阿里云智能运维的自动化三剑客

整理 | 王银
出品 | AI科技大本营(ID:rgznai100)
近日,2019 AI开发者大会在北京举行。会上,近百位中美顶尖AI专家、知名企业代表以及千余名AI开发者进行技术解读和产业论证。而在AI+DevOps论坛上,阿里巴巴高级技术专家滕圣波就阿里云与智能运维的发展之路对智能运维自动化三剑客——弹性伸缩、资源编排和运维编排进行了重点介绍。
在介绍自动化三剑客之前,滕圣波为我们讲述了阿里的上云路和智能运维的发展策略。
以双十一为例,阿里集团的业务量往年只有60%~70%承载在阿里云上,而今年将百分之百跑在公有云上。这意味着阿里云就是整个阿里集团的运维——将创建机器、计算力、存储、网络和管理机器及数据库这些本质上都是运维的要做的事进行代码化和自动化。
由此可见,阿里云已经成为阿里集团的技术底座。滕圣波还表示,未来阿里云集团的技术输出只通过阿里云,并且技术全面开放,从而达到集团和生态共享,促进互联网生态发展。
既然阿里云担当了整个集团的运维一角色,那传统运维人员又该何去何从?这本质上也是DevOps的问题。滕圣波以这么一个场景为例给出答案:半夜有一个严重告警,目前的机制是系统一旦出现异常,就会把相关开发或负责人叫起来。这意味着,截至目前,人工职守无可避免。但是阿里云的目标是无人职守,毕竟一周连续四次都被凌晨叫起来去处理告警身体是吃不消的。想象一下一个运维人员半夜起来看日志、采取动作;动作是什么?无非就是机器不够用了、代码多了、负载多了,如果加机器加资源解决不了就回滚代码。这些肯定都是可以自动化的,顺势而为,人工智能必成发展突破口。
我们都知道阿里云有SLA,而所有都是从架构出发的,但是架构不仅仅是阿里云的事情,也是客户的事情。一个架构是针对容量规划的,针对1万人的架构和针对1亿人的架构一定是不一样的。众所周知,企业都不是一开始就走到1亿人这个步骤,而是从1万人慢慢成长起来的。企业成长过程中需要不断调整自己的架构和运维。所以无人职守并不只是阿里云的职责,也是客户的职责。
简言之,“从运维到SRE,无人值守是目的,自动化是无人值守的手段,而人工智能又是自动化的手段之一。其中,无人值守的最后一公里由客户侧运维开发。”

而后滕圣波为我们重点介绍了自动化三剑客。
第一便是弹性伸缩——即基于AI预测的弹性伸缩。原有监控指标模式,监控指标变化敏感,引起实例数量震荡,扩、缩容操作和业务变化存在延迟;智能预测模式可以做到预测业务变化智能调整实例数量,结合目标追踪模式完美贴合业务变化,能够最大程度地节省成本。

我们知道大多数公司的业务都是有流量曲线的,有高峰、有低谷,那对应的业务承载能力如何得知?好比双十一,阿里云在双十一有庞大体量,它所承载的业务量一定是在双十一之前按照顶峰就计算好的。但是这有什么问题?比如双十一之前阿里云有预估,通过全链路的压力测试知道需要准备多少资源,但是问题也来了,我们要提取多久准备这个资源?这是个成本的问题,资源是很贵的,如果我们提前1个月准备资源可能就多几亿元的成本负担在上面;如果我们能够提前1小时准备这个资源,那我就可能节省出来很多资源。越能够灵活地准备自己的资源,就越能够省钱,省钱极致到什么程度?最多能省多少钱?如图所示,容量上限和曲线之间的面积是我们最多能省的钱,这是弹性伸缩最大的价值。可惜,理想很丰满,现实很骨感。弹性伸缩很难把所有的成本都省出来。
弹性伸缩具体是怎么应用的?以下用两个例子来说明。
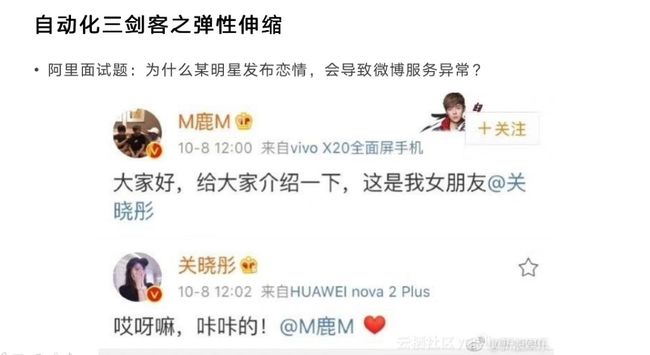
先看上面这张图,从技术角度分析为什么会出这个问题。首先发生的事情是一大堆狂点赞,这两个人的粉丝量加起来是巨大的。如果这些粉丝只狂点赞还好,赞就是数据库里多一条消息,多一条数据记录。赞并不难,难的是转发。转发这个事情太恐怖了,它不仅仅是克隆,在数据库里多几条记录。转发造成了更多消息流推送,消息量瞬间几何倍增。比如一开始100万人看到这个消息,里面有10万人转发,迅速在整个网络里造成了大量消息,挤占了大量网络,造成了大量数据库写操作。
读不可怕,因为读的话可以做分级、可以做CDN,但写这个东西太夸张了,写是必须真实的往数据库里做操作的。而且数据库当时有大量的缓存,而写不是缓存的特点,所以一下子就被打穿,接着就成为数据库的累赘了。在疯狂写数据的时候,数据库突然崩了,那么服务就会限流。但限流对于很多用户来讲是不可接受的,他会认为是服务宕掉了。这时候我们就可以用弹性伸缩去解决。有两个思路,一个是一定要快,快是什么概念?
大家看看基于监控逐步转化的预测,有很多都是基于监控指标的算法。当你的曲线已经开始往上走时,监控一定是第一时间能发现的,这时候我们能做的是赶紧扩充自己的计算资源、存储资源、数据库、缓存,可是实际上我们资源扩充的真实情况是滞后的。为什么?监控指标出现动作时意味着流量已经来了,这时候弹指标已经迟了、跟不上了。阿里云上弹一个指标大概十几秒,这个十几秒对一个突发的新闻事件来说是不够快的,有可能它涨了1倍了,资源才涨了30%。所以弹性计算、弹性伸缩最核心的就是要做到快。
再比如用户抢火车票或者干什么生意,火车票发售一定有个高峰,负载一下子涨了5倍是非常恐怖的,相当于多了4000台机器。但是4000台机器对阿里云来讲是万分之一、千分之一,是流量上出现一个很平滑的不太引人注意的小刺而已。我们的弹性伸缩有提前准备的库存 ,这就是资源大的优势,本身也是云的优势。
但是再快也不一定足够快,即便预测流量来了,可是如果用户连5秒都不愿意承担损失 ,那怎么办?只能预测,在洪峰到来前就把资源准备好。对此,阿里有智能预测模式。不过目前还有局限性——只在有规律的场景下做得很好,例如定点发售火车票。而头条、微博、等等弹性伸缩不完全依赖于阿里云,阿里云有机器学习算法、动态预测、实时告警等等基于监控很快帮客户做弹性,但是最了解客户业务的一定是客户自己,所以很多时候还得结合客户的具体业务提前把资源准备好。
说到资源,自然就要引出另外一个三剑客——资源编排。阿里云资源编排-ROS,可以实现提交代码资源自动修改,版本化管理、随时回滚以及Copy/paste完成资源成套复制。

上面是一个经典的网上应用的架构图,能看得出它有四点困境。
第一,需要更多资源。一般情况下,在一个阿里云上,随着业务的增长,需要的阿里云资源会越来越多,可能需要10个、20个、30个。阿里云上现在有300多种多少资源,都是客户经常会用到的资源,随着资源越来越多,怎么管理是关键问题。CMDB是很流行的管理办法,但是它无法保证自己永远是最新的并且永远跟实际相吻合。
第二点是历史记录的存储问题。阿里云对ECS的历史记录不做保留 ,需要客户保留,资源编排就是一个很好的办法。
第三是准确操作问题,因为人是一定会犯错的。有这么一个场景:某一天一个阿里员工在操作VIP时引发一个故障,这个故障直接导致大量北京区域的很多ECS不可服务了。大家可能会责怪这个运维,但是是运维的责任吗?这是典型的让运维做背锅侠,最深层次的原因是自动化。没有什么人不会出错,除非让机器去操作,一个经过测试过的程序,让它再跑一遍是最不容易出错的,其他情况下都可能出错。所以要想不出错,就像代码那样把资源编排写成个代码,测试之后线上跑一遍,这才是万全之策。
最后一点就是重复操作问题。企业并不是只有一个区域、一个环境,他们大多有开发环境、线上环境等等,这些环境可能只有一点点区别,我们不可能每个都重复来一遍,所以用资源编排就可以很好的解决这点。
那现实资源编排具体是怎么实现的呢?阿里云提供一个资源编排的服务。比如把代码文件提交到代码库里,提交之后会发现阿里云上多了一服务器。另外,版本管理copy/paste完成资源成套复制。可能听起来有点模糊,所以腾圣波老师为我们讲述来一个真实的使用场景:云产品是分级的,最底层的是云存储等等,容服务器是架设在之上的。上层的产品对客户提供服务时一定会用到底层的产品,比如我们买了一个数据库,实际上我们是买了一个云服务器+数据库软件,但是这个云服务器是我们看不到的,是数据库这个产品帮我们运维了服务器。
容器也一样,我们买了容器,底下一定是有服务器的,我们看不到服务器,是因为容器产品帮我们运维了服务器。而容器服务我们可以一键部署。这是ROS控制台,一键部署本质上是做什么?这个文本文件描述了环境,VCP是网络,接下来点击创建,它就会自动帮你做,这就是ROS的模板。如果需要修改VPC,直接把VCP属性修改就可以来。
但为什么用阿里云的ROS?无非是资源编排有两个难点 :第一点是事务。什么叫事务?一个文档有十几个资源,涉及到回滚、加速 。另外一点是状态。今天一台ECS,明天两台ECS,把模板从1改到2,要2-1=1,然后要再创建1台并对比版本的差异,如此自建编排就复杂了很多,所以大家可以尝试使用阿里云的资源编排。
运维编排是自动化最后一位剑客,专门解决背锅侠、自建DevOps平台、事件消费的问题。
运维是事件驱动的。以前大家可能没注意到,因为在此之前运维是人工驱动的。比如你收到一个电话是个事件,事件驱动人去做运维。而自动化运维不应该这样,云监控产生一个告警事件,这个告警应该自动驱动工作,这是自动化运维。事件驱动为什么很难?因为做监控一定要做到不重不漏。不漏可以理解,通过ACK确认机制保证事件交付到位。一个事件发给你,你必须给我回ACK,我才知道你收到了,不然我就不停给你发,这样保证不漏。
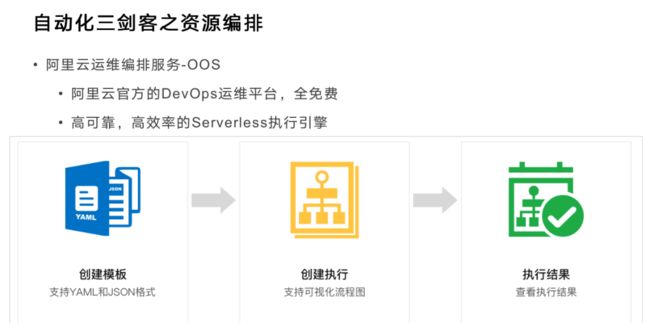
可是我们无法保证不重。消费端去处理,消费端无法不重。事件有ID,例如ID为1表示消费过,为0表示没消费过,并行消费时把它指成1就会产生bug。如果用原子锁,当ID是1时表示第一次消费,当ID是2时表示第二次消费……那这就相当繁琐沉重了。为此推出OOS——阿里云的官方运维编排服务平台,是高效、高可靠的serverless执行引擎,只需要写模板,然后执行,从而保证秒级的处理。
技术不断在进步,阿里云智能运维技术已经成为新运维演化的一个开端,我们期待在更多的高效的优质平台实践之后,智能运维能壮大整个IT领域!
原文链接:https://zhuanlan.zhihu.com/p/82363522
◆
精彩推荐
◆
推荐阅读
我所理解的零次学习
华为全球最快AI训练集群Atlas 900诞生
还怕电脑被偷吗?我用Python偷偷写一个自动木马程序
用Python进行金融市场文本数据的情感计算
前端也能玩转机器学习?Google Brain 工程师来支招!
华为 | 泰山之巅 鲲鹏展翅 扶摇直上九万里
6大思维模型, 揭秘硅谷高管如何做区块链应用决策
走出腾讯和阿里,大厂员工转型记

你点的每个“在看”,我都认真当成了喜欢“