python-爬虫:获取163邮箱的收件箱信息列表
在练习python爬虫的时候看到了原博主的关于爬取163邮箱收件箱信息列表的文章,就拿来练手了。这里附上原博客链接https://blog.csdn.net/u011379247/article/details/51019379
由于原文用的是python2.X,浏览器的版本也比较早。而本人用的是python3.6,浏览器也是新版本,所以还是有些不一样的地方值得摸索的。
主要内容:
1. 模拟163邮箱的登陆
2. 获取登陆后的收件箱页面
3. 获取页面中的邮件信息
思路:
1. 用浏览器登陆邮箱以获取请求登陆的url以及收件箱网页的url
2. 向该url发送登陆请求,获得response,并利cookie缓存登陆的信息及状态
3. 提取response中的sid码,这是下一步请求所需要的
4. 利用sid码和cookie重新请求,获得响应,重定向至收件箱网页,获取页面信息
5. 提取邮件信息
前期准备:
首先,进入163邮箱登陆页面:https://mail.163.com/ 我用的是chrome,在这个页面中右键-检查-network,就可以看到如下界面,要注意的是,这里要勾上preserve log选项,这样能保证页面在切换的时候,之前的日志不会被清除掉。
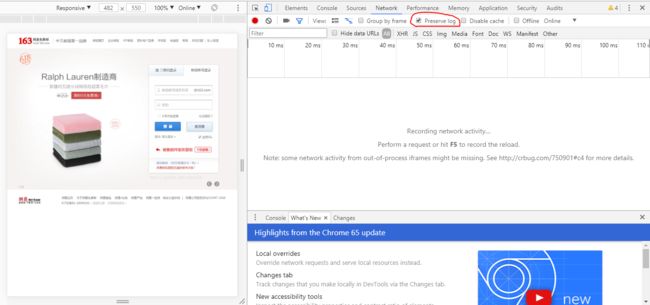
接下来,输入用户名和密码并点击登陆(此时鼠标的箭头应该变成了圆点),登陆后就会出现如下界面
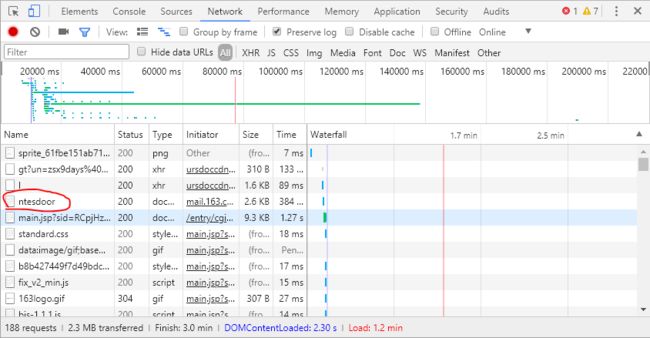
单击ntesdoor日志,这个这就是登录时提交的参数信息,右边会出现请求的详细信息
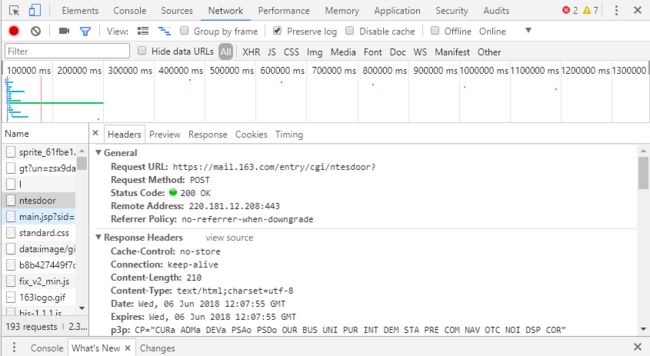
可以看到Request URL,这个URL与现在浏览器中的地址不同,因为这是我们请求登陆的页面,我们要将用户名密码等参数信息一起发送给这个页面才能登陆得到现在我们浏览器中的页面。
这里不知道是版本的问题还是什么,Request URL和原博客不一样,后面少了一串参数,这串参数在下面的From Data中可以找到大部分
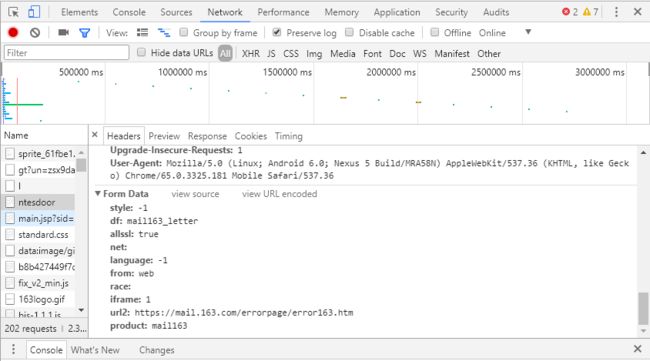
还有一个参数funcid=loginone需要手动加入,然后按照一定格式和顺序添加到Request URL(即https://mail.163.com/entry/cgi/ntesdoor?)后面。补充完整的Request URL即为:
https://mail.163.com/entry/cgi/ntesdoor?style=-1&df=mail163_letter&net=&language=-1&from=web&race=&iframe=1&product=mail163&funcid=loginone&passtype=1&allssl=true&url2=https://mail.163.com/errorpage/error163.htm
后面测试的时候发现其实用原博客的Request URL也行,其实就是一个申请登陆的URL,都是通用的。
关键不同的地方在于sid码。这个时候我们可以发现浏览器的地址栏有一串sid:
https://mail.163.com/js6/main.jsp?sid=RCpjHzssdhVZZaJhQVssftGmNRcBfOlZ&df=mail163_letter
这个sid码是进入收件箱的关键,而每次登陆后的sid码是不同的,因此我们需要得到它。
如何得到sid码呢?
我们先回到ntesdoor日志中,进入response选项,里面是我们浏览器现在的URL,其中就有我们需要的sid码,因此我们需要得到response的内容并将sid码提取出来。
得到sid码之后呢,如何进入收件箱呢?
接下来在浏览器中点击收件箱,选择最后一个出现的日志,右边会出现Request URL。如下图

这就是收件箱的URL了,事实上,我们只需要前面一部分就够了,因为后面的sid会被我们提取的sid替换掉,从而进入我们自己的收件箱。
sid就像是一个验证码,只有在登录成功的URL中得到sid码,才能得到相应的收件箱的URL并利用cookie中缓存的信息进入相应的收件箱,这是一一对应的。
点击response可以看到服务器回应的就是我们收件箱中的邮件信息了。
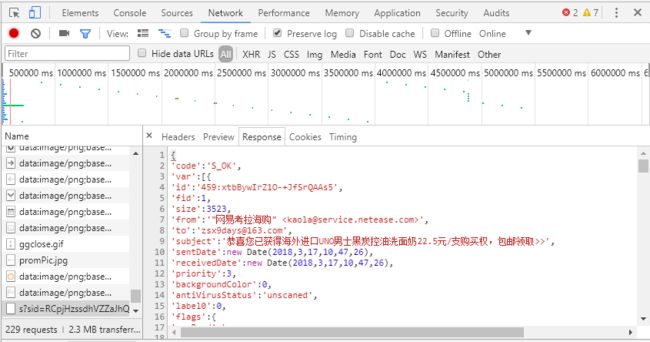
接下来获取response中的信息并提取需要的出来即可。
下面附上完整代码
# -*- coding:utf-8 -*- import urllib.request import re import http.cookiejar import urllib.parse #163邮箱类 class MAIL: #初始化 def __init__(self): #获取登录请求的网址,这个是通用的,只是一个请求登陆的URL self.loginUrl = "https://mail.163.com/entry/cgi/ntesdoor?style=-1&df=mail163_letter&net=&language=-1&from=web&race=&iframe=1&product=mail163&funcid=loginone&passtype=1&allssl=true&url2=https://mail.163.com/errorpage/error163.htm" #设置代理,以防止本地IP被封 self.proxyUrl = "http://202.106.16.36:3128" #初始化sid码 self.sid = "" #第一次登陆所需要的请求头request headers,这些信息可以在ntesdoor日志request header中找到,copy过来就行 self.loginHeaders = { 'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,,image/webp,image/apng,*/*;q=0.8", 'Accept-Language': "zh-CN,zh;q=0.9", 'Connection': "keep-alive", 'Host': "mail.163.com", 'Referer': "http://mail.163.com/", 'User-Agent':"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Mobile Safari/537.36" } #设置用户名和密码,填上自己的即可 self.username = '****' self.pwd = '****' #post所包含的参数 self.post = { 'savelogin':"0", 'url2':"http://mail.163.com/errorpage/error163.htm", 'username':self.username, 'password':self.pwd } #对post编码转换 self.postData = urllib.parse.urlencode(self.post).encode('utf8') # 使用http.cookiejar.CookieJar()创建CookieJar对象 self.cjar = http.cookiejar.CookieJar() # 使用HTTPCookieProcessor创建cookie处理器,并以其为参数构建opener对象 self.cookie = urllib.request.HTTPCookieProcessor(self.cjar) self.opener = urllib.request.build_opener(self.cookie) # 将opener安装为全局 urllib.request.install_opener(self.opener) #模拟登陆并获取sid码 def loginPage(self): try: #发出一个请求 self.request = urllib.request.Request(self.loginUrl,self.postData,self.loginHeaders) except urllib.error.HTTPError as e: print(e.code) print(e.read().decode("utf8")) #得到响应 self.response = urllib.request.urlopen(self.request) #需要将响应中的内容用read读取出来获得网页代码,网页编码为utf-8 self.content = self.response.read().decode("utf8") #打印获得的网页代码 print (self.content) # 设定提取sid码的正则表达式 self.sidpattern = re.compile('sid=(.*?)&', re.S) self.result = re.search(self.sidpattern, self.content) self.sid = self.result.group(1) print (self.sid) #通过sid码获得邮箱收件箱信息 def messageList(self): #重定向至收件箱的网址 listUrl = 'http://mail.163.com/js6/s?sid=%s&func=mbox:listMessages&TopTabReaderShow=1&TopTabLofterShow=1&welcome_welcomemodule_mailrecom_click=1&LeftNavfolder1Click=1&mbox_folder_enter=1'%self.sid #新的请求头 Headers = { 'Accept': "text/javascript", 'Accept-Language': "zh-CN,zh;q=0.9", 'Connection': "keep-alive", 'Host': "mail.163.com", 'Referer': "https://mail.163.com/js6/main.jsp?sid=%suCFJZNnnRnInrsigqunnSrQXsvMMqctH&df=mail163_letter"%self.sid, 'User-Agent':"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Mobile Safari/537.36" } #发出请求并获得响应 request = urllib.request.Request(listUrl, headers = Headers) response = self.opener.open(request) #提取响应的页面内容,里面是收件箱的信息 content = response.read().decode('utf-8') print('~~~') return content #获取邮件信息 def getmail(self): messages = self.messageList() pattern = re.compile('from..(.*?),.*?to..(.*?),.*?subject..(.*?),.*?sentDate..(.*?),\n.*?receivedDate..(.*?),\n',re.S) mails = re.findall(pattern, messages) for mail in mails: print ('-'*50) print ('发件人:',mail[0],'主题:',mail[2],'发送时间:',mail[3]) print ('收件人:',mail[1],u'接收时间:',mail[4]) #创建163邮箱爬虫类 mail = MAIL() mail.loginPage() mail.getmail()
结果示例如下
~~~
--------------------------------------------------
发件人: '"网易邮件中心"
收件人: '"[email protected]"