分页内存管理
文章目录
- 一、分页内存管理详解
- 1、分页内存管理的核心思想
- 2、分页内存管理能解决什么问题?
- 3、虚拟地址的构成与地址翻译
- 4、页表
- 5、分页内存管理的优缺点
- 二、分页内存管理例子解析
- 三、缺页中断和页面置换的目标
- 1、缺页中断
- 2、页面置换的目标
- 四、页面置换算法
- 1、最佳置换算法(OPT)
- 2、最近最久未使用(LRU)
- 3、最近未使用(NRU)
- 4、先进先出(FIFO)
- 5、时钟
一、分页内存管理详解
1、分页内存管理的核心思想
固定分区会产生内部碎片,动态分区会产生外部碎片,这两种技术对内存的利用率都比较低。我们希望内存的使用能尽量避免碎片的产生,这就引入了分页的思想:将虚拟内存空间和物理内存空间皆划分为大小相同的页面,如4KB、8KB或16KB等,并以页面作为内存空间的最小分配单位,一个程序的一个页面可以存放在任意一个物理页面里。
分页的最大作用就在于:使得进程的物理地址空间可以是非连续的。
2、分页内存管理能解决什么问题?
-
解决空间浪费碎片化问题(外部碎片):由于将虚拟内存空间和物理内存空间按照某种规定的大小进行分配,这里我们称之为页(Page),然后按照页进行内存分配,也就克服了外部碎片的问题。
-
解决程序大小受限问题:程序增长有限是因为一个程序需要全部加载到内存才能运行,因此解决的办法就是使得一个程序无须全部加载就可以运行。使用分页也可以解决这个问题,只需将当前需要的页面放在内存里,其他暂时不用的页面放在磁盘上,这样一个程序同时占用内存和磁盘,其增长空间就大大增加了。而且,分页之后,如果一个程序需要更多的空间,给其分配一个新页即可(而无需将程序倒出倒进从而提高空间增长效率)。
3、虚拟地址的构成与地址翻译
【虚拟地址的构成】:
在分页系统下,一个程序发出的虚拟地址由两部分组成:页面号和页内偏移值,如下图所示:

例如,对于32位寻址的系统,如果页面大小为4KB,则页面号占20位,页内偏移值占12位。
【地址翻译:虚拟地址→物理地址】:
分页系统的核心是页面的翻译,即从虚拟页面到物理页面的映射(Mapping)。而这个翻译过程由内存管理单元(MMU)完成,MMU接收CPU发出的虚拟地址,将其翻译为物理地址后发送给内存。内存管理单元按照该物理地址进行相应访问后读出或写入相关数据,如下图所示:
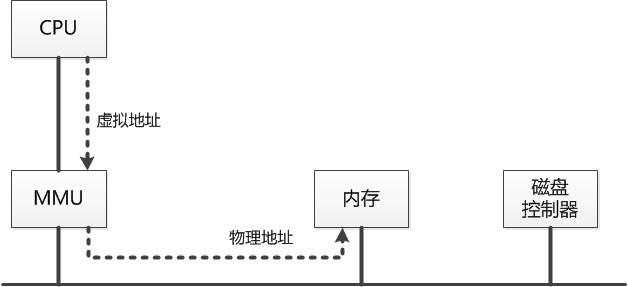
那么,这个翻译是怎么实现的呢?答案是查页表,对于每个程序,内存管理单元MMU都为其保存一个页表,该页表中存放的是虚拟页面到物理页面的映射。每当为一个虚拟页面寻找到一个物理页面之后,就在页表里增加一条记录来保留该映射关系。当然,随着虚拟页面进出物理内存,页表的内容也会不断更新变化。

4、页表
页表的根本功能是提供从虚拟页面到物理页面的映射。因此,页表的记录条数与虚拟页面数相同。此外,内存管理单元依赖于页表来进行一切与页面有关的管理活动,这些活动包括判断某一页面号是否在内存里,页面是否受到保护,页面是否非法空间等等。

页表的存储方式是TLB(Translation look-aside buffer, 转换表缓冲区)+内存。TLB实际上是一组硬件缓冲所关联的快速内存。若没有TLB,操作系统需要两次内存访问来完成逻辑地址到物理地址的转换,访问页表算一次,在页表中查找算一次。TBL中存储页表中的一小部分条目,条目以键值对方式存储。
5、分页内存管理的优缺点
【优点】:
-
分页系统不会产生外部碎片,一个进程占用的内存空间可以不是连续的,并且一个进程的虚拟页面在不需要的时候可以放在磁盘中。
-
分页系统可以共享小的地址,即页面共享。只需要在对应给定页面的页表项里做一个相关的记录即可。
【缺点】:
-
页表很大,占用了大量的内存空间。
-
还是会存在内部碎片。
二、分页内存管理例子解析
把物理内存,按照某种尺寸,进行平均分割。比如我现在以2个内存单位,来分割内存,也就是每两个连续的内存空间,组成一个内存页:
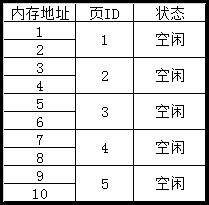
接着,系统同样需要维护一个内存信息表:
现在,程序申请长度为3的内存空间,不过由于现在申请的最小单位为页面,而一个页面的长度为2,因此现在需要申请2个页面,也就是4个内存空间。这就浪费了1个内存空间。接着,程序再申请长度为1,长度为2的空间:
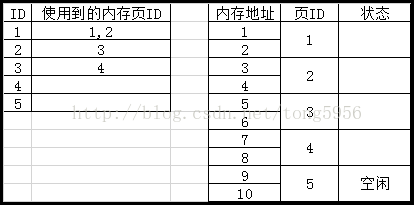
释放掉ID=2,内存页ID为3的那条内存空间信息:
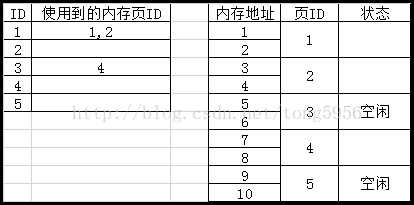
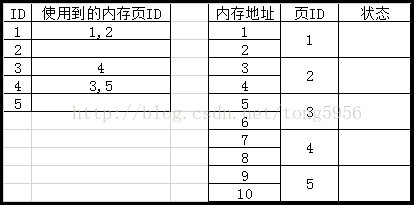
现在,就出现了之前的情况:目前一共有4个内存空间,但是不连续。不过,因为现在是分页管理机制,因此,现在仍然可以继续申请长度为4的内存空间:
三、缺页中断和页面置换的目标
1、缺页中断
在分页系统中,一个虚拟页面既有可能在物理内存,也有可能保存在磁盘上。如果CPU发出的虚拟地址对应的页面不在物理内存,就将产生一个缺页中断,而缺页中断服务程序负责将需要的虚拟页面找到并加载到内存。

2、页面置换的目标
如果发生了缺页中断,就需要从磁盘上将需要的页面调入内存。如果内存没有多余的空间,就需要在现有的页面中选择一个页面进行替换。使用不同的页面置换算法,页面更换的顺序也会各不相同。如果挑选的页面是之后很快又要被访问的页面,那么系统将很开再次产生缺页中断,因为磁盘访问速度远远内存访问速度,缺页中断的代价是非常大的。因此,挑选哪个页面进行置换不是随随便便的事情,而是有要求的。
页面置换时挑选页面的目标主要在于降低随后发生缺页中断的次数或概率(也可以说缺页率最低)。因此,挑选的页面应当是随后相当长时间内不会被访问的页面,最好是再也不会被访问的页面。
四、页面置换算法
1、最佳置换算法(OPT)
所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。是一种理论上的算法,因为无法知道一个页面多长时间不再被访问。
2、最近最久未使用(LRU)
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU 将最近一段时间最久未使用的页面换出。
为了实现 LRU,需要在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的。当发生缺页中断时,删除链表尾部最久没有使用的页面。
因为每次访问都需要更新链表,因此这种方式实现的 LRU 代价很高。
3、最近未使用(NRU)
每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置 M=1。其中 R 位会定时被清零。可以将页面分成以下四类:
- R=0,M=0
- R=0,M=1
- R=1,M=0
- R=1,M=1
当发生缺页中断时,NRU 算法随机地从类编号最小的非空类中挑选一个页面将它换出。
4、先进先出(FIFO)
顾名思义,先进先出(FIFO,First In First Out)算法的核心是更换最早进入内存的页面,其实现机制是使用链表将所有在内存中的页面按照进入时间的早晚链接起来,然后每次置换链表头上的页面就行了,而新加进来的页面则挂在链表的末端,如下图所示:

FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问题,对该算法做一个简单的修改:
当页面被访问 (读或写) 时设置该页面的 R 位为 1。需要替换的时候,检查最老页面的 R 位。如果 R 位是 0,那么这个页面既老又没有被使用,可以立刻置换掉;如果是 1,就将 R 位清 0,并把该页面放到链表的尾端,修改它的装入时间使它就像刚装入的一样,然后继续从链表的头部开始搜索。
5、时钟
时钟算法的核心思想是:将页面排成一个时钟的形状,该时钟有一个指针,每次需要更换页面时,我们从指针所指的页面开始检查。如果当前页面的访问位为0,即从上次检查到这次,该页面没有被访问过,将该页面替换。反之,就将其访问位清零,并顺时针移动指针到下一个页面。重复这些步骤,直到找到一个访问位为0的页面。
例如下图所示的一个时钟,指针指向的页面是F,因此第一个被考虑替换的页面是F。如果页面F的访问位为0,F将被替换。如果F的访问位为1,则F的访问位清零,指针移动到页面G。

参考:https://blog.csdn.net/tong5956/article/details/74937178
https://www.cnblogs.com/edisonchou/p/5094066.html