最新的今日头条美图爬取(这真是一篇很烂的博客)
接下来我们就介绍一下对今日头条的爬取:
对AJAX的爬取我也不是太熟,但是我想了以下这应该是最新的了,我也在网上搜索到不少今日头条的爬去,但是跟新过后就很难找到能顺利爬取美图的博客了,所以我把我的发现写上来,希望能帮助到像我一样的人。
话不多说,上干货了:
打开今日头条网页,打开图集然后F12,点击XHR然后刷新页面就能看到下面的内容了。
首先分析页面: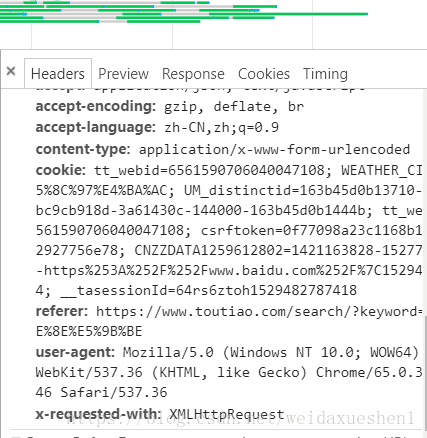
由于请求类型为
x-requested-with:
XMLHttpRequest
分析为AJAX爬取
以上为一些参数;
分析网页过后发现是可以用一个简单的get方法获取的:
本次要用到的是requests库,json库,re库:
对美图页面进行请求首先构造参数,并将url生成新的url然后用try—except进行排错,返回一个html.text:
import requests
import re
from urllib.parse import urlencode
import json
import
def get_url(offset):##获取一页美图
params = {'offset': offset ,
'format': 'json' ,
'autoload': 'true' ,
'keyword': '街拍' ,
'count': '20' ,
'cur_tab': '3' ,
'from': 'gallery'}
url="https://www.toutiao.com/search_content/?"+urlencode(params)
response=requests.get(url)
return response.text
然后对html.text进行一个解析生成对每一个图集访问的url,里面用到一些正则的非贪婪匹配,这个很重要,也困扰了我:
def get_data(html):##获取一页的data数据并提取出美图页面的URL
try:
print(html)
html = json.loads (html)
print(type(html))
datas = html.get ('data')
s=[data.get('share_url') for data in datas]
if s:
return s
else:
print("请求data失败")
except:
print("请求失败")
def get_newurl(url):##生成一个新的url
demo=re.compile('group/(.*?)/',re.S)
demos=demo.search(url)
url="https://www.toutiao.com/a"+demos.group(1)+"/"
print(url)
return url
然后分析详情页,打开F12然后找到源码,发现每一个图集的子链接都在源码所存储的一个经过脚本语言生成的字符串里,然后提取字符串,对字符串进行一系列解析,其中用的正则,和json.loads()方法:
def pase_url(url):##对url进行请求,并提取出字符串,然后解析字符串,然后提取图片的url
try:
response=requests.get(url)
response.encoding=response.apparent_encoding
demo = re.compile ('gallery: JSON.parse\("(.*?)"\)' , re.S)
demos = demo.search (response.text)
print (demos.group(1))
iteam=demos.group(1)
print(type(iteam))
s=json.loads(json.loads('"'+iteam+'"'))
print(type(s))
print(s.get('sub_images'))
for imsges in s.get('sub_images'):
ss=imsges.get('url')
print(ss)
return iteam
except:
print("请求详情页错误")
然后用写一个主函数,遍历所有的url然后写入文件就可以成功保存下来了,以下的东西是刚赶的,很粗糙,希望读者能自己完善:
def save_images(url):
s=requests.get(url)
with open('meitu','wb') as f:
f.write(s.content)
f.close()
def main():
html=get_url(0)
urllist=get_data(html)
for url in urllist:
url=get_newurl(url)
save_images(url)
lxml=pase_url(url)
main()
这样我们的头条爬取就成功了
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
最后我要说明一下,我也是菜鸟,我上面写的东西大概也就能算个半成品,也希望大家多多提问!不过也是我花心思取亲自做的,自己摸索的,当然页面的分析还是在书上学的!
----------------------------------------------------------------------------------------------------------------------------------还有,今日头条的爬取我遇到的困难我一一列出来:
一:
在用正则提取字符串的时候我花了很多时间,当然也不算是很多,因为我一遇到困难就先放下玩游戏去了。
也就是这一部分内容:
demo = re.compile ('gallery: JSON.parse\("(.*?)"\)' , re.S)
demos = demo.search (response.text)demo=re.compile('group/(.*?)/',re.S)
demos=demo.search(url)因为正则的贪婪匹配和非贪婪匹配困扰了我很久这个正则的点睛之笔在转义符上面,需要深入了解一下。
二:
就是url的生成,这个我只用了一点时间就想出来了,其实也不算是什么困难,就是提取出来的url不能用要生成用新的url,这个其实也蛮重要的,就是提醒以下读者,立体的思维
三:
就是从正则表达式中提取出来的字符串还需要解析再解析,然后还原,这个困扰了我,在我玩累了之后偶然发现这样的一篇博客用这样的方法解决了问题
s=json.loads(json.loads('"'+iteam+'"'))这个真的太重要了!
基本上就这么多,其余的报错系统我就不写了,半成品让我们自己去摸索了,啊哈哈哈哈。(其实是我太懒了。。。)
注意:
以上还附有我的测试代码,像parse_url()中的好多print()是为了让我看到实例的代码,其实没什么作用,最后,等我玩累了我应该会写一个完整的,像样的代码到博客上来把!哈哈,就这样吧,欢迎交流!
完整的单页爬取我已经补足在这下面自取:
https://blog.csdn.net/weidaxueshen1/article/details/80758939