16分钟理解JavaScript中的Promises
原文:https://medium.com/quick-code/javascript-promises-in-twenty-minutes-3aac5b65b887
声明:本文中的所有图片均来自于原文
介绍
我认为好的故事都是从真理开始的(I think that most good stories start with a truism)。一般而言,好的程序员都是懒得程序员,他们特别喜欢懒,所以呢,他们会熬夜到很晚,发明一个更高效的方式,让自己可以更懒,这帮人还热衷于跟他的那些成千上万的好基友们谈论,怎么懒,才是最懒(也就是谁的代码更高效)。
言归正传,找出一条合适的路,是让程序可读,可维护和高效的管你建。你会发现,我们使用的每个工具,都是为了让我们需要做的事情变得更容易。
Promises也不例外,当你把它当成一个抽象概念的时候,Promises是什么,怎么用它们可能是一件让你头疼的事儿。首先呢,应该理解它们的概念,Promises就像是一个捉迷藏的游戏。在你需要开始一些应用时,你往往会遇到这样的问题:“我在某个地方的代码,想做的是,在我得到某个数据之前,不想试着去用这个数据(因为还没有得到这个数据,所以尝试使用可能会出错)”。我敢打赌,promises的出现,会帮助你解决这个问题(回调函数好像也可以……)。
不管怎样,让我先来试着讲讲看:为了说清楚promises做了什么,我们需要搞清楚我们为什么需要它。想想看,当你告诉node或者V8,去跑一个文件时,发生了什么,这会帮助我们理解管理异步操作是在做什么,什么时候异步操作会出现,还有为什么promises是这么优秀,还有有什么办法去解决这个过程中遇到的问题。
在开始之前呢,我想说,这篇文章的目的不是为了给你丢一堆这样那样的文档,而是为了像讲故事一样说清楚,我们如何在构建应用时使用promises,所以如果刚开始讲的比较简单,比较基础的话,抱歉啦~
Part Ⅰ在Promises出现之前的应用
我们的代码是如何运行的呢?一般是按照顺序执行的,也就是运行完一个表达式后,继续运行下一个表达式。它是单向的,对吧?这当然很好啦,因为代码是怎么运行的,你是可以预测的。比方说,我们第50行运行的代码,一般是从40行获取的信息。如果我们跑的是一个地方的代码,并且执行速度是一般程序的执行速度,我们的代码都是这样跑的。
但是,有的时候它就不一样,有的时候我们需要做的事情很大,也很复杂,可能就算是超级计算机,处理这些事情也很慢(按照计算机的标准,可能需要耗费几百毫秒)。比方说,从数据库中读取数据,或者直接读取文件。
JavaScript是单线程的语言,也就是说,它只能在同一时间做一件事情。这样的话,程序做什么事情都是可以预知的,也很容易管理。如果我们这么理解的话,那么,在完成第一件事情之前,我们没有办法做第二件事情,那这样的话,我们就不能得到我们一直使用的,平滑的交互式用户体验了。如果我们因为需要等待获取到数据,而去花一两秒的时间来等待页面或者应用有所变化的话,我们甚至都不能进行简单的页面操作了,比方说,当代码在做另外一件事时,我们想要更改某段文本的颜色,都不能更改。
所幸,JavaScript也没有那么弱智。我们的call stack并不是唯一控制我们代码的东西。我们有一系列的API(Web或C++,取决于前端还是后台),来帮助我们处理异步操作。
所以,如果我们做了下面这件事情:
当然,你最好不要这么干啦
上面这段代码是这样操作的,首先呢,调用fs.ReadFile函数,这个函数加入到callstack中,接着再运行console.log的语句。是这样吧?这样的话,我们会遇到一个很严重的问题:在得到数据,并将数据赋值给ourStuff之前,console.log不会输出我们文件中的内容,输出的结果是undefined。因为代码一路执行下去,数据还没有给了定义的变量outStuff,就已经使用console.log打印出来了,那么我们怎么办呢?
有一个解决办法是:我们可以用一个异步函数来解决这个问题,然后把拿到数据后我们才能做的事情,统统放到这个函数里。当一个异步函数执行的时候,是不是它传入的参数是在异步操作完成之后进行的呢?这个也不完全是。
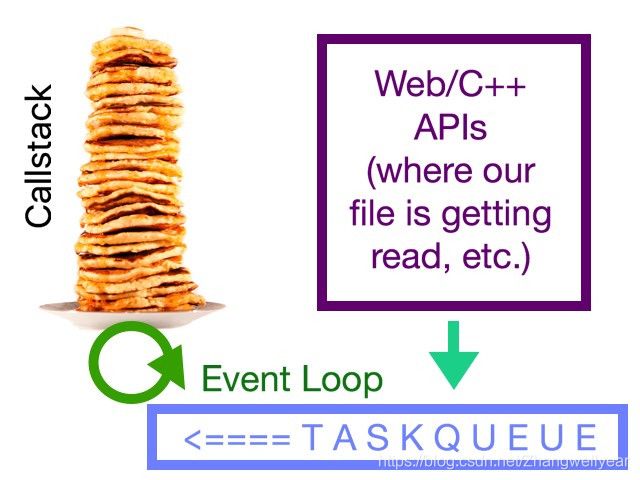
我们并不知道异步操作会花过长时间来完成,可能是0.1s,也可能是2s,鬼知道呢?如果我们在回调函数跑完了的时候,就执行触发这个函数的代码呢?那就会出现这种情况,代码跑着跑着,忽然又回去跑中间的那段代码去了,这不全乱了套了嘛。还好,回调函数不是这么干的。
那么JavaScript里,回调函数是怎么干的呢,一般是这样的,当异步操作干完了自己的活之后,回调函数被放进任务队列中,放进去的时候并不执行。我们的回调函数是按照call stack的执行顺序来执行的,像其他函数一样,至于回调函数是怎么从队列中被添加到call stack中的,这是由event loop决定的。
event loop只需要做一件事情:连续地监视call stack。当call stack空了的时候,event loop会检查任务队列,然后把任务队列中的第一个元素出队入栈。那也就是说,我们回调函数会在它是任务队列的第一个位置并且call stack为空的时候,执行。听起来好像我们还是没有办法预测回调函数啥时候执行,但是比之前说的那种随时可能会执行,是不是好多了?
所以呢,我们的代码改成下面这个样子会比较好:

回调函数看起来也没那么可怕吧?当然这个地方的”=>”符号,你也可以用传统的array.map来实现,我这样写,是为了让代码简洁一些。
如果我想做的不仅仅是这么着呢?要是我不只是想简单地输出一下,而是想干一些更复杂的事情呢?如果veryImportantFile里面数据是为了让给我们一个索引,让我们能够找到下一个文件进行读取呢?这将会是下一个异步操作,这样继续异步操作下去可不可以?这个时候,异步操作又会有自己的回调函数,这样的话,需要前面的事情都做完了,并且call stack至少清空两次之后,这个回调函数才会被执行。如果我们读取的文件又需要进行异步操作呢,这是不是就意味着,会一直异步下去呢。
之前忘了一件事情,我好像没有提我们跳过了一步,就是当我们读取veryImportantFile的时候,出错了呢,可能是名字不对,也可能文件被损坏了,或者是其他什么我们没有预料到的错误呢?我们上面定义的回调函数都是有自己的功能的,而且它的操作依赖于获取到的数据,所以如果读取文件出错,那么这个回调函数的执行就没有任何意义。
处理这种情况时,我们可以为回调函数增加一个参数,一个用来处理成功请求到数据,一个用来处理出现错误的情况(一般我们得先处理error信息啦)——这样的方式当然是符合人类的直觉的。我们的应用实际上不需要辣么复杂啦,复杂到像下面这样,那简直是生无可恋。
你可能会说:“这样的代码虽然很迷,但是起作用就行了啊,no BB,show me the code就行,我们的运行环境,又不care代码是好看还是不好看,对吧?何必跟自己个儿过不去呢”。
可是事实不应该是这样的,我们应该care,要是这么干,我们的代码的可读性,易用性就很低了,我们在请求获取数据的时候,我们必须在一个回调函数中管理好我们想做的所有的事情。要管理好这个任务链,是一件很麻烦的事情,尤其是这些任务之间还存在相互关联,要理清操作的顺序也是不容易的。
任何写得不怎样的代码,粗糙的代码都意味着难以调试。你干的活,可能后面还有人继续干呢,所以在写代码的时候,认真点兄弟,一次性写好,然后再干下面的活,少干最好不干返工的活。不过呢,现实中你写得代码,情况不会像你计划的那样。我的很多血泪史告诉你,你经常会犯一些错误,所以你需要调试(你可以转向我这里的基础调试指导)。不过费劲巴拉地调试回调无底洞的人,有点可惜。并且一般调试你代码的人,可能不是写代码的你自己,现实中很少有代码是一个人从头写到尾的。而且当你碰到这个回调无底洞的时候,,你可能已经忘了这段代码是用来干嘛的了。而且如果你的工作有价值的话,早晚会有人重新使用或者更新你的代码。
代码写得好看不好看,还不仅仅是花架子。它表现的是你写得程序怎么样,还有你或者你的团队把它维护的怎样的问题。当然,如果我们必须造这个回调无底洞干活,那我们没有办法,但是我们是不是有更好的办法呢?
Part Ⅱ 写在Promise之前
那么什么是promise呢,这个东西怎么能让我们不再身陷囹圄呢?
对promise最完美的定义为:promise代表着异步操作的最终结果。跟promise交互的最基本的办法是通过then方法,这个方法会调用一个回调函数,来告知用户最终收到的值是什么,如果promise没拿到该有的结果,会告知用户,为啥没拿到结果。
看完这个定义有没有理解一些呢?没懂也没关系啦,就像我之前说的,这就像是一个捉迷藏的游戏。我来解释一下promise做了什么,一个promise就是一个异步操作的容器——它最起码要告诉我们的是,异步回调告诉了我们什么,很多时候异步回调非常繁琐,promise就是用来减少实际应用中的这些繁琐问题的。否则的话,promise的存在就没有什么意义了,记住我们之前说过的一点,这些工具的存在是为了让我们的工作变得更容易。
Promises能够让我们从层层嵌套中解放出来,它能够让我们很容易地跟踪每个异步操作之间的相互依赖关系。Promises还提供了几个处理errors的方法以供选择,当然你也可以自定义,自定义任何你认为比现在的方法更好的方法。Promises旨在让我们能够像编写非阻塞(non-blocking)predictable和单项的同步代码一样,编写异步的代码,能够让我们更快地编写阻塞的代码(blocking)。这听起来贼流弊吧,那我们怎么用呢?
坏消息是,promises除了依赖最基本的JavaScript语言之外,不依赖于任何其他的东西。JavaScript现在也在JavaScript的原生代码中受到了支持(比如ES6),你可以在任何时候实例化一个新的promise对象。但是你也不必非得用原生的代码来实现promise,在JavaScript支持原生的promise之前,大量的厉害的程序员都写了基础的promise库。你可能还想继续用它们,因为有些库,比原生的promise要高效的多,或者它们当中的一些,有一些其他的特性对你有用。这儿有一些超级棒的promise库。
那么,什么是promise呢?Promise字面上来看,就是一个普通的对象。
这与你自己创建的普通对象没有什么不同。这是一个由构造函数创建的,构造函数会创建很多属性和方法。在你创建promise时,有几个需要特别注意的地方:
1、promise需要一个executor,是这样的,我们需要这个executor来异步地控制,我们的结果是否得到了;
2、promise有它自己的内部状态(这些内部状态我们不能直接获得或修改)。每个promise的状态,开始的时候都是“pending”。Promise整个生命周期中,只会改变一次:从pending变成fullfilled(做完了它的事情了),或者从pending变成rejected(噫……挂掉了)。一旦promise的状态发生了改变,它的状态不会变回pending了。它的状态也不能从fulfilled变成rejected,或者从rejected变成fulfilled。一个promise的状态,只会变化一次。这个设置真的很赞,我们可以通过查看promise的状态,来决定我们跑的是哪个回调函数(这些回调函数,我们有的是标记为error-case,有的标记为success-case)。一旦promise的状态是non-pending,我们就可以根据它的状态来决定我们想做的事情了。
3、promise是有值的,如果这个值是success case,我们就拿到了我们想要的数据,如果这个值是error,那么是中间除了问题。Promise的值,会是一个error或者data,这两者中的一个,一旦状态改变(即前面的由pending变为error或fullfilled了),不仅状态不能再发生变化了,值也不能发生变化了,promise的值与promise本身是息息相关的。讲真,我们不希望promise的状态是乱变的,那样太不可控了。
4、最后,一个promise能成为promise,首先它得有“then”函数(我们待会儿会深入讨论这个东西)。这是我们在嵌套回调的时候,需要的东西——在then函数里,我们会处理异步操作的结果。
Part Ⅲ 应用Promises
我们一般在两种情况下,会使用到promises。在JavaScript中,我们可以用构造函数来实例化创建promise,回调的内容还有执行环境都需要我们自己来做。这可能看起来有些奇怪,因为这看起来比普通回调差不多,但是呢,promise肯定是比普通的回调函数看起来更整洁,这些奇观的部分,都是在定义的时候看起来奇怪而已。在实际应用中,我们可以很方便地在任何地方调用promise,将触发器(handlers)在任何地方跟promise绑定(我们甚至可以对同一个promise绑定多个不是链式的触发器(handlers))。
更常见的情况是,我们在开发应用过程中使用的库,实际上含有promises。比方说,帮助我们创建数据库模式(database schema),将我们从可怕的SQL查询语句中解救出来的Sequelize库,对一些数据库的操作就支持promise,所以我们可以很容易地将一些操作当成变量来看。
到这里介绍的promises的功能也不过是它的惊鸿一瞥,每个promise都有一个叫做“then”的方法。它的意思跟字面的英文单词then的意思一毛一样,直接按照字面意思理解就好。如果你使用了一个promise,那么它的值会被设定(resolve或reject),之后then方法里的code,也就是一般在callback里的code会被运行。有个更方便的地方是,我们传入then函数中的参数,会被自动当成结果的data或者error出现。
但是promise的强大功能当然不仅仅局限于此,用一个then函数肯定不能体现它的强大,也用的不够爽。我们在前面讨论过有很多不同的异步操作会是一个什么景象(也就是前面提到过的,回调无底洞),当有很多个异步操作的时候,promises的好处就体现出来了,在promise中,这些异步操作可以用一个链式地操作来进行。上一个返回的值是下一个promise,下一个promise会接收到上一个promise返回的数据,或者是一个error。
突然,我们一下子就能控制这些异步函数了(起码我们能够保证,当result有数据时,reliantNewPromise执行,当thatPromiseReturnValue有数据时,weCouldDoThisAllDayPromise函数才会执行),我们同时也能够保证,每个得到信息的函数都能够很高效地跑起来。还有一个好处,这看起来贼清楚。
Part Ⅳ 我们每个人都会犯错,或者至少会有错的地方
我们之前讨论的回调函数,最让我们烦躁的是error的管理非常混乱。不过呢,用上promises,管理错误信息就非常方便了。首先呢,promises刚开始处理的是成功的data结果,第二个处理的,才是error,所以我们可以直接处理第二个err值。两个值都处理了,我们的程序就有能力应付所有的情况了。
Promises还给了我们一些异步回调函数做不到的事情,promise允许我们将err传递下去,也就是说,如果第一个then里,没有对err的处理,那么这个错误会传递到下一个then里面,直到它找到能够处理错误的回调函数的代码。所以在promise中,我们可以用两个分离的then函数来分别处理success和error,在第二个then函数中,我们可以设置第一个参数为“null”。
但是呢,还可以更好,当error被抛出的时候,我们可能还想干一点什么事情(比方说,想要把这些错误信息输出到控制台,或者把这些错误信息输出到浏览器,并告诉这个浏览器,有些不好的事情发生了)。想想,如果我们能在一个地方一下子处理好几个错误,那该多爽。因为有了上面说的冒泡机制,我们可以全部用then函数,来处理success,最后,我们用一个超级有用的“catch”函数来处理error。这有点像JavaScript中的try/catch模块,任何被抛出的错误都会被catch模块捕捉,然后在catch的回调函数中进行处理,这样就可以避免写很多处理error的代码。
简而言之,promise就是根据它内部的状态决定,应该运行什么情况下的代码。当promise的状态是“pending”的时候(假设因为某些原因,promise的状态一直悬而未决),那么没有回调函数会被执行,一旦状态确定下来,要么success的代码会被执行,要么error的代码会被执行,没有中间状态,没有说是success和error都会被处理的情况。这也是为什么,promise的状态只允许更改一次的原因。
Part Ⅴ 最后一发
上面的例子如果你按照顺序看了一遍的话,你或许已经发现,promises允许我们函数化地运行我们的代码,也允许我们根据之前提高过的处理error的方式,使用冒泡处理error和success。更棒的是,我们管理和理解我们请求的数据变得更容易了。Promises里面也有Promise.all()来让我们能够一下子合并好多个promise处理的结果——那也就是说,如果我们想要一次获取数据的话,我们可以一把拿到所有的promise数据。示例如下:
在这个示例中,我们有一个promise数组,他们之间的success关系并不相互依赖,但是我们想以他们全部的success作为success,他们当中有一个fail,则认为该promise为fail。当我们把promise数组传入Promise.all时,如果每个promise都是resolve,最后结果为resolve,如果有一个是reject,会返回第一个被reject的原因。如果按照我们设想的,所有的结果都为resolve,那么返回的结果会是所有promise的data组成的数组——不用管哪个promise先被resolve了。这很简单吧?
我们来把这些内容再串一下。
1、Promises为了解决无穷无尽的回调嵌套,给了我们一个很简单的链式的异步操作——使得我们的代码又一次变成了我们喜欢的线性的;
2、Promises还给了我们简单的,统一的处理error的方;
这些使得我们的异步操作更方便——我们可以把这个操作放在一边,然后等到这个操作完成了之后,再决定做什么,这些promises在时间上是独立的,所以我们可以在任何时间,任何地点,设置handler去处理这些promises,仍然能够保证这些success或error处理能够完美地跑起来。
Promise能够快速构建,同时也比普通的回调函数更加轻量级,所以,如果遇到需要回调函数做的事情,一般考虑一下使用Promises。不幸的是,promises并不能解决我们的所有问题,比方说,它不能解决加载数据比较慢的问题。也不能确保代码会在promise的状态被确定之后,再运行某些代码。这些问题可以搜索异步延迟(async await)。