2020字节跳动提前批——抖音客户端一面
1.个人经历
1.自我介绍
2.有无客户端开发经验
2.计算机基础知识
1.进程间的通信方式
1.管道(Pipe):管道可用于具有亲缘关系进程间的通信,允许一个进程和另一个与它有共同祖先的进程之间进行通信。
2.命名管道(named pipe):命名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。命名管道在文件系统中有对应的文件名。命名管道通过命令mkfifo或系统调用mkfifo来创建。
3.信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数)。
4.消息(Message)队列:消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
5.共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
6.内存映射(mapped memory):内存映射允许任何多个进程间通信,每一个使用该机制的进程通过把一个共享的文件映射到自己的进程地址空间来实现它。
7.信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
8.套接口(Socket):更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
2.物理内存、虚拟内存
物理内存:真实的硬件设备(内存条)
虚拟内存:利用磁盘空间虚拟出的一块逻辑内存,用作虚拟内存的磁盘空间被称为交换空间(Swap Space)。(为了满足物理内存的不足而提出的策略)
每个程序都拥有自己的地址空间,这个地址空间被分成大小相等的页,这些页被映射到物理内存;但不需要所有的页都在物理内存中,当程序引用到不在物理内存中的页时,由操作系统将缺失的部分装入物理内存。这样,对于程序来说,逻辑上似乎有很大的内存空间,只是实际上有一部分是存储在磁盘上,因此叫做虚拟内存。
虚拟内存的优点是让程序可以获得更多的可用内存。
3.JVM模型
4.原子性,顺序性,可见性
1.原子性:一个的操作或者多次操作,要么所有的操作全部都得到执行并且不会受到任何因素的干扰而中断,要么所有的操作都执行,要么不执行。synchronized可以保证代码片段的原子性。
2.可见性:当一个变量对共享变量进行了修改,那么另外的线程都是立即可以看到修改后的最新值。volatile关键字可以保证共享变量的可见性。
3.有序性:代码在执行的过程中的先后顺序,Java在编译器以及运行期间的优化,代码的执行顺序未必就是编写代码时候的顺序。volatile关键字可以禁止指令进行重排序优化。
5.Python开头的编码方式以及作用
文件的编码格式和编码声明的作用
文件编码格式
源文件的编码格式对字符串的声明有什么作用呢?
文件的编码格式决定了在该源文件中声明的字符串的编码格式。
例如:
str = ‘哈哈’
print repr(str)
a.如果文件格式为utf-8,则str的值为:’\xe5\x93\x88\xe5\x93\x88’(哈哈的utf-8编码)
b.如果文件格式为gbk,则str的值为:’\xb9\xfe\xb9\xfe’(哈哈的gbk编码)
python中的字符串,只是一个字节数组,所以当把a情况的str输出到gbk编码的控制台时,就将显示为乱码:鍝堝搱;而当把b情况下的str输出utf-8编码的控制台时,也将显示乱码的问题,是什么也没有,也许’\xb9\xfe\xb9\xfe’用utf-8解码显示,就是空白吧。
编码声明的作用
每个文件在最上面的地方,都会用# coding=gbk 类似的语句声明一下编码,但是这个声明到底有什么用呢?到止前为止,我觉得它的作用也就是三个:
1.声明源文件中将出现非ascii编码,通常也就是中文;
2.在高级的IDE中,IDE会将你的文件格式保存成你指定编码格式。
3.决定源码中类似于u’哈’这类声明的,解码是选择的解码格式。
6.TCP拥塞控制
在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络性能就要变坏,这种情况就叫做网络拥塞。
在计算机网络中数位链路容量(即带宽)、交换结点中的缓存和处理机等,都是网络的资源。
若出现拥塞而不进行控制,整个网络的吞吐量将随输入负荷的增大而下降。

当输入的负载到达一定程度 吞吐量不会增加,即一部分网络资源会丢失掉,网络的吞吐量维持在其所能控制的最大值,转发节点的缓存不够大这造成分组的丢失是拥塞的征兆。
TCP的四种拥塞控制算法
1.慢开始
2.拥塞控制
3.快重传
4.快恢复
假定:
1.数据是单方向传送,而另一个方向只传送确认
2.接收方总是有足够大的缓存空间,因而发送发发送窗口的大小由网络的拥塞程度来决定
3.以TCP报文段的个数为讨论问题的单位,而不是以字节为单位
示例如下:
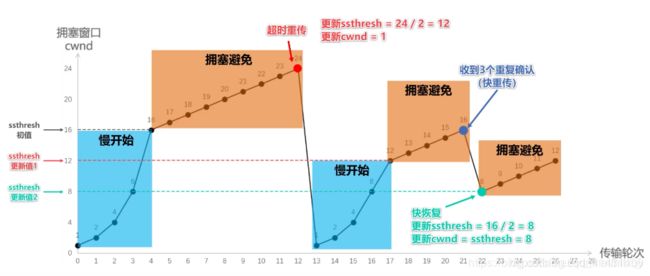
传输轮次:发送方给接收方发送数据报文段后,接收方给发送方发回相应的确认报文段,一个传输轮次所经历的时间就是往返时间RTT(RTT并非是恒定的数值),使用传输轮次是为了强调,把拥塞窗口cwnd所允许发送的报文段都连续发送出去,并收到了对已发送的最后一个报文段的确认,拥塞窗口cwnd会随着网络拥塞程度以及所使用的拥塞控制算法动态变化。
在tcp双方建立逻辑链接关系时, 拥塞窗口cwnd的值被设置为1,还需设置慢开始门限ssthresh,在执行慢开始算法时,发送方每收到一个对新报文段的确认时,就把拥塞窗口cwnd的值加一,然后开始下一轮的传输,当拥塞窗口cwnd增长到慢开始门限值时,就使用拥塞避免算法。
慢开始:
假设当前发送方拥塞窗口cwnd的值为1,而发送窗口swnd等于拥塞窗口cwnd,因此发送方当前只能发送一个数据报文段(拥塞窗口cwnd的值是几,就能发送几个数据报文段),接收方收到该数据报文段后,给发送方回复一个确认报文段,发送方收到该确认报文后,将拥塞窗口的值变为2,
发送方此时可以连续发送两个数据报文段,接收方收到该数据报文段后,给发送方一次发
回2个确认报文段,发送方收到这两个确认报文后,将拥塞窗口的值加2变为4,发送方此
时可连续发送4个报文段,接收方收到4个报文段后,给发送方依次回复4个确认报文,发
送方收到确认报文后,将拥塞窗口加4,置为8,发送方此时可以连续发送8个数据报文
段,接收方收到该8个数据报文段后,给发送方一次发回8个确认报文段,发送方收到这8
个确认报文后,将拥塞窗口的值加8变为16,
当前的拥塞窗口cwnd的值已经等于慢开始门限值,之后改用拥塞避免算法。
拥塞避免:
也就是每个传输轮次,拥塞窗口cwnd只能线性加一,而不是像慢开始算法时,每个传输轮次,拥塞窗口cwnd按指数增长。同理,16+1……直至到达24,假设24个报文段在传输过程中丢失4个,接收方只收到20个报文段,给发送方依次回复20个确认报文段,一段时间后,丢失的4个报文段的重传计时器超时了,发送发判断可能出现拥塞,更改cwnd和ssthresh.并重新开始慢开始算法,如图所示:


快速重传:
发送方发送1号数据报文段,接收方收到1号报文段后给发送方发回对1号报文段的确认,在1号报文段到达发送方之前,发送方还可以将发送窗口内的2号数据报文段发送出去,接收方收到2号报文段后给发送方发回对2号报文段的确认,在2号报文段到达发送方之前,发送方还可以将发送窗口内的3号数据报文段发送出去,
假设该报文丢失,发送方便不会发送针对该报文的确认报文给发送方,发送方还可以将发
送窗口内的4号数据报文段发送出去,接收方收到后,发现这不是按序到达的报文段,因此
给发送方发送针对2号报文段的重复确认,表明我现在希望收到的是3号报文段,但是我没
有收到3号报文段,而收到了未按序到达的报文段,发送方还可以将发送窗口中的5号报文
段发送出去,接收方收到后,发现这不是按序到达的报文段,因此给发送方发送针对2号报
文段的重复确认,表明我现在希望收到的是3号报文段,但是我没有收到3号报文段,而收
到了未按序到达的报文段,,发送方还可以将发送窗口内的最后一个数据段即6号数据报文
段发送出去,接收方收到后,发现这不是按序到达的报文段,因此给发送方发送针对2号报
文段的重复确认,表明我现在希望收到的是3号报文段,但是我没有收到3号报文段,而收
到了未按序到达的报文段,
此时,发送方收到了累计3个连续的针对2号报文段的重复确认,立即重传3号报文段,接收方收到后,给发送方发回针对6号报文的确认,表明,序号到6为至的报文都收到了,这样就不会造成发送方对3号报文的超时重传,而是提早收到了重传。


7.TCP流量控制
**TCP利用滑动窗口实现流量控制。流量控制是为了控制发送方发送速率,保证接收方来得及接收。**接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为0,则发送方不能发送数据。
8.HTTP的请求方式除了get和post,还有什么?
HEAD
与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”(元信息或称元数据)。
PUT
向指定资源位置上传其最新内容。
DELETE
请求服务器删除Request-URI所标识的资源。
OPTIONS
返回服务器支持的HTTP方法
CONNECT
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的链接(经由非加密的HTTP代理服务器)。
TRACE
回显服务器收到的请求,主要用于测试或诊断。
9.GET和POST的区别
1、GET是获取数据的,而POST是提交数据的。
2、GET 用于获取信息,是无副作用的,是幂等的,且可缓存, 而POST 用于修改服务器上的数据,有副作用,非幂等,不可缓存。
10.Python如何把一个字符串变成字符串对象
11.Java中的voliate关键字
voliate关键字的主要作用就是保证变量的可见性然后还有一个作用就是防止指令重排序。
12.逻辑(虚拟)地址,物理地址
我们编程一般只有可能和逻辑地址打交道,比如在C语言中,指针里面存储的数值就可以理解成为内存里的一个地址,这个地址也就是我们说的逻辑地址,逻辑地址由操作系统决定。物理地址指的是真实物理内存中地址,更具体一点来说就是内存地址寄存器中的地址。物理地址是内存单元真正的地址。
13.了解设计模式吗?
14.TCP头部有哪些字段?
源端口号:
发送端口数据出去的端口 0-65535
目标端口号:
需要访问的目标主机的端口号 0-65535
序列号:
传输层运单的编号 100
确认号:
到底收到了发送方的哪个报文 发送端序列号+1 100+1=101
控制位:
SYN=1 发起连接
FIN=1 中断连接
ACK=1 确认消息
RST=1 重置连接
URG=1 开启紧急指针
PSH=1 启用数据缓冲
窗口大小:
协商发送数据的大小
2.算法题
1.两个链表的第一个公共节点
解题思路:
我们使用两个指针node1,node2分别指向两个链表headA,headB的头节点,然后同时分别逐结点遍历。当node1到达链表headA的末尾时,重新定位到链表headB的头结点;当node2到达链表headB的末尾时,重新定位到链表headA的头结点。这样,当它们相遇时,所指向的结点就是第一个公共结点。
Python代码
class Solution:
def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:
node1 = headA
node2 = headB
while node1 != node2:
node1 = node1.next if node1 else headB
node2 = node2.next if node2 else headA
return node1
复杂度分析
时间复杂度:O(m + n)
空间复杂度:O(1)
2.整数反转
给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转。
示例1:
输入: 123
输出: 321
示例2:
输入: -123
输出: -321
示例3:
输入: 120
输出: 21
注意:
假设我们的环境只能存储得下 32 位的有符号整数,则其数值范围为 [−231, 231 − 1]。请根据这个假设,如果反转后整数溢出那么就返回 0。
Java代码
public int reverse(int x){
int ans = 0;
while(x != 0){
if((ans * 10) / 10 != ans){
ans = 0;
break;
}
ans = ans * 10 + x % 10;
x = x / 10;
}
return ans;
}
其中,
if((ans * 10) / 10 != ans){
ans = 0;
break;
}
如果反转整数发生数值溢出,直接返回0,因为 ans * 10如果超出范围,自动为0,ans * 10 / 10 自然不等于 ans。