这个真的写的很细,JavaIO中的常用处理流,看完只有10%的人还不懂了
JavaIO中的常用处理流
在前面,我们了解了有关JavaIO流基础的使用,其中对于IO流来说最基础的四大基类就是InputStream、OutputStream、Reader、Writer。而我们对文件操作的最常用的子类就是FileInputStream、FileOutputStream、FileReader、FileWriter四大类,他们的用法基本上是完全一样的,只不过前两个是操作字节的,后两个是操作字符的。
字节流和字符流的区别
1、首先操作单元不同。字节流操作的单元是数据单元是8位的字节,字符流操作的是数据单元为16位的字节。
2、其次实际上字节流在操作时本身不会用到缓冲区(内存),是文件本身直接操作的,而字符流在操作时使用了缓冲区,通过缓冲区再操作文件。
缓冲区
缓冲区可以简单地把缓冲区理解为一段特殊的内存。它的主要作用是:
1、某些情况下,如果一个程序频繁地操作一个资源(如文件或数据库),则性能会很低,此时为了提升性能,就可以将一部分数据暂时读入到内存的一块区域之中,以后直接从此区域中读取数据即可,因为读取内存速度会比较快,这样可以提升程序的性能。
2、在字符流的操作中,所有的字符都是在内存中形成的,在输出前会将所有的内容暂时保存在内存之中,所以使用了缓冲区暂存数据。如果想在不关闭时也可以将字符流的内容全部输出,则可以使用Writer类中的flush()方法完成。
字节流和字符流的使用
开发中究竟用字节流好还是用字符流好呢?
在所有的硬盘上保存文件或进行传输的时候都是以字节的方法进行的,包括图片也是按字节完成,而字符是只有在内存中才会形成的,所以使用字节的操作是最多的。
具体哪个好要是具体环境而定。比如我们要将字符类文件的内容读取出来对立面的内容进行操作那么这个时候选用字符流更为合适。如果不需要对内容进行操作只是单纯的文件传输例如文件拷贝那么选用字节流更合适。
FileReader和FileWriter类说明
public class FileReader
public class FileReader
extends InputStreamReader
extends Reader
extends java.lang.Object
FileReader不是Reader的子类,而是转换流的子类。
public class FileWriter
extends OutputStreamWriter
extends Writer
extends java.lang.Object
FilWriter不是Writer的子类,而是转换流的子类。
也就是说,不管如何,虽然是以字符的输出流形式,操作字节流输出流,但是实际上还是以字节的形式输出。而字符的输入流虽然是以字符的形式操作,但是还是使用了字节流,也就是说,在传输或者从文件读取数据的时候,文件里真正保存的数据永远是字节。
带Buffered的处理流
BufferedInputStream / BufferedOutputStream 和 BufferedReader / BufferedWriter
这些处理流都是内置一个缓冲区(大小为8kb)。前者处理字节流,后者处理字符流。
常用方法
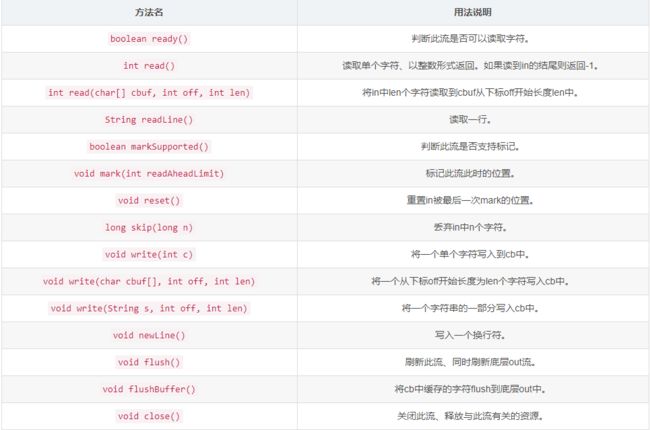
从流里面读取文本,通过缓存的方式提高效率,读取的内容包括字符、数组和行。
缓存的大小可以指定,也可以用默认的大小。大部分情况下,默认大小就够了。
需要注意的是这里提供了mark和reset功能,也就是可以记住读取的位置,将来可以回滚,重新读取。这需要在读取数据时避免对缓冲区中的这部分数据覆盖掉,需要保存起来,同时保存的长度可以在mark的时候指定。调用reset可以回滚,但是必须mark过,而且mark过后读取的数据不能超过mark的时候设置的大小,否则会失效,调用reset会抛出异常。
public class Buffer_Test {
public static void main(String[] args) {
// BufferedOutputStream 和 FileIOutputStream 用法完全一致
//这两个处理流直接操作的是缓冲区
BufferedOutputStream out;
BufferedInputStream in = null; //输入流 用法和fileInputStream完全一致
try {
in = new BufferedInputStream(new FileInputStream("D:\\Java文件IO\\Test\\a.txt"));
//参数:字节流必须上输入流 第二个参数可以指定缓冲区大小 单位是字节
for (int i = 0; i < 1024 * 9; i++) {
in.read(); //只有第一次会从文件中读8K放入缓冲区,
// 之后就直接从缓冲区中读取 不用进行文件IO
//直到将缓冲区当中数据读完 再次读取8K数据刷新原有的缓冲区
}
out = new BufferedOutputStream(new FileOutputStream( //节点流是直接操作数据的
"D:\\Java文件IO\\Test\\a.txt", true));
out.write(23); //会将写的数据先存入缓冲区 让然后攒够8K 一次性写入文件
//写入之后将缓冲区清空(实际上是将下标重新移动到初始位置,会将原数据覆盖) 继续接收新数据
//写的时候要注意 调用flush 方法 和 close方法可以刷新缓冲区
//或者是你写入的数据数量大于了缓冲区的大小可以不调用这两个方法
out.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
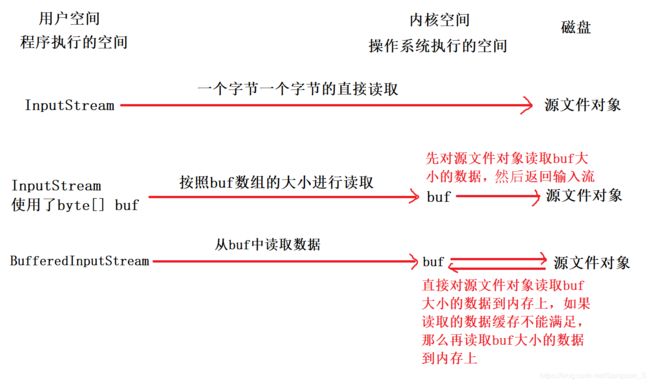
read()方法的执行过程是:直接从源文件读取8192字节大小(或者字符大小)的数据,每当我们进行读取时,就直接从 buf 也就是缓存中去读写,如果读取的内容的大小已经大于了buf的长度,那么 buf 直接返回内存中指定需要的数据(内存大小8192,如果4096的内容已经都去了,这一次要读取8192,那么直接将剩余的4096字节的内容读取,再对磁盘进行交互),然后再读取源文件8192大小,返回给buf缓存,再返回给read(),直到满足需求。
write()方法,同样,先把数据写入缓存,当调用write()方法时,直接从缓存中去写入,如果写入的大小大于了 buf 的大小,那么直接flush(),再去将内存更新,再写入。
read 方法和 write 方法一样。本质上提升了效率,减少了磁盘的交互。
存在意义
为什么需要带Buffered处理流?
为了提高字符读取的效率。
BufferedInputStream和BufferedOutputStream这两个类分别是FilterInputStream和FilterOutputStream的子类,作为装饰器子类。并且构造函数需要FilterInputStream/FilterOutputStream的子类入参。
BufferedReader和BufferedWriter这两个类分别是Reader和Writer的子类,作为装饰器子类。并且构造函数需要Reader/Writer的子类入参。
使用它们可以防止每次读取/发送数据时进行实际的写操作,代表着使用缓冲区。我们有必要知道不带缓冲的操作,每读一个字节就要写入一个字节,由于涉及磁盘的IO操作相比内存的操作要慢很多,所以不带缓冲的流效率很低。带缓冲的流,可以一次读很多字节,但不向磁盘中写入,只是先放到内存里。等凑够了缓冲区大小的时候一次性写入磁盘,这种方式可以减少磁盘操作次数,速度就会提高很多!
也就是说如果当前缓冲区没有数据,则调用底层reader去读取数据到缓冲区;如果有数据则直接读取。默认的 缓冲大小是8k,也就是每次读取都是8k为单位。
BufferedReader中还提供了一行一行读取的功能readLine函数,这不是Reader中的方法,这种方法可以把换行符(\r、\n、\r\n)去掉。
flush的作用
BufferedOutputStream在close()时会自动flush,BufferedOutputStream或者Bufferedwriter在不调用close()的情况下,缓冲区不满,又需要把缓冲区的内容写入到文件或通过网络发送到别的机器时,才需要调用flush。
源码分析
以BufferedInputStream为例:源码分析
要想读懂BufferedInputStream的源码,就要先理解它的思想。
BufferedInputStream的作用是为其它输入流提供缓冲功能。创建BufferedInputStream时,我们会通过它的构造函数指定某个输入流为参数。BufferedInputStream会将该输入流数据分批读取,每次读取一部分到缓冲中;操作完缓冲中的这部分数据之后,再从输入流中读取下一部分的数据。
为什么需要缓冲呢?
原因很简单,效率问题!缓冲中的数据实际上是保存在内存中,而原始数据可能是保存在硬盘或NandFlash等存储介质中;而我们知道,从内存中读取数据的速度比从硬盘读取数据的速度至少快10倍以上。
那干嘛不干脆一次性将全部数据都读取到缓冲中呢?
第一,读取全部的数据所需要的时间可能会很长。
第二,内存价格很贵,容量不像硬盘那么大。
额外知识
1、类自带的缓冲区,与我们自己创建的缓冲区有什么不同?
2、既然FileWriter和Filereader中已经带有缓冲区,还要有BufferReader和BufferWriteer?
Java 在IO操作中,都会有一个缓冲区的,它们不同在于缓冲区的大小。BufferWriter更合理的使用缓冲区,在处理大量的数据时,FileWrite的效率明显不如BufferWriter。
带Object的处理流
带Object的处理流被称为对象处理流,常见的有两种:ObjectInputStream和ObjectOutputStream
对象流可以将一个对象写出,或者读取一个对象到程序中(对象持久化),也就是执行了序列化和反序列化的操作。
序列化的概念
将一个对象存放到某种类型的永久存储器上称为保持。如果一个对象可以被存放到磁盘或磁带上,或者可以发送到另外一台机器并存放到存储器或磁盘上,那么这个对象就被称为可保持的。
在Java中,序列化、持久化、串行化是一个概念。
参考链接:序列化与反序列化
基本使用方法

class Dog implements Serializable {
private static final long serialVersionUID = -5156631308412187014L;
private String name;
private int age;
public Dog() {
}
public Dog(String name, int age) {
this.name = name;
this.age = age;
}
//省略get/set方法
}
public class ObjectStreamTest { //对象持久化的过程 数据落地
public static void main(String[] args) {
Dog dog = new Dog("nickel", 8);
//把对象变成字节存储到文件中
ObjectOutputStream out = null;
ObjectInputStream in = null;
try {
out = new ObjectOutputStream(
new FileOutputStream("D:\\Java\\IoTest\\dog.txt"));
out.writeObject(dog);
System.out.println("---------------反序列化的结果如下-------------------");
in = new ObjectInputStream(
new FileInputStream("D:\\Java\\IoTest\\dog.txt"));
Dog dog1 = (Dog) in.readObject();
System.out.println(dog1);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
注意:我们的对象类一定要实现 Serializable 接口(java.io.Serializable接口没有任何方法,它只作为一个“标记者”,用来表明实现了这个接口的类可以考虑串行化。类中没有实现Serializable的对象不能保存或恢复它们的状态) 不然程序就会报错。
带Data的处理类
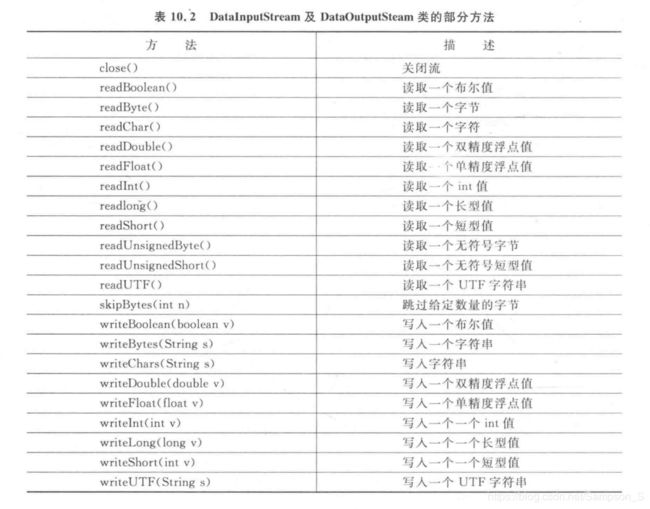
DataInputStream和DataOutputStream类创建的对象称为数据输入流和数据输出流。它们运行程序按着机器无关的风格读取Java原始数据。也就是说,当读取一个数值时,不必再关心这个数值应当是多少个字节。
常用方法
基本使用方法
public class Data_StreamTest {
public static void main(String[] args) {
DataOutputStream out = null;
DataInputStream in = null;
People p = new People("张三", 13, new A(1, "dsad"));
try {
out = new DataOutputStream(new FileOutputStream("D:\\Java\\IoTest\\p.txt"));
out.writeUTF(p.getName());
out.writeInt(p.getAge());
out.writeInt(p.getA().getSex());
out.writeUTF(p.getA().getName());
in = new DataInputStream(new FileInputStream("D:\\Java\\IoTest\\p.txt"));
People p1 = new People();
p1.setName(in.readUTF());
p1.setAge(in.readInt());
A a = new A();
a.setSex(in.readInt());
a.setName(in.readUTF());
p1.setA(a);
System.out.println(p1);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
class People {
private String name;
private int age;
private A a;
public People() {
}
public People(String name, int age, A a) {
this.name = name;
this.age = age;
this.a = a;
}
//省略get/set方法
}
class A{
private int sex;
private String name;
public A() {
}
public A(int sex, String name) {
this.sex = sex;
this.name = name;
}
//省略get/set方法
}
对象流和数据流的区别与联系
1、Object相当于装IO流的一个盒子,我们可以把对象比作一个个拼好的积木,IO流就是拼积木的积木块,那么如果要搬走积木(对象),肯定需要把积木(对象)先拆了,再扔进盒子(Object)里,这就是为什么对象要序列化(Serializable)。
2、当然装的时候我们可以有两种装法一种是全放入(output.writeObject(this))第一种盒子(ObjectInputStream),另一种是分类别 (如:比如将屋顶、地板、这些流里面的) 放入(output.writeUTF(number),output.writeUTF(name),output.writeInt(age)…)第二种盒子(DataInputStream),所以在搬到另一个地方的时候,第一种盒子里我们把混在一起的积木块倒出((Member)intput.readObject()),第二种盒子则是分块拿出来({input.readUTF(),input.readUTF(),input.readInt()…})。
3、处理基本类型的时候没有什么很大的区别,区别是Object的可将一个实现了序列化的类实例写入输出流中,ObjectInput可以从输入流中将ObjectOutput输出的类实例读入到一个实例中。DataOutputStream只能处理基本类型。(Object处理的类必须是实现了序列化的类)。