卷积神经网络(四)-GoogLeNet
卷积神经网络(一)-LeNet
卷积神经网络(二)-AlexNet
卷积神经网络(三)-ZF-Net和VGG-Nets
卷积神经网络(四)-GoogLeNet
卷积神经网络(五)-ResNet
卷积神经网络(六)-DenseNet
GoogLeNet在2014的ImageNet分类任务上击败了VGG-Nets夺得冠军,其实力肯定是非常深厚的,GoogLeNet跟AlexNet,VGG-Nets这种单纯依靠加深网络结构进而改进网络性能的思路不一样,它另辟幽径,在加深网络的同时(22层),也在网络结构上做了创新,引入Inception结构代替了单纯的卷积+激活的传统操作(这思路最早由Network in Network提出)。GoogLeNet进一步把对卷积神经网络的研究推上新的高度
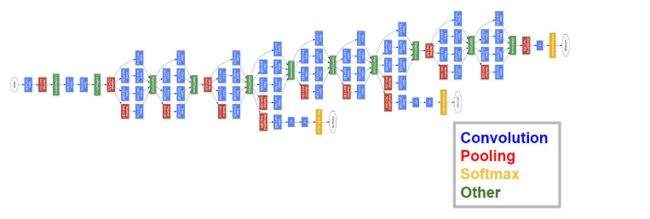
闪光点:
- 引入Inception结构
- 中间层的辅助LOSS单元
- 后面的全连接层全部替换为简单的全局平均pooling
-
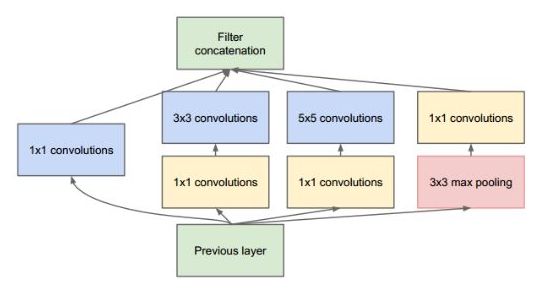
上图结构就是Inception,结构里的卷积stride都是1,另外为了保持特征响应图大小一致,都用了零填充。最后每个卷积层后面都立刻接了个ReLU层。在输出前有个叫concatenate的层,直译的意思是“并置”,即把4组不同类型但大小相同的特征响应图一张张并排叠起来,形成新的特征响应图。Inception结构里主要做了两件事:1. 通过3×3的池化、以及1×1、3×3和5×5这三种不同尺度的卷积核,一共4种方式对输入的特征响应图做了特征提取。2. 为了降低计算量。同时让信息通过更少的连接传递以达到更加稀疏的特性,采用1×1卷积核来实现降维。
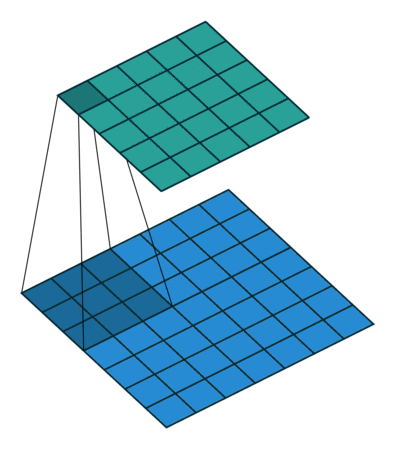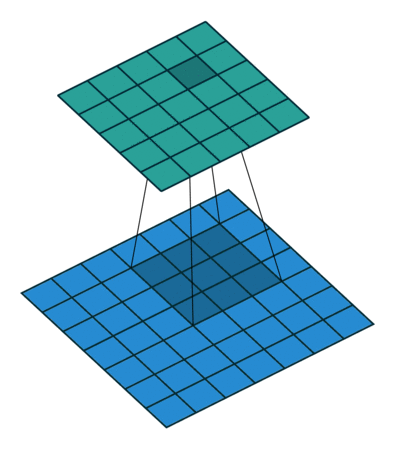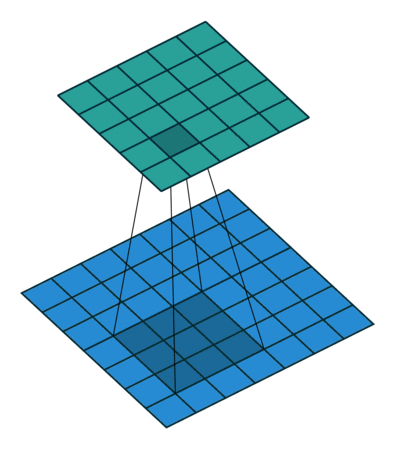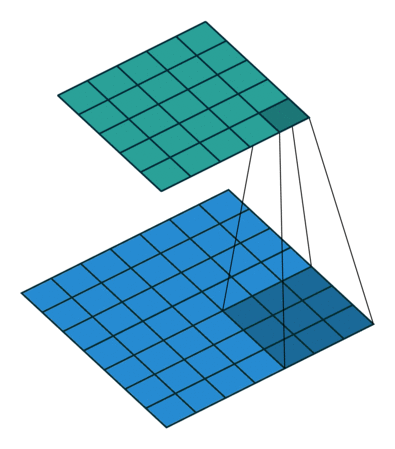
这里想再详细谈谈1×1卷积核的作用,它究竟是怎么实现降维的。现在运算如下:下面图1是3×3卷积核的卷积,图2是1×1卷积核的卷积过程。对于单通道输入,1×1的卷积确实不能起到降维作用,但对于多通道输入,就不不同了。假设你有256个特征输入,256个特征输出,同时假设Inception层只执行3×3的卷积。这意味着总共要进行 256×256×3×3的卷积(589000次乘积累加(MAC)运算)。这可能超出了我们的计算预算,比方说,在Google服务器上花0.5毫秒运行该层。作为替代,我们决定减少需要卷积的特征的数量,比如减少到64(256/4)个。在这种情况下,我们首先进行256到64的1×1卷积,然后在所有Inception的分支上进行64次卷积,接着再使用一个64到256的1×1卷积。
- 256×64×1×1 = 16000
- 64×64×3×3 = 36000
- 64×256×1×1 = 16000
现在的计算量大约是70000(即16000+36000+16000),相比之前的约600000,几乎减少了10倍。这就通过小卷积核实现了降维。
现在再考虑一个问题:为什么一定要用1×1卷积核,3×3不也可以吗?考虑[50,200,200]的矩阵输入,我们可以使用20个1×1的卷积核进行卷积,得到输出[20,200,200]。有人问,我用20个3×3的卷积核不是也能得到[20,200,200]的矩阵输出吗,为什么就使用1×1的卷积核?我们计算一下卷积参数就知道了,对于1×1的参数总数:20×200×200×(1×1),对于3×3的参数总数:20×200×200×(3×3),可以看出,使用1×1的参数总数仅为3×3的总数的九分之一!所以我们使用的是1×1卷积核。
GoogLeNet网络结构中有3个LOSS单元,这样的网络设计是为了帮助网络的收敛。在中间层加入辅助计算的LOSS单元,目的是计算损失时让低层的特征也有很好的区分能力,从而让网络更好地被训练。在论文中,这两个辅助LOSS单元的计算被乘以0.3,然后和最后的LOSS相加作为最终的损失函数来训练网络。
GoogLeNet还有一个闪光点值得一提,那就是将后面的全连接层全部替换为简单的全局平均pooling,在最后参数会变的更少。而在AlexNet中最后3层的全连接层参数差不多占总参数的90%,使用大网络在宽度和深度允许GoogleNet移除全连接层,但并不会影响到结果的精度,在ImageNet中实现93.3%的精度,而且要比VGG还要快。
GoogLeNet的Keras实现:
def Conv2d_BN(x, nb_filter,kernel_size, padding='same',strides=(1,1),name=None):
if name is not None:
bn_name = name + '_bn'
conv_name = name + '_conv'
else:
bn_name = None
conv_name = None
x = Conv2D(nb_filter,kernel_size,padding=padding,strides=strides,activation='relu',name=conv_name)(x)
x = BatchNormalization(axis=3,name=bn_name)(x)
return x
def Inception(x,nb_filter):
branch1x1 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch3x3 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch3x3 = Conv2d_BN(branch3x3,nb_filter,(3,3), padding='same',strides=(1,1),name=None)
branch5x5 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch5x5 = Conv2d_BN(branch5x5,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branchpool = MaxPooling2D(pool_size=(3,3),strides=(1,1),padding='same')(x)
branchpool = Conv2d_BN(branchpool,nb_filter,(1,1),padding='same',strides=(1,1),name=None)
x = concatenate([branch1x1,branch3x3,branch5x5,branchpool],axis=3)
return x
def GoogLeNet():
inpt = Input(shape=(224,224,3))
#padding = 'same',填充为(步长-1)/2,还可以用ZeroPadding2D((3,3))
x = Conv2d_BN(inpt,64,(7,7),strides=(2,2),padding='same')
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Conv2d_BN(x,192,(3,3),strides=(1,1),padding='same')
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,64)#256
x = Inception(x,120)#480
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,128)#512
x = Inception(x,128)
x = Inception(x,128)
x = Inception(x,132)#528
x = Inception(x,208)#832
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,208)
x = Inception(x,256)#1024
x = AveragePooling2D(pool_size=(7,7),strides=(7,7),padding='same')(x)
x = Dropout(0.4)(x)
x = Dense(1000,activation='relu')(x)
x = Dense(1000,activation='softmax')(x)
model = Model(inpt,x,name='inception')
return model