爱奇艺微服务监控的探索与实践
作为一线程序猿,是否有过类似经历?新接手一个系统,各接口入口流量是多少,又是哪些业务方在调用?系统大量异常报警,如何快速锁定影响范围,恢复故障并定位问题?接口调用超时,究竟是客户端问题还是服务端响应慢,还是网络波动来背锅?
监控的重要性不言而喻,可是接入监控的额外工作又让人望而却步?每天编写代码之余,又要花多少时间定位线上问题?自己负责的系统故障,是否要等调用方反馈才知道?本文分享爱奇艺有关微服务监控的实践和思考。
如文章《爱奇艺视频后台从"单兵作战"到"团队协作"的微服务实践》 所述,2018年爱奇艺信息流技术团队基于Spring Cloud和公司服务云组件,实现了业务系统的全面微服务化。微服务的拆分,一方面提升了服务负责人的ownership,助力业务快速迭代。另一方面,随着微服务的增加,监控成本随之增加,构建简单有效的微服务监控体系的诉求愈发强烈。本文从以下3个方面展开介绍。
• 背景&初探:介绍建设微服务监控体系的背景,微服务监控体系建设初期的探索和尝试。
• 演进&实践:基于早期微服务监控探索和思考,落地微服务微服务监控体系的具体实践。
• 总结&展望:总结微服务监控建设过程中的实践和思考,以及工作规划。
背景&初探
经过一年多的野蛮生长,信息流团队微服务发展快速,人均负责5个微服务以上,为了全面了解每个微服务运行情况,第一时间感知微服务异常,快速定位线上问题,提高运维效率,微服务建设初期我们尝试了多种监控方案。
这个阶段,我们对微服务监控缺少系统的理论认知和实践经验,所以更多是对已有的监控基础设施和框架低成本的整合和适配。
下面分别从日志监控,Hystrix监控,Actuator监控,拨测监控5个方面介绍。
日志监控
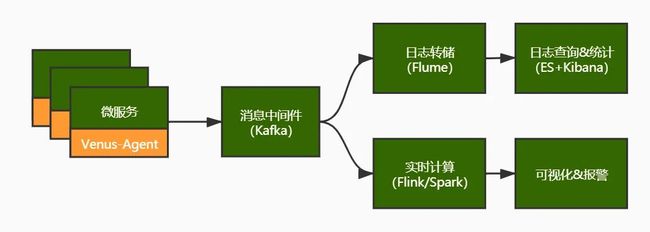
基于日志的监控方案,原理如下图,业界技术方案成熟(例ELK),公司也提供了通用解决方案(Venus),容易落地。缺点是,日志监控链路较长,延迟时间大,报警可能不够及时。
Hystrix监控
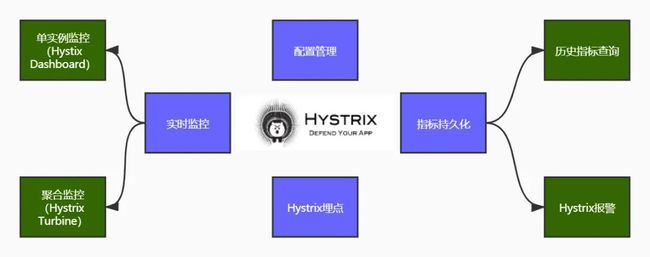
很长一段时间Hystrix是服务熔断降级监控的代名词,Spring Cloud应用中使用hystrix极致易用,从低成本埋点,到配置动态调整,再到原生的可视化Dashboard,使用成本都很低。缺点是,指标数据原生没有持久化,二次开发有一定成本。
下图描述基于Hystrix监控的方案。
Actuator 监控
Actuator端点是Spring Boot应用开发者的最大福利之一,可以零成本了解单实例运行情况。缺点是,同服务多实例指标聚合,指标持久化,指标时序可视化,都需要二次开发。下图描述Actuator端点监控的方案。

拨测监控
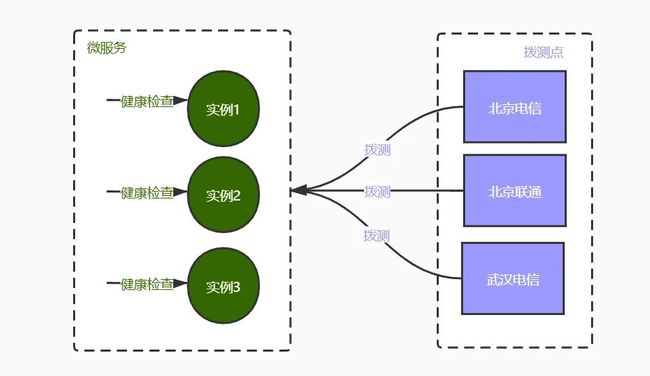
对于面向用户的服务,用户所处网络,地域差异性很大,应用本身可用不代表用户可以正常使用服务,这就需要从用户角度,对服务可用性进行定时拨测。
下图描述拨测监控的方案,主要包括微服务实例自发的健康检查和各拨测点定时拨测。
链路监控
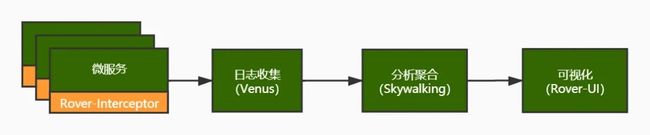
链路监控既可用于调用链路分析,快速定位具体问题,又可用于梳理服务拓扑结构和依赖合理性,是微服务监控必不可少的一环。
我们使用公司服务云提供的日志收集组件Venus(如前所述)和链路跟踪组件Rover(基于Skywalking+Brave)实现该功能。实现方案如下图所示。
其中,接入固定成本表示为引入相应监控而产生的一次性固定投入,包括学习调研,二次开发,集成适配等成本。接入边际成本表示每新增一个微服务或一个监控指标,新产生的开发配置成本。几种监控方案对比和适用场景如下表所示。
| 监控类型 | 接入固 定成本 |
接入边 际成本 |
时效性 | 持久化 可追溯 |
适用场景 |
| 日志监控 | 极低, 基于现有日志收集系统 |
中,日志埋点、解析有一定成本 | 秒级,链路长,有时延迟较大 | 日志持久化,可查看历史 | 时效性要求不高的监控;具体问题排查 |
Hystrix 监控 |
低, 需要部署Hystrix Dashboard |
低,简单配置 | 秒级 | 需二次开发 | 依赖接口实时监控;熔断降级 |
Actuator 监控 |
低,需要部署Spring Boot Admin | 无,应用内置 | 秒级 | 需二次开发 | 单实例指标查看 |
| 拨测监控 | 无,基于公司云拨测服务 | 低,简单配置 | 分钟级,取决于拨测间隔 | 有报警历史 | 面向用户服务可用性定时拨测 |
| 链路监控 | 中,需要适配各种中间件 | 低,简单配置 | 秒级,依赖日志流 | 可以 | 跨系统调用链路分析 |
演进&实践
如上所述,我们在微服务监控建设初期尝试了多种监控方案,实现了不同场景下的监控需求,也遇到了新的问题。概括起来,有以下几个:
• 缺少对监控项的统一认知和定义
• 重复性埋点配置工作,监控成本高
• 各种监控方案简单组合,可视化分散,报警不统一
• 日志监控,报警时效性无保障
比如,每新增一个监控指标,需要把接入,埋点,可视化,报警,从头来一遍,随着微服务和指标增加,这种重复性工作严重制约了监控体系的推广落地。特别是metrics监控,指标繁杂,维度多变,应用广泛。
为此,建设一套监控模型统一,接入成本低,可视化集中管理,报警时效性高,监控指标全面的微服务监控体系势在必行。下面着重介绍信息流监控系统针对metrics监控的实践。
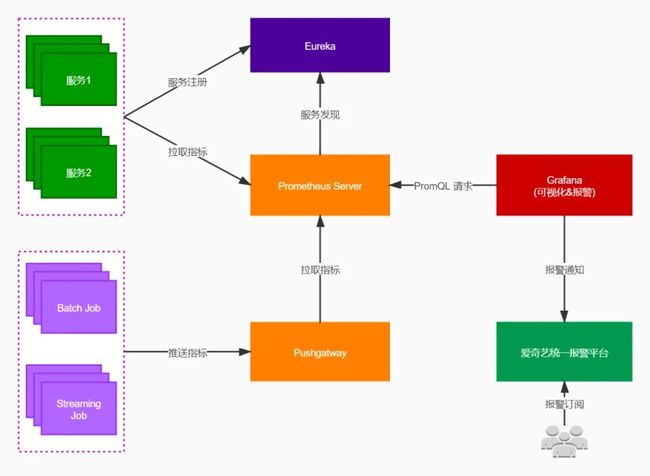
信息流Metrics监控在Prometheus基础上,以构建简单易用的监控系统为目标,对Spring Cloud框架进行适配整合和定制开发。整体结构如上图,我们主要做了以下工作。
监控模型
监控指标是监控系统的基本对象,监控哪些指标,如何定义描述这些指标,是首要解决的问题。我们通过引入指标-维度-数值多维度数据模型,对常用监控指标和维度进行梳理和定义,形成对监控对象的统一描述和共识,为后续实现维度灵活聚合、定义统一的可视化模板和报警模板奠定基础。
通用指标定义:
| 指标 | 说明 |
| QPS | 系统每秒处理业务请求量,反应系统的容量 |
| TP指标 | TP99、TP95、MEAN等,反应的是系统的时效性 |
| 错误量 | http错误响应码的次数,方法调用异常次数等,反应系统的错误面 |
| 资源使用率 | CPU利用率、内存利用率、磁盘利用率等,反应系统资源利用面 |
通用维度定义:
| 维度 | 说明 |
| service_name | 服务名,例:Order |
| dc | 机房,例:bjdx |
| instance | 服务实例,例:1.1.1.1:2222 |
| url | 接口API,例:/order/list |
| method | 方法签名 |
| status | http 响应码 |
定制扩展
自动接入&埋点
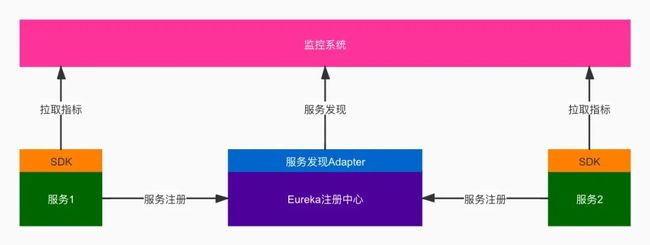
前期我们尝试了多种监控方案,发现能够顺利推广落地的,都有一个共同点,就是服务接入监控的成本很低。最好是不要求应用做任何改动,就可以自动接入,享受监控系统带来的便利。为此我们做了以下工作:
• 每个服务引入sdk自动完成通用指标(Http请求,JVM指标等)采集,并暴露指标拉取端点
• 每个服务自动注册到Eureka注册中心
• Eureka增加Adapter,提供监控系统可识别的接口方法
• 监控系统从注册中心,自动发现要监控的服务实例列表
• 监控系统定期从服务指标端点拉取监控数据
声明式方法监控
很多情况下,需要对某些业务方法耗时进行监控,传统的埋点方式是在方法入口和出口添加监控代码,业务代码侵入高,开发成本高。

PUSH模式扩展
如前所述,Prometheus是用PULL模式获取应用埋点数据,但是有的场景下PULL模式并不适用(比如短生命周期的任务),因此我们基于Prometheus提供的Pushgateway组件,实现PUSH模式获取监控埋点数据。
一种应用场景是,实时收集各个服务日志流中的异常信息。我们监听日志采集的Kafka消息,Flink实时解析出服务异常名称,将各个服务产生的异常实时推送到监控系统,并在Grafana上集中展示。基于Pushgateway的异常监控方案及效果图如下。

集中可视化
不同的监控系统,往往会提供不同的可视化方案。分散的可视化,不利于监控数据的集中展示和全局问题分析。我们使用Grafana实现所有微服务,所有指标的集中可视化。
每个微服务使用统一的监控模板,集中展示各服务入口流量、内部方法、JVM等相关指标。Dashboard模板主要包含以下模块:
• 维度筛选模块
![]()
• JVM和系统指标模块

• 入口流量机房分布&状态码&QPS&响应延时模块
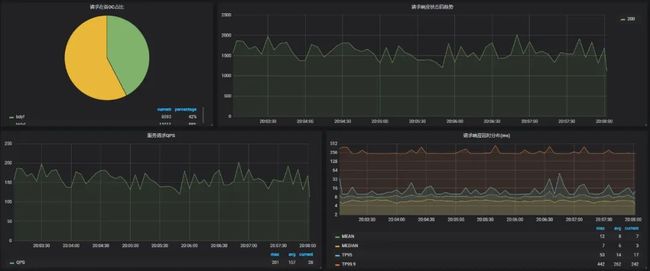
• 方法监控指标模块

统一报警
基于前边定义的通用指标和维度,对所有指标配置默认的报警规则,同时支持自定义报警规则和阈值。基于Grafana Web hook将报警通知发送给Alert Manager,Alert Manager对报警进行相同合并、重复过滤、并格式化为统一报警模板后,投递到爱奇艺统一报警平台,业务owner通过统一报警平台完成报警订阅。统一报警方案及报警样例如下图。

以上所述,爱奇艺信息流监控整体方案总结如下。

自下至上包括4层:
监控对象既包括常驻进程微服务,也包括短生命周期的非常驻进程。
指标获取方式既可以基于Prometheus实时拉取,也可以基于Venus日志收集,前者用于指标实时获取,保证监控报警时效性,后者记录详细日志,用于具体问题排查和链路分析。
监控维度从4个维度监控应用:
Metrics监控宏观上检测系统QPS,响应耗时,错误率和资源利用率;
拨测监控从用户角度监控服务可用性;
链路监控提供单个请求完整生命周期的跟踪路径,专门应对微服务架构带来的分布式调用复杂性;
日志查询提供应用监控最精细化的信息,用于具体问题排障。
集中管理,集中可视化和统一报警管理,在最上面一层,便于排查问题时全面快速获取应用所有监控报警信息。另外,微服务监控的统一认知和必要的流程规范,贯穿监控系统落地始终。
监控系统落地1年多,新增服务基本实现零成本100%接入自动埋点、集中可视化和统一报警,业务owner不需要为接入监控做额外工作,就可以享受监控带来的各种便利;系统异常发生后,可以做到秒级收到报警,借助微服务监控大盘,配合链路监控和日志查询,分钟级确认异常影响范围并定位问题,大大减少故障恢复时间,提升运维效率;目前该方案也在多个其他团队推广落地。
总结&规划
本文介绍了爱奇艺信息流团队微服务监控的探索和实践,涵盖了日志监控,Hystrix监控,拨测监控,链路监控,Prometheus监控等,从最初的多种监控方案兼容并包,到基于多维度数据模型和集中可视化的定制开发。不能简单说,后面的监控方案比前期的好,而是在微服务监控不同发展阶段,监控体系建设投入和收益的折中选择。下面是微服务监控探索过程中一些心得。
简单有效。简单有效是评测监控系统好坏的最高准则,埋点是否简单甚至可省去,是否存在重复性的配置工作,都会影响监控方案能否最终落地推广。好的监控方案一定是,没有故障时,开发人员无感知,出现故障时,想看的指标都能拿到。
集成定制。业界和公司提供了固定场景下的监控框架和方案,基于这些成熟的方案和基础设施,会大大减少监控系统建设投入;另一方面,必要的定制开发封装,会进一步推动自动化监控落地。
集中管理。考虑监控指标的多样性(系统,应用,业务等),不同监控方案关注点不同,指标埋点,收集,获取未必仅用一套,但是可视化应该尽可能集中,方便统一管理和全局分析。
流程规范。微服务监控不是一个人或少数几个人的事,也不应该微服务上线后才被关注,它需要每位微服务owner,从编码,甚至设计阶段,就要考虑监控指标和维度。为了减少监控带来的额外负担,保障落地效果,必要的流程规范和分享培训是必要的。
以上是监控实践的阶段性探索实践总结,未来还有很多方面需要持续的优化和改进,例如灵活的报警规则,恰如其分的报警,更低成本的埋点、可视化,服务质量评测报告等。另外,依托大数据分析和人工智能能力,系统异常检测,根因分析,智能合并,故障预测和自恢复技术愈发成熟,推动AI赋能数字化运维落地也是我们努力的方向。

也许你还想看
一站式入口服务|爱奇艺微服务平台 API 网关实战
爱奇艺号微前端架构实践

扫一扫下方二维码,更多精彩内容陪伴你!
