python 登陆邮箱下载邮件附件
参考帖子:https://blog.csdn.net/u012209894/article/details/82384987
最近有一个比较特殊的需求,有一个业务每日会产生大量报表,该业务并未给出拿取报表数据的接口,每天报表会发送到一个邮箱中以附件发送,但每日的邮件过多,需要自己登陆邮箱一个一个附件下载下来比较繁琐,现在要写个脚本去拿这些附件,然后再分析里面的数据。
def decode_str(self, str_in):
value, charset = decode_header(str_in)[0]
if charset:
value = value.decode(charset)
return value
def get_att(self, msg_in, str_day_in):
# import email
attachment_files = []
for part in msg_in.walk():
# 获取附件名称类型
file_name = part.get_filename()
# contType = part.get_content_type()
if file_name:
h = email.header.Header(file_name)
# 对附件名称进行解码
dh = email.header.decode_header(h)
filename = dh[0][0]
if dh[0][1]:
# 将附件名称可读化
filename = self.decode_str(str(filename, dh[0][1]))
print(filename)
# filename = filename.encode("utf-8")
# 下载附件
data = part.get_payload(decode=True)
# 在指定目录下创建文件,注意二进制文件需要用wb模式打开
att_file = open('E:\\load_bi\\' + str_day_in + '\\' + filename, 'wb')
attachment_files.append(filename)
att_file.write(data) # 保存附件
att_file.close()
return attachment_files
def decode_str(self, s):
value, charset = decode_header(s)[0]
if charset:
if charset != 'utf8':
charset = 'utf8'
value = value.decode(charset)
return value
def get_email_headers(self, msg):
headers = {}
for header in ['From', 'To', 'Cc', 'Subject', 'Date']:
value = msg.get(header, '')
if value:
if header == 'Date':
headers['Date'] = value
if header == 'Subject':
subject = self.decode_str(value)
headers['Subject'] = subject
if header == 'From':
hdr, addr = parseaddr(value)
name = self.decode_str(hdr)
from_addr = u'%s <%s>' % (name, addr)
headers['From'] = from_addr
if header == 'To':
all_cc = value.split(',')
to = []
for x in all_cc:
hdr, addr = parseaddr(x)
name = self.decode_str(hdr)
to_addr = u'%s <%s>' % (name, addr)
to.append(to_addr)
headers['To'] = ','.join(to)
if header == 'Cc':
all_cc = value.split(',')
cc = []
for x in all_cc:
hdr, addr = parseaddr(x)
name = self.decode_str(hdr)
cc_addr = u'%s <%s>' % (name, addr)
cc.append(to_addr)
headers['Cc'] = ','.join(cc)
return headers
def guess_charset(self,msg):
# 先从msg对象获取编码:
charset = msg.get_charset()
if charset is None:
# 如果获取不到,再从Content-Type字段获取:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8:].strip()
return charset
def get_enclosure(self):
# 日期赋值
day = datetime.date.today()
str_day = str(day).replace('-', '')
self._email = "[email protected]"
self._password = "xxxxxx"
# 连接到POP3服务器,带SSL的:
# self._pop_server = "pop.gmail.com"
self._pop_server = "pop.163.com"
telnetlib.Telnet(self._pop_server, 995)
try:
server=poplib.POP3_SSL(self._pop_server)
except:
time.sleep(5)
# server = poplib.POP3(self._pop_server,110,timeout=10)
server=poplib.POP3_SSL(self._pop_server, 995,timeout=10)
# 可以打开或关闭调试信息:
server.set_debuglevel(1)
# POP3服务器的欢迎文字:
print(server.getwelcome())
# 身份认证:
server.user(self._email)
server.pass_(self._password)
# stat()返回邮件数量和占用空间:
msg_count,msg_size=server.stat()
print('message count:',msg_count)
print('message size:',msg_size,'bytes')
resp,mails, octets = server.list()
# 查看邮件长度
index = len(mails)
print "邮件总数:{}".format(index)
for i in range(index, -1, -1):
# lines存储了邮件的原始文本的每一行,
resp, lines, octets = server.retr(i)
# 邮件的原始文本:
# msg_content = b'\r\n'.join(lines)
msg_content = '\n'.join(lines)
# 解析邮件:
msg = Parser().parsestr(msg_content)
headers = self.get_email_headers(msg)
# 获取邮件时间,格式化收件时间
# 邮件时间格式转换
# date2 = time.strftime("%Y%m%d", date1)
date2 = headers['Date']
print date2
# 获取附件
self.get_attachment(msg, self._save_path)
def get_attachment(self,message,savepath):
attachments = []
for part in message.walk():
filename = part.get_filename()
if filename:
filename = self.decode_str(filename)
data = part.get_payload(decode=True)
abs_filename = os.path.join(savepath, filename)
attach = open(abs_filename, 'wb')
attachments.append(filename)
attach.write(data)
attach.close()
return attachments
if __name__ == "__main__":
get_enclosure()遇到的并且待验证问题:
1、报错pop3 ConnectionRefusedError: [WinError 10061] 由于目标计算机积极拒绝,无法连接。
一开始直接用的 server = poplib.POP3(pop3_server),所以连接偶尔报错上面的信息。
之后改成指定端口和超时时间之后就不再有报错信息了
server = poplib.POP3(pop3_server, 110, timeout=10)
或者 server = poplib.POP3_SSL(pop3_server, 995, timeout=10)
2、连接上服务器后,用账号密码登陆失败。报错,Error 10061,unable login on.
这个错误大概率是账号密码错误,请注意163邮箱的,如果开启了客户端授权码功能,登陆的密码应该用授权码!!!

3.连接服务器后,登陆失败:报错
这个错误是我登陆gmail时报错的,账号和密码都正确,但登陆依旧报错,因为Google的安全机制比较繁琐,不做特殊设置的话无法登陆。解决办法:

确认下账号是否开启了二次验证,如果开启了二次验证,则需要设置应用专用密码,使用应用专用密码登陆。
这个前提是开启了二次验证,开启的流程:https://support.google.com/accounts/answer/185833
如果没有开启二次验证,但仍然登陆不了,则检查是否开启了允许安全性较低的应用访问的权限,需要开启这个才能登陆

4。不同的邮箱可能也会导致一些莫名其妙的错误,使用Gmail邮箱,通过api获取邮件发现获取不到整个邮箱中的所有邮件。
用163邮箱则能够全部获取到,起初以为是因为邮件太多,存在分页,仔细看了官方文档并没有发现分页的方法,后来又用Java写了一套类似的读取邮件的服务,调用Java mail 的api发现依旧无法完全获取,比如我Gmail邮箱中有500+邮件,但用api只能拿到257封,很诡异。查了很久,最后确认应该是Gamil邮箱内部的处理导致,需要对Gmail做设置:
具体可参考文档:https://mail.google.com/support/bin/answer.py?hl=cn&answer=13291
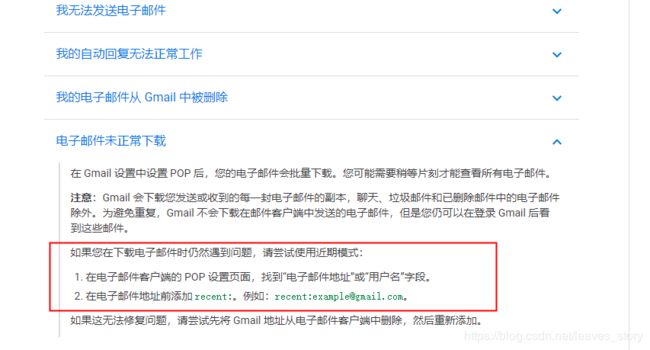
如果只是需要下载最近的邮件,可用使用recent:[email protected]的方式,这样就能拿到最近的邮件
5:部署线上可能会遇到:-ERR [AUTH] Web login required:http://www.xxxxx.xxxx.xxxxx
这个错误是因为你的Google账号在新机器上登陆,由于谷歌的安全策略,被认为是不安全的,被Google拒绝了登陆。可用拿Google账号到新机器登陆一次,并信任该机器。或者暂时解除锁定,或者点击下面链接,完成授权。
https://accounts.google.com/DisplayUnlockCaptcha