爬虫简介与基本语法
一、爬虫用来做什么的?
从互联网上提取数据的一组程序
1、什么是爬虫?
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
那么在大数据世代,我们的数据从哪里来呢
2、数据获取途径
途径1:企业产生的用户数据:
百度指数:index.baidu.com
阿里指数: alizs.taobao,com
TBI: tbi.tencent.com
新浪微博指数:data.weibo.com
途径2:数据平台购买数据
数据堂:datatang.com
国运数据市场:moojnn.com/data-market/
贵阳大数据交易所:trade.gbdex.com
途径3:政府/机构公开数据
国家统计局:
世界银行
联合国
纳斯达克
途径4:数据管理咨询公司
麦肯锡 mcjinsey.com
埃森哲
艾瑞咨询
途径5:爬取网络数据:
如果需要的数据市场上没有,或者不愿意购买,可以选择做一名爬虫工程师,自己动手爬取数据。
3、爬虫需要涉及知识:
- python基础语法
- Html页面的内容抓取
- Html页面中进行数据抓取
- Scrapy框架
- 爬虫与反爬虫,反反爬虫之间的争斗
4、通用爬虫与聚焦爬虫
根据使用场景:网络爬虫可分为通用爬虫与聚焦爬虫
通用网络爬虫 是 捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于:聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
二、爬虫基本语法:
1 、 导入request模块
首先需要用到 python中的requests
import requests
2、构建网络接口
name = input('请输入要爬取的贴吧名称')
url = 'http://tieba.baidu.com/f?kw='+name如果接口处是汉字需要注意在接口处的转码问题
有时候,接口地址可以直接使用拼接url的方法,如果是汉字的情况下无法直接拼接,此法不能直接使用,所以我们引入了字典作为请求参数
例如:para_dic = { 'kw':'还珠格格', 'pn':0 }
para_dic = { 'kw':'还珠格格', 'pn':0 }
url = 'http://tieba.baidu.com/f?'
response = requests.get(url,params=para_dic)3、网络访问
分为get和post方法
安全性:get:参数会拼接在url地址当中, post:参数会封装到一个表单当中,安全性较高 #
数据传输的量的大小 : get:数据量较小 post:大的数据需要post
response = requests.get(url)
response = requests.post(url)4、获取文本信息
text :只显示字符类文本信息,无法显示图片,视频等非字符类信息
content:用来获取非字符类型的数据,;如图片,音频,视频等 # 访问资源不一定是文字信息,例如访问图片
text = response.text
text = response.content.decode('utf-8') #需要指明解码类型如果返回的数据类型是json字符串类型,上述方法无法获取
需要用到json()方法
text = response.json()
5、保存数据到本地
file_name = name+'.html' # 建立文件名
with open(file_name,'w',encoding='utf-8') as fp: # 在该目录下执行写操作,创建对应名的文件
fp.write(response.text) 6、案例
案例1:爬取百度贴吧的搜索内容
import requests
name = input('请输入要爬取的贴吧名称')
url = 'http://tieba.baidu.com/f?kw='+name
print(url)
# 网络访问
response = requests.get(url)
# 获取文本信息
print(response.text)
# 保存数据
file_name = name+'.html'
with open(file_name,'w',encoding='utf-8') as fp:
fp.write(response.text)
案例2:爬取百度贴吧对应页码的内容,并保存在当前目录的新建的文件夹下
如果要抓取前5页的数据,需要在接口写出对应的搜索词语与对应的页码
import requests
import os
name = input('请输入要爬取的网站名称:')
if os.path.exists(name):
os.chdir(name)
else:
os.mkdir(name)
os.chdir(name)
for i in range(1,6):
pn = (i-1)*50
parc_dic = {
'kw':name,
'pn':(i-1)*50
}
url = 'http://tieba.baidu.com/f?'
response = requests.get(url,params=parc_dic)
file_name = '第%d页.html'%(i)
with open(file_name,'w',encoding='utf-8') as fp:
fp.write(response.text)案例3:通过百度翻译特定词爬取对应的翻译结果
# 案例:百度翻译
import requests
# 接口地址
keyword = input('请输入要翻译的单词:')
url= 'https://fanyi.baidu.com/sug'
# 参数
parm_dic = {
'kw':keyword
}
# 网络请求
response = requests.post(url,data=parm_dic)
# json字符串
# 如果是json数据可以通过该方法获取到信息
text = response.json()
print(text)
data = text['data']
for item in data:
print(item['k'],':',item['v'])
运行结果;
C:\Users\Administrator\AppData\Local\Programs\Python\Python36\python.exe E:/Project/爬虫阶段/day03-25/04-post请求.py
请输入要翻译的单词:like
{'errno': 0, 'data': [{'k': 'like', 'v': 'vt. 喜欢; (与 would 或 should 连用表示客气)想; 想要; 喜欢做; prep.'}, {'k': 'likely', 'v': 'adj. 可能的; 适合的; 有希望的; adv. 可能; 或许; 大概; 多半;'}, {'k': 'likewise', 'v': 'adv. 同样地; 也,而且;'}, {'k': 'likes', 'v': 'n. 爱好,喜欢的东西; v. 喜欢( like的第三人称单数 ); (与 would 或 shou'}, {'k': 'likelihood', 'v': 'n. 可能,可能性; [数]似然,似真;'}]}
like : vt. 喜欢; (与 would 或 should 连用表示客气)想; 想要; 喜欢做; prep.
likely : adj. 可能的; 适合的; 有希望的; adv. 可能; 或许; 大概; 多半;
likewise : adv. 同样地; 也,而且;
likes : n. 爱好,喜欢的东西; v. 喜欢( like的第三人称单数 ); (与 would 或 shou
likelihood : n. 可能,可能性; [数]似然,似真;
Process finished with exit code 0
案例4:使用爬虫登录指定页面并获取该页面内容
import requests
login_url = 'http://www.renren.com/PLogin.do'
parm_dic = {
'email':'对应的邮箱',
'password':'对应密码'
}
response = requests.post(url = login_url,data=parm_dic)
with open('login_result.html','w',encoding='utf-8') as fp:
fp.write(response.text)再次进行登录爬虫:
尽管我们已经在第一次的response中进行了登录操作,当我们在response2中再次 # 访问的时候,由于http的无状态性,导致了两次之间没有产生关联,以至于第二次没有拿到 # 我们想要的数据
response2 =requests.get('http://www.renren.com/970549775')
with open('index_result.html','w',encoding='utf-8') as fp:
fp.write(response2.text)此次登录将不会成功
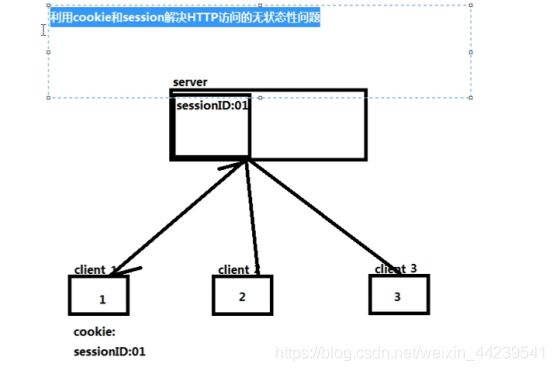
7、解决http的无状态性问题的方法;
一、使用浏览器的cookie
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Cookie': 'anonymid=juwajjf8-uu5j2w; depovince=JL; jebecookies=d5802912-c408-4cc1-b19d-6e09cc495781|||||; _r01_=1; JSESSIONID=abc2Gubm1PRp6b7hvrtPw; ick_login=42b83c79-34c7-4636-96c4-c7a7d1a9099b; _de=9238B3813359A30973ACD3C06372F715; p=f4df902734c3ddf727d49957240d092e5; first_login_flag=1; ln_uact=15290419130; ln_hurl=http://head.xiaonei.com/photos/0/0/men_main.gif; t=bdd1cbb75d97c51ae7f9214edd0f5a5a5; societyguester=bdd1cbb75d97c51ae7f9214edd0f5a5a5; id=970549775; ver=7.0; jebe_key=d975b327-171d-4bf4-bdcb-9304ceed27fd%7Cd435b4d4dce7db0b54ca4d1603b6ef68%7C1556175232674%7C1%7C1556175259457; xnsid=acb3f071; loginfrom=null; wp_fold=0; XNESSESSIONID=d383dc158c76',
'Host': 'www.renren.com',
'Referer': 'http://www.renren.com/970549775/profile?v=info_timeline',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'
}
response = requests.get(url='http://www.renren.com/970549775/profile',headers=headers)
print(response.text)
with open('cookie.html','w',encoding='utf-8') as fp:
fp.write(response.text)但是此种方法较为繁琐
那么我们可以直接使用服务器中生成的sessionid来进行验证登录,解决无状态问题
二、使用session解决http无状态问题
import requests
login_url = 'http://www.renren.com/PLogin.do'
parm_dic = {
'email':'对应邮箱',
'password':'对应密码'
}
# 利用session解决两次访问的关联问题
session = requests.Session()
# 登录
response = session.post(url=login_url,data=parm_dic)
# 访问主页
response2 = session.get(url='http://www.renren.com/970549775/profile')
with open('session.html','w',encoding='utf-8') as e:
e.write(response2.text)8、代理ip
代理服务器英文全称是Proxy Server,其功能就是代理网络用户去取得网络信息。形象的说:它是网络信息的中转站。
代理:有一件事自己不直接做,让别人代替你做
Client ——》 代理服务器 ——》 server
案例:通过代理ip访问百度
import requests
# 根据协议类型,选择不同的代理
proxies = {
'http':'http://183.148.131.184:9999',
# 'https':
}
# 三个方法:
# get()和post()两个方法是基request方法实现的
# requests.request()
# requests.get()
# requests.post()
# requests.get('http://www.baidu.com')
# 等价于 requests.request(get,'http://www.baidu.com')
# 使用代理
response = requests.request('get','https://www.baidu.com',proxies = proxies)
print(response.text)9、验证登录
如果在访问https的url时,有可能出现证书校验失败,不能访问网站数据的情况, 这个时候,写出 verify = False,意思是不进行验证
import requests
response = requests.request('get','https://sls.cdb.com.cn/')运行结果:
会直接报错:
其中会提示如下错误:
ssl.SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:833)解决方法:
import requests
response = requests.request('get','https://sls.cdb.com.cn/',verify = False)运行结果:
会有未经认证警告提示
C:\Users\Administrator\AppData\Local\Programs\Python\Python36\python.exe E:/Project/爬虫阶段/day03-25/08-验证.py
C:\Users\Administrator\AppData\Local\Programs\Python\Python36\lib\site-packages\urllib3\connectionpool.py:847: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecureRequestWarning)
Process finished with exit code 0