CART 分类与回归树
本文结构:
- CART算法有两步
- 回归树的生成
- 分类树的生成
- 剪枝
CART - Classification and Regression Trees
分类与回归树,是二叉树,可以用于分类,也可以用于回归问题,最先由 Breiman 等提出。
分类树的输出是样本的类别, 回归树的输出是一个实数。
CART算法有两步:
决策树生成和剪枝。
决策树生成:递归地构建二叉决策树的过程,基于训练数据集生成决策树,生成的决策树要尽量大;
自上而下从根开始建立节点,在每个节点处要选择一个最好的属性来分裂,使得子节点中的训练集尽量的纯。
不同的算法使用不同的指标来定义”最好”:
分类问题,可以选择GINI,双化或有序双化;
回归问题,可以使用最小二乘偏差(LSD)或最小绝对偏差(LAD)。
决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时损失函数最小作为剪枝的标准。
这里用代价复杂度剪枝 Cost-Complexity Pruning(CCP)
回归树的生成
回归树模型表示为:
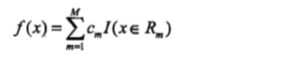
其中,数据空间被划分成了 R1~Rm 单元,每个单元上有一个固定的输出值 cm。
这样就可以计算模型输出值与实际值的误差:
![]()
我们希望每个单元上的 cm,可以使得这个平方误差最小化,易知当 cm 为相应单元上的所有实际值的均值时,可以达到最优:
![]()
那么如何生成这些单元划分?
假设,我们选择变量 xj 为切分变量,它的取值 s 为切分点,那么就会得到两个区域:
![]()
当 j 和 s 固定时,我们要找到两个区域的代表值 c1,c2 使各自区间上的平方差最小,
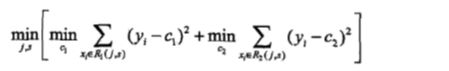
前面已经知道 c1,c2 为区间上的平均,
![]()
那么对固定的 j 只需要找到最优的 s,
然后通过遍历所有的变量,我们可以找到最优的 j,
这样我们就可以得到最优对(j,s),并得到两个区间。
上述过程表示的算法步骤为:

即:
(1)考虑数据集 D 上的所有特征 j,遍历每一个特征下所有可能的取值或者切分点 s,将数据集 D 划分成两部分 D1 和 D2
(2)分别计算上述两个子集的平方误差和,选择最小的平方误差对应的特征与分割点,生成两个子节点。
(3)对上述两个子节点递归调用步骤(1)(2),直到满足停止条件。
分类树的生成
(1)对每个特征 A,对它的所有可能取值 a,将数据集分为 A=a,和 A!=a 两个子集,计算集合 D 的基尼指数:
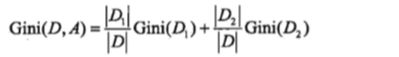
(2)遍历所有的特征 A,计算其所有可能取值 a 的基尼指数,选择 D 的基尼指数最小值对应的特征及切分点作为最优的划分,将数据分为两个子集。
(3)对上述两个子节点递归调用步骤(1)(2), 直到满足停止条件。
(4)生成 CART 决策树。
其中 GINI 指数:
1、是一种不等性度量;
2、是介于 0~1 之间的数,0-完全相等,1-完全不相等;
3、总体内包含的类别越杂乱,GINI指数就越大(跟熵的概念很相似)
定义:
分类问题中,假设有 K 个类,样本属于第 k 类的概率为 pk,则概率分布的基尼指数为:
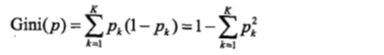
样本集合 D 的基尼指数为:
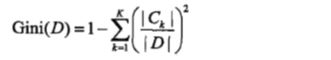
其中 Ck 为数据集 D 中属于第 k 类的样本子集。
如果数据集 D 根据特征 A 在某一取值 a 上进行分割,得到 D1 ,D2 两部分后,那么在特征 A 下集合 D 的基尼指数为:
其中算法的停止条件有:
1、节点中的样本个数小于预定阈值,
2、样本集的Gini系数小于预定阈值(此时样本基本属于同一类),
3、或没有更多特征。
下面来看一下例子:
最后一列是我们要分类的目标。
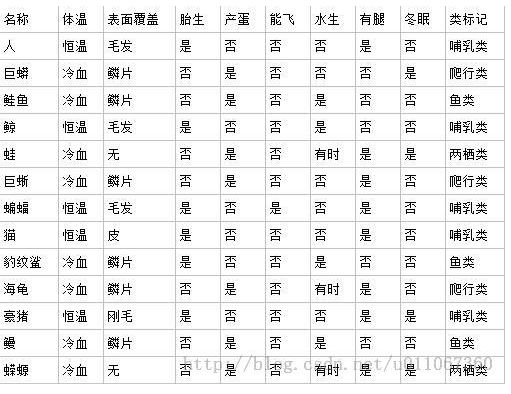
例如,按照“体温为恒温和非恒温”进行划分,计算如下:
恒温时包含哺乳类5个、鸟类2个
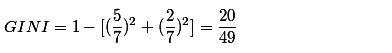
非恒温时包含爬行类3个、鱼类3个、两栖类2个
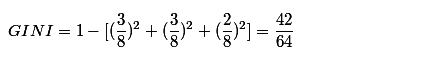
得到特征‘体温’下数据集的GINI指数:
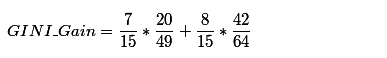
最后我们要选 GINI_Gain 最小的特征和相应的划分。
剪枝
就是在完整的决策树上,剪掉一些子树,使决策树变小。
是为了减少决策树过拟合,如果每个属性都被考虑,那决策树的叶节点所覆盖的训练样本基本都是“纯”的,这时候的决策树对训练集表现很好,但是对测试集的表现就会比较差。
决策树很容易发生过拟合,可以改善的方法有:
1、通过阈值控制终止条件,避免树形结构分支过细。
2、通过对已经形成的决策树进行剪枝来避免过拟合。
3、基于Bootstrap的思想建立随机森林。
这里我们用 代价复杂度剪枝 Cost-Complexity Pruning(CCP) 方法来对 CART 进行剪枝。

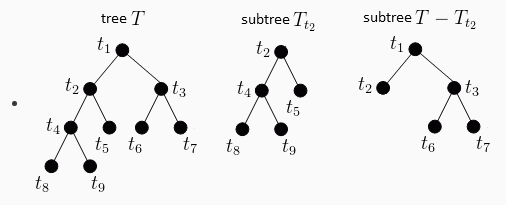
从整个树 T0 开始,先剪去一棵子树,生成子树 T1,
在 T1 上再剪去一棵子树,生成子树 T2,
重复这个操作,直到最后只剩下一个根节点的子树 Tn,
得到了子树序列 T0~Tn,
利用独立的验证数据集,计算每个子树的平方误差或者基尼指数,
选择误差最小的那个子树作为最优的剪枝后的树。
那么这个子树序列是怎么剪出来的?
因为建模的时候,目标就是让损失函数达到最优,那剪枝的时候也用损失函数来评判。
损失函数是什么呢?
对任意子树 T,损失函数如下形式,cost-complexity function:
![]()
其中 CT 为误差(例如基尼指数),|T| 为 T 的叶节点个数,alpha 为非负参数,用来权衡训练数据的拟合程度和模型的复杂度。
alpha 固定时,一定可以找到一个子树 T,使得等式右边达到最小,那么这个 T 就叫做最优子树。
对固定的 alpha 找到损失函数最小的子树 T,二者之间有这样的关系:alpha 大时,T 偏小,alpha 小时,T 偏大。
那如果将 alpha 从小增大设置为一个序列,T 就可以从大到小得到相应的最优子树序列,并且还是嵌套的关系。
剪的时候,哪个树杈是可以被剪掉的呢?
很容易想到的是,如果剪掉后和没剪时的损失函数一样或者差别不大的话,那当然是剪掉好了,只留下一个点,就能代表一个树杈,这样树就被简化了。
以节点 t 为单节点树时,它的损失函数为:(后面剪枝后就可以用一个点来代替一个树杈)
![]()
以节点 t 为根节点的子树 Tt,它的损失函数为:(后面剪枝这个树杈)
![]()
那么接下来的问题就是能不能找到这样的点呢?
上面令 alpha=0,就有 Tt 和 t 的损失函数的关系为:
![]()
那么增大 alpha,当它为如下形式时:
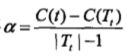
此时,Tt 和 t 的损失函数相等,而 t 的节点少,那么保留 t 就可以了,Tt 就可以剪掉了。
![]()
那么在剪枝算法的第三步时,对每个 t,计算一下 gt,也就是能找到子树 Tt 和 t 的损失函数相等时的 alpha,
每个点 t 都可以找到符合这样条件的 alpha,
遍历所有节点 t 后,找到最小的这个 alpha,
第四步,再把这个 alpha 对应的节点 t 的子树 Tt 剪掉,
并用多数投票表决法决定 t 上的类别,
这样得到的剪枝后的树 T 记为 Tk,
这时的 alpha 记为 alpha k,
经过上面步骤,会得到:
α1⩽α2⩽ … ⩽αk⩽ …
T1⊇T2⊇ … ⊇Tk⊇ … ⊇{root}
例子:
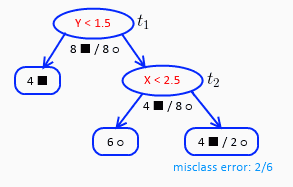
下面这棵树,有三个点 t1≡root,t2,t3
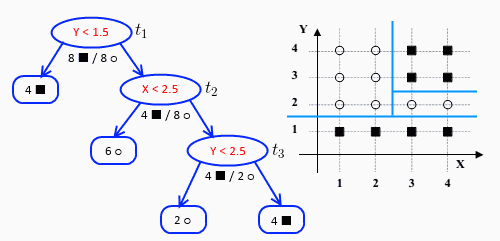
α(1)=0
计算每个点的 gt:

t2,t3 时的 gt 相等,此时我们可以选择剪枝少的点,那就是 t3 剪掉。
并且 α(2)=1/8
这时剩下 t1,t2,再继续计算 gt:
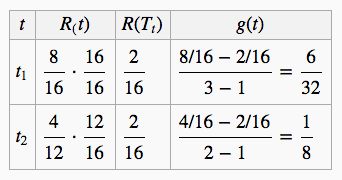
t2 的小,所以剪掉 t2:
并且令 α(3)=1/8
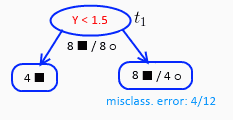
最后剩下 t1,计算后 gt=1/4,所以 α(4)=1/4。
如此我们得到:α(0)=0,α(1)=1/8,α(2)=1/8,α(3)=1/4
并且得到了相应的子树,
接下来就可以利用独立的验证数据集,计算每个子树的平方误差或者基尼指数,
选择误差最小的那个子树作为最优的剪枝后的树。
资料:
统计学习方法
https://wizardforcel.gitbooks.io/dm-algo-top10/content/cart.html
http://blog.csdn.net/baimafujinji/article/details/53269040
http://blog.csdn.net/luoshixian099/article/details/51811945
https://www.zhihu.com/question/22697086
http://mlwiki.org/index.php/Cost-Complexity_Pruning
推荐阅读
历史技术博文链接汇总
也许可以找到你想要的