均衡,也就是主要通过报文中的目标地址和端口,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。以常见的TCP为例,负载均衡设备在接收到第一个来自客户端的SYN 请求时,即通过上述方式选择一个最佳的服务器,并对报文中目标IP地址进行修改(改为后端服务器IP),直接转发给该服务器。TCP的连接建立,即三次握手是客户端和服务器直接建立的,负载均衡设备只是起到一个类似路由器的转发动作。在某些部署情况下,为保证服务器回包可以正确返回给负载均衡设备,在转发报文的同时可能还会对报文原来的源地址进行修改。
所谓七层负载均衡,也称为“内容交换”,也就是主要通过报文中的真正有意义的应用层内容,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。以常见的TCP为例,负载均衡设备如果要根据真正的应用层内容再选择服务器,只能先代理最终的服务器和客户端建立连接(三次握手)后,才可能接受到客户端发送的真正应用层内容的报文,然后再根据该报文中的特定字段,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。负载均衡设备在这种情况下,更类似于一个代理服务器。负载均衡和前端的客户端以及后端的服务器会分别建立TCP连接。所以从这个技术原理上来看,七层负载均衡明显的对负载均衡设备的要求更高,处理七层的能力也必然会低于四层模式的部署方式。
负载均衡的作用
-
解决并发压力,提高应用处理性能(增加吞吐量,加强网络处理能力);
-
提供故障转移,实现高可用;
-
通过添加或减少服务器数量,提供网站伸缩性(扩展性);
-
安全防护;(负载均衡设备上做一些过滤,黑白名单等处理)
负载均衡的分类
DNS负载均衡,HTTP负载均衡,IP负载均衡,反向代理负载均衡、链路层负载均衡
负载均衡的算法
1、轮询法
将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载。
2、随机法
通过系统的随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问。由概率统计理论可以得知,随着客户端调用服务端的次数增多,
其实际效果越来越接近于平均分配调用量到后端的每一台服务器,也就是轮询的结果。
3、源地址哈希法
源地址哈希的思想是根据获取客户端的IP地址,通过哈希函数计算得到的一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是客服端要访问服务器的序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。
4、加权轮询法
不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载,加权轮询能很好地处理这一问题,并将请求顺序且按照权重分配到后端。
5、加权随机法
与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
6、最小连接数法
最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,它是根据后端服务器当前的连接情况,动态地选取其中当前
积压连接数最少的一台服务器来处理当前的请求,尽可能地提高后端服务的利用效率,将负责合理地分流到每一台服务器。
负载均衡的实现
1 - DNS域名解析负载均衡
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZpBmHyg3-1596214225827)(C:\Users\CR553\Pictures\导出图片\2.png)]
利用DNS处理域名解析请求的同时进行负载均衡是另一种常用的方案。在DNS服务器中配置多个A记录,每次域名解析请求都会根据负载均衡算法计算一个不同的IP地址返回,这样A记录中配置的多个服务器就构成一个集群,并可以实现负载均衡。
DNS域名解析负载均衡的优点是将负载均衡工作交给DNS,省略掉了网络管理的麻烦,缺点就是DNS可能缓存A记录,不受网站控制。事实上,大型网站总是部分使用DNS域名解析,作为第一级负载均衡手段,然后再在内部做第二级负载均衡。
2 - 数据链路层负载均衡
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w2HJPZlD-1596214225829)(C:\Users\CR553\Pictures\导出图片\1.png)]
数据链路层负载均衡是指在通信协议的数据链路层修改mac地址进行负载均衡。
这种数据传输方式又称作三角传输模式,负载均衡数据分发过程中不修改IP地址,只修改目的的mac地址,通过配置真实物理服务器集群所有机器虚拟IP和负载均衡服务器IP地址一样,从而达到负载均衡,这种负载均衡方式又称为直接路由方式(DR).
在上图中,用户请求到达负载均衡服务器后,负载均衡服务器将请求数据的目的mac地址修改为真是WEB服务器的mac地址,并不修改数据包目标IP地址,因此数据可以正常到达目标WEB服务器,该服务器在处理完数据后可以经过网管服务器而不是负载均衡服务器直接到达用户浏览器。
使用三角传输模式的链路层负载均衡是目前大型网站所使用的最广的一种负载均衡手段。在linux平台上最好的链路层负载均衡开源产品是LVS(linux virtual server)。
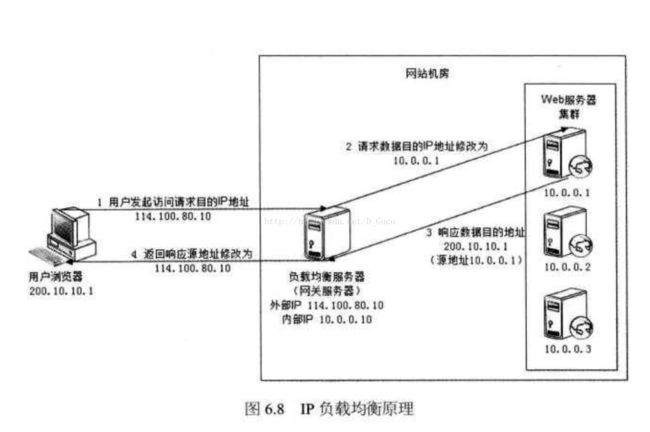
3 - IP负载均衡
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hR2stsXO-1596214225830)(C:\Users\CR553\Pictures\导出图片\3.png)]
IP负载均衡:即在网络层通过修改请求目标地址进行负载均衡。
用户请求数据包到达负载均衡服务器后,负载均衡服务器在操作系统内核进行获取网络数据包,根据负载均衡算法计算得到一台真实的WEB服务器地址,然后将数据包的IP地址修改为真实的WEB服务器地址,不需要通过用户进程处理。真实的WEB服务器处理完毕后,相应数据包回到负载均衡服务器,负载均衡服务器再将数据包源地址修改为自身的IP地址发送给用户浏览器。
这里的关键在于真实WEB服务器相应数据包如何返回给负载均衡服务器,一种是负载均衡服务器在修改目的IP地址的同时修改源地址,将数据包源地址改为自身的IP,即源地址转换(SNAT),另一种方案是将负载均衡服务器同时作为真实物理服务器的网关服务器,这样所有的数据都会到达负载均衡服务器。
IP负载均衡在内核进程完成数据分发,较反向代理均衡有更好的处理性能。但由于所有请求响应的数据包都需要经过负载均衡服务器,因此负载均衡的网卡带宽成为系统的瓶颈。
4 - HTTP重定向负载均衡
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dYe1IjkS-1596214225832)(C:\Users\CR553\Pictures\导出图片\4.png)]
HTTP重定向服务器是一台普通的应用服务器,其唯一的功能就是根据用户的HTTP请求计算一台真实的服务器地址,并将真实的服务器地址写入HTTP重定向响应中(响应状态吗302)返回给浏览器,然后浏览器再自动请求真实的服务器。
这种负载均衡方案的优点是比较简单,缺点是浏览器需要每次请求两次服务器才能拿完成一次访问,性能较差;使用HTTP302响应码重定向,可能是搜索引擎判断为SEO作弊,降低搜索排名。重定向服务器自身的处理能力有可能成为瓶颈。因此这种方案在实际使用中并不见多。
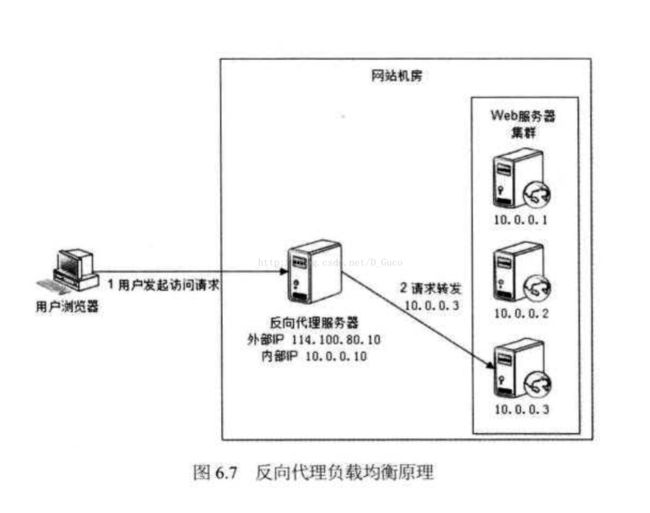
5 - 反向代理负载均衡
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-krada4XG-1596214225833)(C:\Users\CR553\Pictures\导出图片\5.png)]
传统代理服务器位于浏览器一端,代理浏览器将HTTP请求发送到互联网上。而反向代理服务器则位于网站机房一侧,代理网站web服务器接收http请求。
反向代理的作用是保护网站安全,所有互联网的请求都必须经过代理服务器,相当于在web服务器和可能的网络攻击之间建立了一个屏障。
除此之外,代理服务器也可以配置缓存加速web请求。当用户第一次访问静态内容的时候,静态内存就被缓存在反向代理服务器上,这样当其他用户访问该静态内容时,就可以直接从反向代理服务器返回,加速web请求响应速度,减轻web服务器负载压力。
另外,反向代理服务器也可以实现负载均衡的功能。
由于反向代理服务器转发请求在HTTP协议层面,因此也叫应用层负载均衡。优点是部署简单,缺点是可能成为系统的瓶颈。
Ribbon
什么是Ribbon
Ribbon is a client side load balancer which gives you a lot of control over the behaviour of HTTP and TCP clients. Feign already uses Ribbon, so if you are using @FeignClient then this section also applies.
-----摘自官网
Ribbon与负载均衡
负载均衡在业界有不少分类:(基本可见https://blog.csdn.net/xiaofeng10330111/article/details/85682513)
最常见的有软负载和硬负载,代表产品为nginx和F5.
另外一组分类为集中式负载和进程内负载,即服务端负载均衡和客户端负载均衡。这种分类下,nginx和F5都为集中式负载,Ribbon为进程内负载。
Ribbon是Spring Cloud框架中相当核心的模块,负责着服务负载调用,Ribbon也可以脱离SpringCloud单独使用。
另外Ribbon是客户端的负载均衡框架,即每个客户端上,独立维护着自身的调用信息统计,相互隔离;也就是说:Ribbon的负载均衡表现在各个机器上变现并不完全一致
Ribbon 也是整个组件框架中最复杂的一环,控制流程上为了保证服务的高可用性,有很多比较细节的参数控制,在使用的过程中,需要深入理清每个环节的处理机制,这样在问题定位上会高效很多。
Ribbon的作用
- 负载均衡
- 容错
- 多协议(HTTP,TCP,UDP)支持异步和反应模型
- 缓存和批处理
Ribbon核心原理

LoadBalancer–负载均衡器的核心
LoadBalancer 的职能主要有三个:
- 维护Sever列表的数量(新增、更新、删除等)
- 维护Server列表的状态(状态更新)
- 当请求Server实例时,能否返回最合适的Server实例
1.负载均衡器的内部基本实现原理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OVclYel2-1596214225834)(C:\Users\CR553\Pictures\loadB.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9XQwz8HJ-1596214225835)(C:\Users\CR553\Pictures\loadBalancer.png)]
- Server
Server 作为服务实例的表示,会记录服务实例的相关信息,如:服务地址,所属zone,服务名称,实例ID等
- ServerList
维护着一组Server实例列表,在应用运行的过程中,Ribbon通过ServerList中的服务实例供负载均衡器选择。ServerList维护列表可能在运行的过程中动态改变
- ServerStats
作为对应Server 的运行情况统计,一般是服务调用过程中的Server平均响应时间,累计请求失败计数,熔断时间控制等。一个ServerStats实例唯一对应一个Server实例
- LoadBalancerStats
作为 ServerStats实例列表的容器,统一维护
- ServerListUpdater
负载均衡器通过ServerListUpdater来更新ServerList,比如实现一个定时任务,每隔一段时间获取最新的Server实例列表
- Pinger
服务状态检验器,负责维护ServerList列表中的服务状态注意:Pinger仅仅负责Server的状态,没有能力决定是否删除
- PingerStrategy
定义以何种方式还检验服务是否有效,比如是按照顺序的方式还是并行的方式
- IPing
Ping,检验服务是否可用的方法,常见的是通过HTTP,或者TCP/IP的方式看服务有无认为正常的请求
2.如何维护Server列表?(新增、更新、删除)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wpObX6sF-1596214225836)(C:\Users\CR553\Pictures\1.jpg)]
Server列表的维护从实现方法上分为两类:
- 基于配置的服务列表
这种方式一般是通过配置文件,静态地配置服务器列表,这种方式相对而言比较简单,但并不是意味着在机器运行的时候就一直不变。netflix 在做Spring cloud 套件时,使用了分布式配置框架netflix archaius ,archaius 框架有一个特点是会动态的监控配置文件的变化,将变化刷新到各个应用上。也就是说,当我们在不关闭服务的情况下,如果修改了基于配置的服务列表时, 服务列表可以直接刷新
- 结合服务发现组件(如Eureka)的服务注册信息动态维护服务列表
基于Spring Cloud框架下,服务注册和发现是一个分布式服务集群必不可少的一个组件,它负责维护不同的服务实例(注册、续约、取消注册)。
3.负载均衡器如何维护服务实例的状态?
Ribbon负载均衡器将服务实例的状态维护托交给Pinger、 PingerStrategy、IPing 来维护,具体交互模式如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8wgzEHiw-1596214225837)(C:\Users\CR553\Pictures\2.jpg)]
4.如何从服务列表中挑选一个合适的服务实例?
(1)服务实例容器:ServerList的维护
负载均衡器通过 ServerList来统一维护服务实例,具体模式如上图,基础的接口定义如下:
/**
* Interface that defines the methods sed to obtain the List of Servers
* @author stonse
*
* @param
*/
public interface ServerList<T extends Server> {
//获取初始化的服务列表
public List<T> getInitialListOfServers();
/**
* Return updated list of servers. This is called say every 30 secs
* (configurable) by the Loadbalancer's Ping cycle
* 获取更新后的的服务列表
*/
public List<T> getUpdatedListOfServers();
}
在Ribbon的实现中,在ServerList(负责维护服务实例,并使用ServerListFilter过滤器过滤出符合要求的服务实例列表List)中,维护着Server的实例,并返回最新的List集合,供LoadBalancer使用 。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ynetPEEz-1596214225838)(C:\Users\CR553\Pictures\3.jpg)]
(2)服务实例列表过滤器ServerListFilter
传入一个服务实例列表,过滤出满足过滤条件的服务列表
public interface ServerListFilter<T extends Server> {
public List<T> getFilteredListOfServers(List<T> servers);
}
Ribbon 的默认ServerListFilter实现1:ZoneAffinityServerListFilter
Ribbon默认采取了区域优先的过滤策略,即当Server列表中,过滤出和当前实例所在的区域(zone)一致的server列表
Ribbon 的ServerListFilter实现2:ZonePreferenceServerListFilter
ZonePreferenceServerListFilter 集成自 ZoneAffinityServerListFilter,在此基础上做了拓展,在 返回结果的基础上,再过滤出和本地服务相同区域(zone)的服务列表。
当指定了当前服务的所在Zone,并且 ZoneAffinityServerListFilter 没有起到过滤效果时,ZonePreferenceServerListFilter会返回当前Zone的Server列表。
Ribbon 的ServerListFilter实现3:ServerListSubsetFilter
这个过滤器作用于当Server数量列表特别庞大时(比如有上百个Server实例),这时,长时间保持Http链接也不太合适,可以适当地保留部分服务,舍弃其中一些服务,这样可使释放没必要的链接。
此过滤器也是继承自 ZoneAffinityServerListFilter,在此基础上做了拓展,在实际使用中不太常见。
(3)LoadBalancer选择服务实例 的流程
LoadBalancer的核心功能是根据负载情况,从服务列表中挑选最合适的服务实例。LoadBalancer内部采用了如下图所示的组件完成:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QMRU4gSF-1596214225839)(C:\Users\CR553\Pictures\4.jpg)]
LoadBalancer 选择服务实例的流程
通过ServerList获取当前可用的服务实例列表;
通过ServerListFilter将步骤1 得到的服务列表进行一次过滤,返回满足过滤器条件的服务实例列表;
应用Rule规则,结合服务实例的统计信息,返回满足规则的某一个服务实例;
通过上述的流程可以看到,实际上,在服务实例列表选择的过程中,有两次过滤的机会:第一次是首先通过ServerListFilter过滤器,另外一次是用过IRule 的选择规则进行过滤。
服务调用
服务间调用的几种方式
使用Spring Cloud开发微服务时,在服务消费者调用服务提供者时,底层通过HTTP Client 的方式访问。但实际上在服务调用时,有主要以下来实现:
使用JDK原生的URLConnection;
Apache提供的HTTP Client;
Netty提供的异步HTTP Client;
Spring提供的RestTemplate。
Spring Cloud的Spring Cloud Open Feign相对是最方便与最优雅的,使Feign支持Spring MVC注解的同时并整合了Ribbon。
OpenFeign
Feign概述
Feign 是一个声明式的 Web Service 客户端。它的出现使开发 Web Service 客户端变得很简单。使用 Feign 只需要创建一个接口加上对应的注解,比如:@FeignClient 注解。 Feign 有可插拔的注解,包括 Feign 注解和 AX-RS 注解。Feign 也支持编码器和解码器,Spring Cloud Open Feign 对 Feign 进行增强支持 Spring Mvc 注解,可以像 Spring Web 一样使用 HttpMessageConverters 等。
Feign 是一种声明式、模板化的 HTTP 客户端。在 Spring Cloud 中使用 Feign,可以做到使用 HTTP 请求访问远程服务,就像调用本地方法一样的,开发者完全感知不到这是在调用远程方法,更感知不到在访问 HTTP 请求。接下来介绍一下 Feign 的特性,具体如下:
- 可插拔的注解支持,包括 Feign 注解和AX-RS注解。
- 支持可插拔的 HTTP 编码器和解码器。
- 支持 Hystrix 和它的 Fallback。
- 支持 Ribbon 的负载均衡。
- 支持 HTTP 请求和响应的压缩。Feign 是一个声明式的 WebService 客户端,它的目的就是让 Web Service 调用更加简单。它整合了 Ribbon 和 Hystrix,从而不需要开发者针对 Feign 对其进行整合。Feign 还提供了 HTTP 请求的模板,通过编写简单的接口和注解,就可以定义好 HTTP 请求的参数、格式、地址等信息。Feign 会完全代理 HTTP 的请求,在使用过程中我们只需要依赖注入 Bean,然后调用对应的方法传递参数即可。
Feign 工作原理
- 在开发微服务应用时,我们会在主程序入口添加 @EnableFeignClients 注解开启对 Feign Client 扫描加载处理。根据 Feign Client 的开发规范,定义接口并加 @FeignClients 注解。
- 当程序启动时,会进行包扫描,扫描所有 @FeignClients 的注解的类,并将这些信息注入 Spring IOC 容器中。当定义的 Feign 接口中的方法被调用时,通过JDK的代理的方式,来生成具体的 RequestTemplate。当生成代理时,Feign 会为每个接口方法创建一个 RequetTemplate 对象,该对象封装了 HTTP 请求需要的全部信息,如请求参数名、请求方法等信息都是在这个过程中确定的。
- 然后由 RequestTemplate 生成 Request,然后把 Request 交给 Client 去处理,这里指的 Client 可以是 JDK 原生的 URLConnection、Apache 的 Http Client 也可以是 Okhttp。最后 Client 被封装到 LoadBalanceclient 类,这个类结合 Ribbon 负载均衡发起服务之间的调用。
服务降级
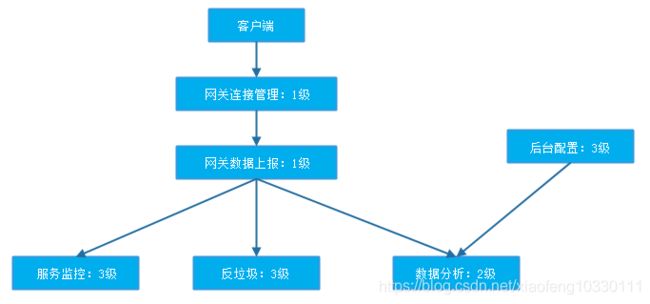
1.服务分级
对每个微服务进行等级管理后,降级一般是从最外围、等级最低的服务开始。以移动医疗系统为例,简单分级如下:
2.服务熔断
降级有个类似的词称为服务熔断,当某个异常条件被触发,直接熔断整个服务,而不是一直等到此服务超时。
服务降级就是当某个服务熔断后,服务端准备一个本地的回退回调,返回一个缺省值。
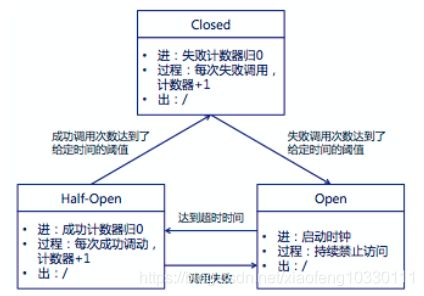
一个基本的服务熔断器结构在实现上一般有三个状态机:
(1)Closed:熔断器关闭状态,调用失败次数积累,到了阈值(或一定比例)则启动熔断机制;
(2)Open:熔断器打开状态,此时对下游的调用都内部直接返回错误,不走网络,但设计了一个时钟选项,默认的时钟达到了一定时间(这个时间一般设置成平均故障处理时间,也就是MTTR),到了这个时间,进入半熔断状态;
(3)Half-Open:半熔断状态,允许定量的服务请求,如果调用都成功(或一定比例)则认为恢复了,关闭熔断器,否则认为还没好,又回到熔断器打开状态;
3.服务降级与服务熔断的区别
- 触发原因不大一样。服务熔断一般是某个下游服务发生故障引起,而服务降级一般是从整体 负荷考虑。
- 管理目标层次不一样。熔断是一个框架级的处理,每个服务都需要,无层级之分,而降级一般需要对业务有层级之分。
Hystrix
一 、Spring Cloud Hytrix基本概述
在软件架构领域,容错特指容忍并防范局部错误,不让这种局部错误不断扩大。我们在识别风险领域,风险可以分为已知风险和未知风险,容错直接应对的就是已知风险,这就要求针对的场景是:系统之间调用延时超时、线程的数量急剧飙升导致CPU使用率升高、集群服务器磁盘被打满等等。面对容错,我们一般都会要求提供降级方案,而且强调不可进行暴力降级(比如把整个论坛功能降掉直接给用户展现一个大白板),而是将一部分数据缓存起来,也就是要有拖底数据。
在一个分布式系统中,必然会有部分系统的调用会失败。Hystrix是一个通过添加超时容错和失败容错逻辑来帮助你控制这些分布式系统的交互。Hystrix通过隔离服务之间的访问,阻止他们之间的级联故障以及提供后背选项来实现进行丢底方案,从而提高系统的整体弹性。
Hystrix对应的中文名字是“豪猪”,豪猪周身长满了刺,能保护自己不受天敌的伤害,代表了一种防御机制,Hystrix提供了熔断、隔离、Fallback、cache、监控等功能,能够在一个、或多个依赖同时出现问题时保证系统依然可用。
Hytrix官网描述:
Introduction:
Hystrix is a latency and fault tolerance library designed to isolate points of access to remote systems,
services and 3rd party libraries,
stop cascading failure and enable resilience in complex distributed systems where failure is inevitable.
大意是:Hytrix是一个延迟和容错库,旨在隔离远程系统、服务和第三方库,阻止级联故障,在复杂的分布式系统中实现恢复能力。
二 、Spring Cloud Hytrix概述设计目标
查看Hytrix官网https://github.com/Netflix/Hystrix/wiki中对设计目标有如下描述:
Hystrix is designed to do the following:
1.Give protection from and control over latency and failure from dependencies accessed
(typically over the network) via third-party client libraries.
2.Stop cascading failures in a complex distributed system.
3.Fail fast and rapidly recover.
4.Fallback and gracefully degrade when possible.
5.Enable near real-time monitoring, alerting, and operational control.
翻译如下:
1.通过客户端库对延迟和故障进行保护和控制。
2.在一个复杂分布式系统中防止级联故障。
3.快速失败和迅速恢复。
4.在合理情况下回退和优雅降级。
5.开启近实时监控、告警和操作控制。
三、Spring Cloud Hytrix解决的主要内容
(一)隔离
隔离的基本要求是:限制调用分布式服务的资源使用,某一个调用的服务出现问题不会影响其他服务调用。Spring Cloud Hytrix下针对隔离主要指的是线程池隔离和信号量隔离。如下图所示,可以很明显的说明信号量隔离和线程池隔离的主要区别:线程池方式下,业务请求线程和执行依赖的服务线程不是同一个线程;信号量方式下业务请求线程和执行依赖的线程是同一个线程。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-opCzxDJ0-1596214225840)(C:\Users\CR553\Pictures\291.png)]
1.线程和线程池
线程隔离指每个服务都为一个个独立的线程组,当某个服务出现问题时,不会导致整个服务瘫痪。由于线程隔离会带来线程开销,有些场景(比如无网络请求场景)可能会因为用开销换隔离得不偿失,为此hystrix提供了信号量隔离,当服务的并发数大于信号量阈值时将进入fallback。
如下图,客户端(第三方,网络调用等)依赖和请求线程运行在不同的线程上,可以将他们从调用线程隔离开来,这样调用者就可以从一个耗时太长的依赖中隔离,也可以为不同的请求开启不同的线程池,彼此之间不相互干扰。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n6iiUl92-1596214225841)(C:\Users\CR553\Pictures\292.png)]
传统上,我们在实现线程池隔离的手段上,一般有以下两种方式:
- 方式一:使用一个大的线程池,固定线程池的大小,比如1000,通过权重的思路为某个方法分配一个固定大小的线程数,比如为某个方法请求分配了10个线程,按照实现方式有“保守型”和“限制性”,具体见以后博客中和github中的代码举例。
- 方式二:利用ConcurrentHashMap来存储线程池,key是方法名,值是每个方法对应的一个ThreadPool。当请求到来的时候,我们获取方法名,然后直接从Map对象中取到响应的线程池去处理。
对于方法一而言,严格意义上讲,它并不属于线程池隔离,因为它只有一个公共的线程池,然后来让大家瓜分,不过也达到了隔离的效果。在Spring Cloud Hytrix的线程池隔离上,我们使用的是方式二。对于以上两种方式,线程池的粒度都是作用在方法上,我们可以结合实际情况也可以按组来分。
线程隔离的好处
整个应用在客户端调用失效的情况下也能健康的运行,线程池能够保证这个线程的失效不会影响应用的运行。当失效的客户端调用回复的时候,这个线程池也会被清理并且应用会立马回复健康,比tomcat那种长时间的恢复要好很多。简而言之,线程隔离能够允许在不引起中断的情况下优雅的处理第三方调用的各种问题。
线程隔离的缺点
主要缺点是增加了上下文切换的开销,每个执行都涉及到队列,调度和上下文切换。不过NetFix在设计这个系统的时候,已经决定接受这笔开销,以换取他的好处。对于不依赖网络访问的服务,比如只依赖内存缓存,就不适合用线程池隔离技术,而是采用信号量隔离。
2.信号量隔离
可以使用信号量(或者计数器)来限制当前依赖调用的并发数,而不是使用线程池或者队列。如果客户端是可信的,且能快速返回,可以使用信号量来代替线程隔离,降低开销。信号量的大小可以动态调节,线程池却不行。
HystrixCommand和HystrixObserverCommand提供信号量隔离在下面两个地方:
- Fallback:当Hystrix检索fallback的时候,他心总是调用tomcat线程上执行此操作
如果你设置execution.isolation.strategy为SEMAPHORE的时候,Hystrix会使用信号量代替线程池去限制当前 - 调用Command的并发数。
对于不依赖网络访问的服务,就不适合使用线程池隔离,而是采用信号量隔离。
(二)优雅的降级机制
超时降级、资源不足时(线程或信号量)降级,降级总之是一种退而求其次的方式,所谓降级,就是指在Hystrix执行费核心链路功能失败的情况下,我们应该如何返回的问题,根据业务场景的不同,一般采用以下两种模式进行降级:
- 第一种:(最常用)如果服务失败,则我们通过fallback进行降级,返回静态值。
- 第二种:调用备选方案
具体降级回退方案如:Fail Fast(快速失败)、Fail Silent(无声失败)、Fallback:Static(返回默认值)、Fallback:Stubbed(自己组装一个值返回)、Fallback:Cache via Network(利用远程缓存)、Primary + Secondary with fallback(主次方式回退)
这里需要注意回退处理方式不适合的场景,如以下三种场景我们不可以使用回退处理:
- 写操作
- 批处理
- 计算
(三)熔断器
当失败率达到阀值自动触发降级(如因网络故障/超时造成的失败率高),熔断器触发的快速失败会进行快速恢复,类似于电闸。下图是基本源码中的一个处理流程图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u7EdvJ0L-1596214225842)(C:\Users\CR553\Pictures\293.png)]
断路器打开还是关闭的步骤如下
- 假定请求的量超过预定的阈值(circuitBreakerRequestVolumeThreshold)
- 再假定错误百分比超过了设定的百分比(circuitBreakerErrorThresholdPercentage)
- 断路器会从close状态到open状态
- 当打开的状态,会短路所有针对该断路器的请求
- 过了一定时间(circuitBreakerSleepWindowInMilliseconds(短路超过一定时间会重新去请求)),下一
- 个请求将通过,不会被短路(当前是half-open状态)。如果这个请求失败了,则断路器在睡眠窗口期间返回open状态,如果请求成功,则断路器返回close状态,并重新回到第一步逻辑判断。
(四)缓存
提供了请求缓存、请求合并实现。
1.Hystrix缓存策略的命令执行流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3ruErTyA-1596214225843)(C:\Users\CR553\Pictures\294.png)]
2.请求合并实现
为什么要进行请求合并?举个例子,有个矿山,每过一段时间都会生产一批矿产出来(质量为卡车载重量的1/100),卡车可以一等到矿产生产出来就马上运走矿产,也可以等到卡车装满再运走矿产,
前者一次生产对应卡车一次往返,卡车需要往返100次,而后者只需要往返一次,可以大大减少卡车往返次数。显而易见,利用请求合并可以减少线程和网络连接,开发人员不必单独提供一个批量请求接口就可以完成批量请求。
在Hystrix中进行请求合并也是要付出一定代价的,请求合并会导致依赖服务的请求延迟增高,延迟的最大值是合并时间窗口的大小,默认为10ms,当然我们也可以通过hystrix.collapser.default.timerDelayInMilliseconds属性进行修改,如果请求一次依赖服务的平均响应时间是20ms,那么最坏情况下(合并窗口开始是请求加入等待队列)这次请求响应时间就会变成30ms。在Hystrix中对请求进行合并是否值得主要取决于Command本身,高并发度的接口通过请求合并可以极大提高系统吞吐量,从而基本可以忽略合并时间窗口的开销,反之,并发量较低,对延迟敏感的接口不建议使用请求合并。
请求合并的流程图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JeBnCqbX-1596214225843)(C:\Users\CR553\Pictures\295.png)]
可以看出Hystrix会把多个Command放入Request队列中,一旦满足合并时间窗口周期大小,Hystrix会进行一次批量提交,进行一次依赖服务的调用,通过充写HystrixCollapser父类的mapResponseToRequests方法,将批量返回的请求分发到具体的每次请求中。
(五)支持实时监控、报警、控制(修改配置)
通过仪表盘等进行统计后,从而进行实时监控、报警、控制,最终依据这些来修改配置,得到最佳的选择。
四、Spring Cloud Hytrix工作流程介绍
基本流程图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PL6rnVFe-1596214225844)(C:\Users\CR553\Pictures\296.png)]
-
创建HystrixCommand或者HystrixObservableCommand对象。用来表示对以来服务的请求操作。从命名就能看的出来,使用的是命令模式,其中HystrixCommand返回的是单个操作结果,HystrixObservableCommand返回多个结果
-
命令执行,共有4中方法执行命令:
execute():用户执行,从依赖的服务里返回单个结果或抛出异常 queue():异步执行,直接返回一个Future对象 observe():放回observable对象,代表了多个结果,是一个Hot Observable toObservable():返回Observable对象,但是是一个 Cold Observable(Hystrix大量的使用了RxJava,想更容易的理解Hystrix的,请自行百度RxJava进行阅读。) -
结果是否被缓存。如果已经启用了缓存功能,且被命中,那么缓存就会直接以Observable对象返回
-
断路器是否已打开,没有命中缓存,在执行命令前会检查断路器是否已打开:
断路器已打开,直接执行fallback
断路器关闭,继续往下执行
- 线程池And信号量Or请求队列是否已被占满 如果与该命令有关的线程池和请求队列,或者信号量已经被占满,就直接执行fallback
- 执行HystrixObservableCommand.construct () 或 HystrixCommand.run() 方法。如果设置了当前执行时间超过了设置的timeout,则当前处理线程会抛出一个TimeoutyException,如果命令不在自身线程里执行,就会通过单独的计时线程来抛出异常,Hystrix会直接执行fallback逻辑,并忽略run或construct的返回值。
- 计算断路器的健康值。
- fallback处理。
- 返回成功的响应。
五、仪表盘讲解
Spring Cloud Hystrix Dashboard是一个可以监控HystrixCommand的可视化图形界面,由于某种原因,如网络延迟、服务故障等,这时候可以借助dashboard提供的可视化界面监控各个Hystrix执行的成功率、调用成功数、失败数量、最近十分钟的流量图等等,根据这些数据我们就可以进行错误排查以及进行服务的优化等。Hystrix Dashboard只能对单个服务进行监控,实际项目中,服务通常集群部署,这时候可以借助Turbine进行多个服务的监控。
(一)监控单体应用
不管是监控单体应用还是Turbine集群监控,我们都需要一个Hystrix Dashboard,当然我们可以在要监控的单体应用上继续添加功能,让它也具备仪表盘的功能,但是这样并不符合我们微服务的思想,所以,Hystrix仪表盘我还是单独创建一个新的工程专门用来做Hystrix Dashboard。Hystrix Dashboard仪表盘是根据系统一段时间内发生的请求情况来展示的可视化面板,这些信息时每个HystrixCommand执行过程中的信息,这些信息是一个指标集合和具体的系统运行情况。如Hystrix Dashboard界面图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wBzxKtWU-1596214225845)(C:\Users\CR553\Pictures\297.png)]
输入相关数据,得到如下仪表盘:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Sl6TNapb-1596214225847)(C:\Users\CR553\Pictures\298.png)]
(二)Turbine集群监控
在实际应用中,我们要监控的应用往往是一个集群,这个时候我们就得采取Turbine集群监控了。Turbine有一个重要的功能就是汇聚监控信息,并将汇聚到的监控信息提供给Hystrix Dashboard来集中展示和监控。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dopwDoyv-1596214225847)(C:\Users\CR553\Pictures\299.png)]
在实际项目中,这种实时监控有点耗性能,通常采用消息中间件如RabbitMQ等,我们接口调用把Hystrix的一些信息收集到RabbitMQ中,然后Turbine从RabbitMQ中获取监控的数据。
服务网关
网关三大概念
-
路由: 路由是构建网关的基本模块,它由ID,目标URI,一系列的断言和过滤器组成,如果断言为true则匹配该路由
-
断言: 参考的是java8的java.util.function.Predicate 开发人员可以匹配到HTTP请求中的所有内容(例如请求头或请求参数),如果 请求与断言相匹配则进行路由
-
过滤: 指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改
核心逻辑: 路由转发+执行过滤器链
什么是服务网关
服务网关是统一管理API的一个网络关口、通道,是整个微服务平台所有请求的唯一入口,所有的客户端和消费端都通过统一的网关接入微服务,在网关层处理所有的非业务功能。
1、路由转发:接收一切外界请求,转发到后端的微服务上去;
2、过滤器:在服务网关中可以完成一系列的横切功能,例如权限校验、限流以及监控等,
这些都可以通过过滤器完成(其实路由转发也是通过过滤器实现的)。
为什么需要服务网关
上述所说的横切功能(以权限校验为例)可以写在三个位置:
- 每个服务自己实现一遍
- 写到一个公共的服务中,然后其他所有服务都依赖这个服务
- 写到服务网关的前置过滤器中,所有请求过来进行权限校验
第一种,缺点太明显,基本不用;
第二种,相较于第一点好很多,代码开发不会冗余,但是有两个缺点:
-
由于每个服务引入了这个公共服务,那么相当于在每个服务中都引入了相同的权限校验的代码,使得每个服务的jar包大小无故增加了一些,尤其是对于使用docker镜像进行部署的场景,jar越小越好;
-
由于每个服务都引入了这个公共服务,那么我们后续升级这个服务可能就比较困难,而且公共服务的功能越多,升级就越难,而且假设我们改变了公共服务中的权限校验的方式,想让所有的服务都去使用新的权限校验方式,我们就需要将之前所有的服务都重新引包,编译部署。
而服务网关恰好可以解决这样的问题:
将权限校验的逻辑写在网关的过滤器中,后端服务不需要关注权限校验的代码,所以服务的jar包中也不会引入权限校验的逻辑,不会增加jar包大小;
如果想修改权限校验的逻辑,只需要修改网关中的权限校验过滤器即可,而不需要升级所有已存在的微服务。
网关的作用
微服务提供的API粒度与客户端的要求不一定完全匹配,微服务一般提供细粒度的API,这意味着客户端通常需要与多个服务进行交互,网关要起到客户端与微服务间的隔离作用,随着业务需求的变化和时间的演进,网关背后的各个微服务的划分和实现可能需要做相应的调整和升级,这种调整和升级要求对客户端透明。
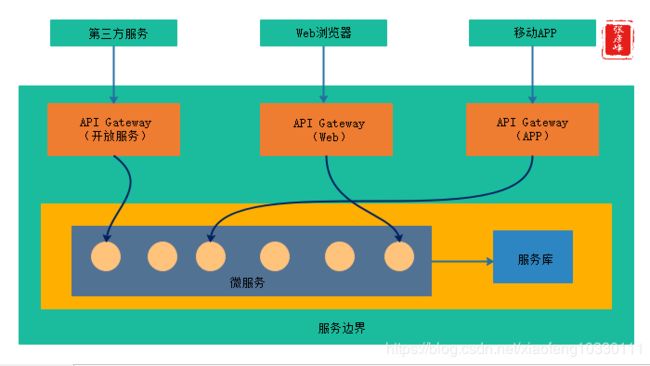
API网关的作用主要体现在以下三个方面:
-
解耦:API网关使客户端和服务器端在调用关系和部署环境上进行解耦,向客户端隐藏了应用如何被划分到微服务的细节。
-
API优化:要求对每个客户端提供最优的API,在多客户端场景中,对于同一个业务请求,不同的客户端一般需要不同的数据。
-
简化调用过程:可以对返回数据进行处理,API网关减少了请求往返的次数,从而简化客户端的调用,提高服务访问的性能。
但是需要注意的是,API网关也增加了系统的复杂性和响应时间,通过API网关也多了一层网络跳转,但是我们认为API网关模式的缺点相比优点是微不足道的。
网关的功能
网关的基本功能基本包含五点,具体细分如下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tmhie2t4-1596214225848)(C:\Users\CR553\Pictures\304.png)]
-
功能1-NIO接入和异步接出:由于API网关作为客户端和微服务之间提供了桥梁,增加了一层网络跳转,为了解决网络跳转带来的性能影响,在实现上需要提供NIO接入和异步接出功能。
-
功能2-报文格式转换:API网关作为单一入口,可构建异构系统,通过协议转换整合后基于REST、AMQP和Dubbo等不同风格和实现技术的微服务。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VTmf2nct-1596214225849)(C:\Users\CR553\Pictures\305.png)]
-
功能3-安全性控制:API网关是统一管理安全性的绝佳场所,可以将认证的部分抽离到网关层,然后微服务系统无需关注认证的逻辑只关注自身业务即可。
-
功能4-访问控制:需要控制客户端的访问次数和访问频率等功能。
-
功能5-业务路由支持:可在网关层制定灵活的路由策略,对于特定API可设置白名单、路由规则等限制,非业务功能的配置及变更在网关层单独操作。
Zuul和GateWay
目前能和spring cloud体系紧密集成的有两种API网关:zuul(zuul1)和spring cloud gateway。
先来看下zuul,目前zuul有两个版本:zuul1和zuul2,目前spring cloud只集成了zuul1,zuul2是Netflix在2018年5月推出,它最大的特点就是支持异步调用 (zuul1仅支持同步) ,可惜springcloud暂时没有计划集成zuul2,而且还推出spring cloud gateway来替代zuul1。
来看下zuul1的编程模型(同步阻塞)
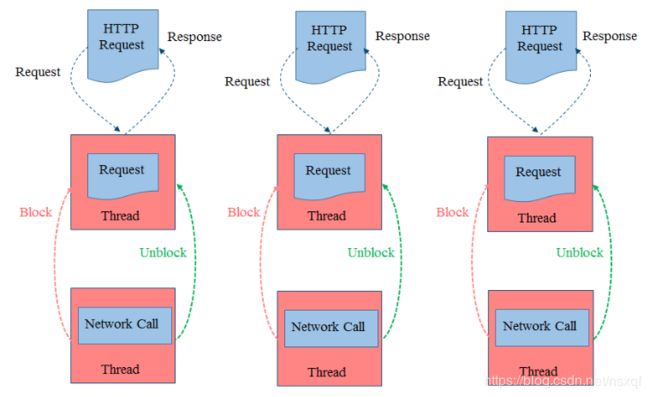
本质上就是一个同步 Servlet,每来一个请求,zuul会专门分配一个线程去处理,然后转发到后端服务,后端再启线程处理请求,后端处理时网关的线程会阻塞,当请求数量比较大时,很容易造成线程池被沾满而无法接受新的请求,Netflix 为此还专门研发了Hystrix熔断组件来解决慢服务耗尽资源问题。
zuul2的编程模型(异步非阻塞)
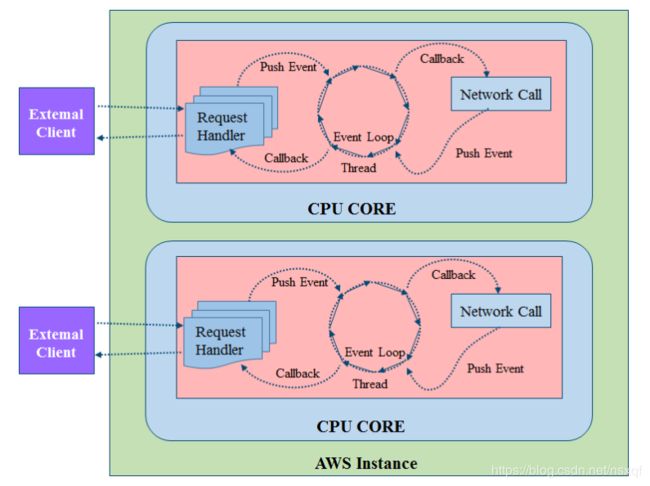
zuul2是基于Netty实现的异步非阻塞编程模型,一般异步模式的本质都是使用队列 Queue(或称总线 Bus)。网关中会有一个队列专门处理用户请求,一个队列专门负责后端服务调用,中间有个事件环线程 (Event Loop Thread)同时监听两个队列,它的主要作用是将请求转发给后端,并将后端服务的处理结果返回给客户端,用队列的形式减轻了前端请求数量的压力。
zuul1和zuul2对比:
| zuul1 | zuul2 | |
|---|---|---|
| 优势 | 模型简单,跟踪调试方便。 | 线程相对较少,对cpu、内存的开销少。可以接受相对较大的连接数。 |
| 劣势 | cpu、内存消耗相对较大。IO阻塞容器导致线程池被耗尽。 | 由于是通过事件环线程监听的异步处理方式,没有明确的请求链路,很难进行断点联调。ThreadLocal机制无法工作。 |
| 性能 | 950.57 次 /s(单核) | 大致比zuul1好20%左右 |
| 使用场景 | 适用于计算密集型 (CPU bound) 应用场景 | 适用于 IO 密集型 (IO bound) 场景 |
Zuul1 同步编程模型简单,门槛低,开发运维方便,容易调试定位问题。Zuul2 门槛高,调试不方便。 Zuul1 监控埋点容易,比如和调用链监控工具 CAT 集成,如果你用 Zuul2 的话,CAT 不好埋点是个问题。 Zuul1 已经开源超过 6 年,稳定成熟,坑已经被踩平。Zuul2 刚开源很新,实际落地案例不多,难说有 bug 需要踩坑。 大部分公司达不到 Netflix 那个量级,Netflix 是要应对每日千亿级流量,它们才挖空心思搞异步,一般公司亿级可能都不到,Zuul1 绰绰有余。 Zuul1 可以集成 Hystrix 熔断组件,可以部分解决后台服务慢阻塞网关线程的问题。 Zuul1 可以使用 Servlet 3.0 规范支持的 AsyncServlet 进行优化,可以实现前端异步,支持更多的连接数,达到和 Zuul2 一样的效果,但是不用引入太多异步复杂性。
Spring Cloud Gateway构建于 Spring 5+,基于 Spring Boot 2.x 响应式的、非阻塞式的 API。同时,它支持 websockets,和 Spring 框架紧密集成,开发体验相对来说十分不错。由于zuul2没有被spring cloud所集成,所以拿zuul1与spring cloud gateway做一些简单的比较。
| springcloudgateway | zuul | |
|---|---|---|
| 基本介绍 | Spring Cloud Gateway是Spring官方基于Spring 5.0,Spring Boot 2.0和Project Reactor等技术开发的网关,旨在为微服务架构提供一种简单而有效的统一的API路由管理方式。Spring 用其替代Netflix ZUUL,其不仅提供统一的路由方式,并且基于Filter链的方式提供了网关基本的功能,例如:安全,监控/埋点,和限流等。 | Zuul1 是基于 Servlet 框架构建,采用的是阻塞和多线程方式,即一个线程处理一次连接请求,这种方式在内部延迟严重、设备故障较多情况下会引起存活的连接增多和线程增加的情况发生。 |
| 性能 | WebFlux 模块的名称是 spring-webflux,名称中的 Flux 来源于 Reactor 中的类 Flux。Spring webflux 有一个全新的非堵塞的函数式 Reactive Web 框架,可以用来构建异步的、非堵塞的、事件驱动的服务,在伸缩性方面表现非常好。使用非阻塞API。 Websockets得到支持,并且由于它与Spring紧密集成。 | 本文的Zuul,指的是Zuul 1.x,是一个基于阻塞io的API Gateway。Zuul已经发布了Zuul 2.x,基于Netty,也是非阻塞的,支持长连接,但Spring Cloud暂时还没有整合计划。 |
| 源码维护组织 | spring-cloud-Gateway是spring旗下spring-cloud的一个子项目。还有一种说法是因为zuul2连续跳票和zuul1的性能表现不是很理想,所以催生了spring孵化Gateway项目。 |
zuul则是netflix公司的项目,只是spring将zuul集成在spring-cloud中使用而已。关键目前spring不打算集成zuul2.x。 |
| 版本 | 基于springboot2.0 | springboot1.x |
配置中心
配置中心是什么
集中式配置是将应用系统中对配置信息的管理作为一个新的应用功能模块,区别与传统的配置信息分散到系统各个角落方式,进行集中统一管理,并且提供额外功能。尤其是在微服务架构中,是不可或缺组件,甚至是必要组件之一。
配置中心要求具备的基本功能
配置中心应该剧本具备以下基本功能,具体如图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zawkvBLx-1596214225851)(C:\Users\CR553\Pictures\306.png)]
配置中心基本流转图和支撑体系分析
具体可如图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VhpsWIuk-1596214225851)(C:\Users\CR553\Pictures\307.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wdy4PQTb-1596214225852)(C:\Users\CR553\Pictures\308.png)]
(四)多种配置中心的选择与对比方案
| 具体对比分类 | 具体对比项 | 重要程度 | Spring Cloud Config | Ctrip Apollo |
|---|---|---|---|---|
| 功能特性 | 静态配置管理 | 高 | 基于file | 支持 |
| 动态配置管理 | 高 | 支持 | 支持 | 支持 |
| 统一管理 | 高 | 无,需要git、数据库等 | 无 | 支持 |
| 多维度管理 | 中 | 无,需要git、数据库等 | 无 | 支持 |
| 变更管理 | 高 | 无,需要git、数据库等 | 无 | 无 |
| 本地配置缓存 | 高 | 无 | 无 | 支持 |
| 配置更新策略 | 中 | 无 | 无 | 无 |
| 配置锁 | 中 | 支持 | 不支持 | 不支持 |
| 配置校验 | 中 | 无 | 无 | 无 |
| 配置生效时间 | 高 | 重启生效,手动刷新 | 手动刷新生效 | 实时 |
| 配置更新推送 | 高 | 需要手动触发 | 需要手动触发 | 支持 |
| 配置定时拉取 | 高 | 无 | 无 | 配置更新目前依赖事件驱动,client重启或server推送操作 |
| 用户权限管理 | 中 | 无,需要git、数据库等 | 无 | 支持 |
| 授权、审核、审计 | 中 | 无,需要git、数据库等 | 无 | 操作记录有赖数据库,但无查询接口 |
| 配置版本管理 | 高 | git | 无 | 无,需要git、数据库等 |
| 配置合规检测 | 高 | 不支持 | 不支持 | |
| 实例配置监控 | 高 | 需要结合Spring Admin | 不支持 | 支持,可以查看每个配置在哪台机器上加载 |
| 灰度发布 | 中 | 不支持 | 不支持 | 不支持部分更新 |
| 告警通知 | 中 | 不支持 | 不支持 | 支持邮件方式告警 |
| 统计报表 | 中 | 不支持 | 不支持 | 不支持 |
| 依赖关系 | 高 | 不支持 | 不支持 | 不支持 |
| 技术路线 | 支持Spring Boot | 高 | 原生支持 | 支持 |
| 支持Spring Config | 高 | 原生支持 | 低 | 与Spring Cloud无关 |
| 客户端支持 | 低 | java | java | java |
| 业务系统入侵性 | 高 | 入侵性弱 | 入侵性弱 | 入侵性弱,支持注解和xml |
| 可依赖组件 | 高 | |||
| 可用性 | 单点故障(SPOF) | 高 | 支持HA部署 | 支持HA部署 |
| 多数据中心部署 | 高 | 支持 | 支持 | 支持 |
| 配置获取性能 | 高 | unkown | unkown | unkown |
| 易用性 | 配置界面 | 中 | 无,需要git、数据库等操作 | 统一界面 |
结论:
- 从整体上来看的话,携程的Apollo性能及各方面相对于其他配置中心而言是最好的,因为其支持pring Boot和Spring Config,所以在微服务架构中建议最好采用Apollo来作为配置中心;
- Spring Cloud Config相对Apollo性能与支持没有很全面,但是可以采用一定的开源技术及现有技术进行改善加之原生支持pring Boot和Spring Config,在微服务架构中也是强烈建议采用的方案;
- 其他两种方案在微服务架构中不建议采用,在此不做分析。
配置中心模型442
4大分类
先来梳理下配置相关的内容和分类:
-
按配置的来源划分:源代码文件、数据库和远程调用。
-
按配置的适用环境划分:开发环境、测试环境、预发布环境、生产环境等。
-
按配置的集成阶段划分:
-
编译时—源代码级的配置+配置文件和源代码一起提交到代码仓库;
-
打包时—通过某种方式将配置打入最终的应用包中;
-
运行时—应用启动时并不知道具体配置,需从本地或远程获取配置,在正常启动。
- 按配置的加载方式划分:单次加载型配置、动态加载型配置。
4个核心需求
依照配置相关的内容和分类来看,构建一个合适的配置中心,至少需要满足以下4个核心需求:
- 非开发环境下应用配置的保密性,避免将关键配置写入源代码;
- 不同部署环境下应用配置的隔离性,比如非生产环境的配置不能参与生产环境;
- 同一部署环境下的服务器应用配置的一致性,即所有服务器使用同一份配置;
- 分布式环境下应用配置的可管理性,即提供远程配置能力。
2个维度分析
采取配置中心也就意味着采用集中式配置管理的设计思想。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bBvkaCN4-1596214225853)(C:\Users\CR553\Pictures\303.png)]
-
维度一:在集中式配置中心中,开发、测试和生产等不同环境配置信息统一保存在配置中心中;
-
维度二: 分布式集群环境,需要确保集群中同一类服务的所有服务器保存同一份配置文件并且能够同步更新。
config
Spring Cloud Config是Spring Cloud微服务体系中的配置中心,是一个集中化外部配置的分布式系统,由服务端和客户端组成,其不依赖于注册中心,是一个独立的配置中心,支持多种存储配置信息形式,目前主要有jdbc、value、native、svn、git,其中默认是git。重点讨论功能有如下两个方面:
- 将程序中配置的各种功能开关、参数配置、服务器地址------>修改后实时生效
- 灰度发布、分环境、分集群管理配置--------->全面集中化管理
在实际操作中我们主要的实现方案有以下四种:Spring Cloud Config结合Git实现配置中心方案+Spring Cloud Config结合关系型数据库实现配置中心方案+Spring Cloud Config结合非关系型数据库实现配置中心方案+Spring Cloud Config与Apollo配置结合实现界面化配置中心方案。
基础流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-elAjza4n-1596214225854)(C:\Users\CR553\Pictures\301.png)]
配置实时刷新
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uZMeHjvb-1596214225855)(C:\Users\CR553\Pictures\302.png)]
- 与git仓库结合使用时,使用git的web hook监控git仓库中配置信息的变更,一旦有变更,则推送给Config Server,进而通过Spring Cloud Bus实现实时更新
在微服务架构中,一般都需要引入配置中心的设计思想和相关工具。
消息总线
什么是总线
在微服务架构中,通常回事会使用轻量级的消息代理来构建一个公用的消息主题,并让系统中所有微服务实例都连接上来,由于该主题中产生的消息会被所有实例监听和消费,所以称他为消息总线.在总线上的各个实例都可以方便地传播一些需要让其他连接在该主题上的实例都知道的消息
基本原理
ConfigClient实例都监听MQ中同一个topic.当一个服务刷新数据的时候,他会把这个信息放入到topic中,这样其他监听同一个topic的服务就能得到通知,然后去更新自身的配置.
BUS
Spring Cloud Bus是用来将分布式系统的节点与轻量级消息系统连接起来的框架,它融合了java的事件处理机制和消息中间件的功能.Bus能管理和传播分布式系统间的消息,就像一个分布式执行器,可用于广播状态更改,事件推送,也可以当作微服务间的通信通道
消息驱动
概述
屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型
SpringCloud Stream
概述
官方定义SpringCloud Stream是一个构建消息驱动微服务的框架
应用程序通过inputs或者outputs来与SpringCloud Stream中binder对象交互.通过我们配置来binding(绑定),而SpringCloud Stream的binder对象负责与消息中间件交互,所以,我们只需要搞清楚如何与SpringCloud Stream交互就可以方便使用消息驱动的方式,通过使用Spring Integration 来连接消息代理中间件已实现消息事件驱动.SpringCloud Stream为一些供应商的消息中间件产品提供了个性化配置实现,引用了发布-订阅,消费组,分区的三个核心概念.目前仅支持RabbitMQ.Kafka.
设计思想
标准的MQ中,生产者和消费者之间要靠消息媒介传递信息内容,消息必须走特定的通道(MessageChannel).
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9HJc5ZKn-1596214225856)(C:\Users\CR553\AppData\Roaming\Typora\typora-user-images\1595073042739.png)]
-
消息通信方式遵循发布-订阅模式
-
Stream的标准套路
-
Binder: 很方便的连接中间件,屏蔽差异
-
Channel: 通道,是队列的一种抽象,在消息通讯系统中就是实现存储和转发的媒介,通过Channel对队列进行配置
-
Source和Sink: 参照对象是Stream本身,从Stream发布消息就是输出,接收消息就是输入
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iAW7sMzt-1596214225857)(C:\Users\CR553\AppData\Roaming\Typora\typora-user-images\1595073638551.png)]
常用注解
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FIVAu0Rx-1596214225858)(C:\Users\CR553\AppData\Roaming\Typora\typora-user-images\1595073876804.png)]
为什么用Stream?
通过定义绑定器Binder作为中间层,实现了应用程序与消息中间件细节之间的隔离,屏蔽了底层差异
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LETDD6En-1596214225859)(C:\Users\CR553\AppData\Roaming\Typora\typora-user-images\1595073267589.png)]
链路追踪
分布式中可能出现的问题
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DktRByFT-1596214225860)(C:\Users\CR553\AppData\Roaming\Typora\typora-user-images\1595145185839.png)]
Spring Cloud Sleuth 提供了一套完整的服务跟踪的解决方案在分布式系统中提供追踪解决方案并且兼容支持了zipkin
SpringCloud Sleuth
简介
Add sleuth to the classpath of a Spring Boot application (see below for Maven and Gradle examples), and you will see the correlation data being collected in logs, as long as you are logging requests.
------ 摘自官网
Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案,并且兼容支持了 zipkin,你只需要在pom文件中引入相应的依赖即可。
下载安装
下载地址
http://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/
下载完成后到对应目录cmd直接java -jar 执行即可
登录网址检测是否启动
localhost:9411
服务追踪分析
微服务架构上通过业务来划分服务的,通过REST调用,对外暴露的一个接口,可能需要很多个服务协同才能完成这个接口功能,如果链路上任何一个服务出现问题或者网络超时,都会形成导致接口调用失败。随着业务的不断扩张,服务之间互相调用会越来越复杂。

随着服务的越来越多,对调用链的分析会越来越复杂。它们之间的调用关系也许如下:

术语
- Span:基本工作单元,例如,在一个新建的span中发送一个RPC等同于发送一个回应请求给RPC,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址)
span在不断的启动和停止,同时记录了时间信息,当你创建了一个span,你必须在未来的某个时刻停止它。 - Trace:一系列spans组成的一个树状结构,例如,如果你正在跑一个分布式大数据工程,你可能需要创建一个trace。
- Annotation:用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束
- cs - Client Sent -客户端发起一个请求,这个annotion描述了这个span的开始
- sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络延迟
- ss - Server Sent -注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得到服务端需要的处理请求时间
- cr - Client Received -表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间戳便可得到客户端从服务端获取回复的所有所需时间
将Span和Trace在一个系统中使用Zipkin注解的过程图形化:
将Span和Trace在一个系统中使用Zipkin注解的过程图形化:

SpringCloud Alibaba
特性
-
服务限流降级:默认支持servlet,feign,restTemplate,dubbo和rocketMQ限流降级功能的接入,可以在运行时间通过控制台实时修改限流降级规则,还支持查看限流降级Metrics监控
-
服务注册与发现:适配Spring Cloud 服务注册与发现标准,默认集成了Ribbon的支持
-
分布式配置管理:支持分布式系统中的外部化配置,配置更改时自动刷新
-
消息驱动能力:基于Spring Cloud Stream 为微服务应用构建消息驱动能力
-
阿里云对象存储:阿里云提供的海量,安全,低成本,高可靠的云存储服务,支持在任何应用,任何时间,任何地点存储和访问任意类型的数据.
-
分布式任务调度:提供秒级,精准,高可靠,高可用的定时任务调度服务.同时提供分布式的任务执行模型,如网格任务.网格任务支持海量子任务均匀分配到所有Worker上执行
目前技术
- Sentinel
阿里巴巴开源产品,把流量作为切入点,从流量控制,熔断降级,系统负载保护等多个维度保护服务的稳定性.
- Nacos
阿里巴巴开源产品,一个更易于构建云原生应用的动态服务发现,配置管理和服务管理平台
- RocketMQ
Apache RocketMQ基于Java的高性能,高吞吐量的分布式消息和流计算平台
- Dubbo
Apache Dubbo是一款高性能Java RPC框架
- Seata
阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案
- Alibaba Cloud OSS
阿里云对象存储服务(Object Storage Service,简称OOS),是阿里云提供的海量,安全,低成本,高可靠的云存储服务.您可以在任何应用,任何时间,任何地点存储和访问任意类型的数据
- Alibaba Cloud SchedulerX
阿里中间件团队开发的一款分布式任务调度产品,支持周期性地任务与固定时间点触发任务.
Nacos
什么是Nacos?
Nacos(Dynamic Naming and Configuration Service) 致力于帮助您发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据及流量管理。
是Spring Cloud A 中的服务注册发现组件,类似于Consul、Eureka,同时它又提供了分布式配置中心的功能,这点和Consul的config类似,支持热加载。
Nacos 的关键特性包括:
- 服务发现和服务健康监测
- 动态配置服务,带管理界面,支持丰富的配置维度。
- 动态 DNS 服务
- 服务及其元数据管理
Nacos下载
Nacos依赖于Java环境,所以必须安装Java环境。然后从官网下载Nacos的解压包,安装稳定版的,下载地址:https://github.com/alibaba/nacos/releases
本次案例下载的版本为0.09 ,下载完成后,解压,在解压后的文件的/bin目录下,windows系统点击startup.cmd就可以启动nacos。linux或mac执行以下命令启动nacos。
sh startup.sh -m standalone
启动时会在控制台,打印相关的日志。nacos的启动端口为8848,在启动时要保证端口不被占用。
启动成功,在浏览器上访问:http://localhost:8848/nacos,会跳转到登陆界面,默认的登陆用户名为nacos,密码也为nacos。
登陆成功后,展示的界面如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p8bgcGTK-1596214225861)(C:\Users\CR553\Pictures\311.png)]
从界面可知,此时没有服务注册到Nacos上。
Nacos全景图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7OhwytsP-1596214225862)(C:\Users\CR553\AppData\Roaming\Typora\typora-user-images\1595218540336.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J29QvgGe-1596214225863)(C:\Users\CR553\AppData\Roaming\Typora\typora-user-images\1595218605345.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KUkFsuvt-1596214225863)(C:\Users\CR553\AppData\Roaming\Typora\typora-user-images\1595218649044.png)]
Sentinel
简介
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UpuI3deF-1596214225865)(C:\Users\CR553\AppData\Roaming\Typora\typora-user-images\1595389058448.png)]
-
核心库(java客户端)不依赖任何框架/库,能够运行于所有java运行时环境,同时对Dubbo/spring cloud等框架也有较好的支持
-
控制台基于SpringBoot开发,打包后可以直接运行,不需要额外的Tomcat等应用容器
下载安装
https://github.com/alibaba/sentinel/releases
有java8环境,8080端口空闲,直接在保存位置cmd中java -jar 执行即可使用登录localhost:8080
用户名和密码都为sentinel
Seata
分布式事务的问题
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A8ZCAgL8-1596214225866)(C:\Users\CR553\AppData\Roaming\Typora\typora-user-images\1595510519979.png)]
单体应用被拆分成微服务应用,原来的三个模块被拆分成三个独立的应用,分别使用三个独立的数据源.业务操作需要调用三个服务来完成.此时每个服务内部的数据一致性由本地事务来保证,但是全局的数据一致性问题没法保证.
一次业务操作需要跨多个数据源或需要跨多个系统进行远程调用,就会产生分布式事务问题.
Seata简介
Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。
Seata术语
唯一的ID+三组件模型
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
Seata处理过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XQR1cWla-1596214225868)(C:\Users\CR553\AppData\Roaming\Typora\typora-user-images\1595511203183.png)]
- TM向TC申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的XID;
- XID在微服务调用链路的上下文中传播;
- RM向TC注册分支事务,将其纳入XID对应全局事务的管辖;
- TM向TC发起针对XID的全局提交或回滚决议
- TC调度XID下管辖的全部分支事务完成提交或回滚请求
参考资料
微服务架构
https://www.nginx.com/blog/service-discovery-in-a-microservices-architecture/
永不失联!如何实现微服务架构中的服务发现?
https://blog.csdn.net/jiaolongdy/article/details/51188798
「Chris Richardson 微服务系列」服务发现的可行方案以及实践案例
http://blog.daocloud.io/microservices-4/
Eureka原理分析与实例
https://blog.csdn.net/JinXYan/article/details/90721953
看完这篇就全懂负载均衡了
https://blog.csdn.net/rocling/article/details/82954327
负载均衡
https://blog.csdn.net/u013743253/article/details/80476116
深入理解Ribbon之源码解析
https://blog.csdn.net/forezp/article/details/74820899
微服务架构-实现技术之具体实现工具与框架5:Spring Cloud Feign与Ribbon原理与注意事项
https://blog.csdn.net/xiaofeng10330111/article/details/87272248
配置中心
https://blog.csdn.net/weixin_34072637/article/details/93724992
微服务架构-实现技术之具体实现工具与框架8:Spring Cloud Config原理与注意事项
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
Seata处理过程
[外链图片转存中…(img-XQR1cWla-1596214225868)]
- TM向TC申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的XID;
- XID在微服务调用链路的上下文中传播;
- RM向TC注册分支事务,将其纳入XID对应全局事务的管辖;
- TM向TC发起针对XID的全局提交或回滚决议
- TC调度XID下管辖的全部分支事务完成提交或回滚请求
参考资料
微服务架构
https://www.nginx.com/blog/service-discovery-in-a-microservices-architecture/
永不失联!如何实现微服务架构中的服务发现?
https://blog.csdn.net/jiaolongdy/article/details/51188798
「Chris Richardson 微服务系列」服务发现的可行方案以及实践案例
http://blog.daocloud.io/microservices-4/
Eureka原理分析与实例
https://blog.csdn.net/JinXYan/article/details/90721953
看完这篇就全懂负载均衡了
https://blog.csdn.net/rocling/article/details/82954327
负载均衡
https://blog.csdn.net/u013743253/article/details/80476116
深入理解Ribbon之源码解析
https://blog.csdn.net/forezp/article/details/74820899
微服务架构-实现技术之具体实现工具与框架5:Spring Cloud Feign与Ribbon原理与注意事项
https://blog.csdn.net/xiaofeng10330111/article/details/87272248
配置中心
https://blog.csdn.net/weixin_34072637/article/details/93724992
微服务架构-实现技术之具体实现工具与框架8:Spring Cloud Config原理与注意事项
https://blog.csdn.net/xiaofeng10330111/article/details/87272559