BeautifulSoup的soup.find_all()与 soup.select()赏析
如果我们用BeautifulSoup去解析网页来爬虫,那么90%以上需要用到find_all(),当然如果对CSS更为了解,其实select也是一种相当不错的选择。
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'lxml')
这是我们常用的炖汤程序,而对于汤的赏析,就需要用soup.find_all(),soup.select()去细细品味其中滋味。
1、find_all()
find_all(tag,attributes,recurisive, text, limit, keywords)
tag,即标签名,可以寻找单个标签find_all('h1'),也可以寻找一堆标签find_all(['h1','h2','h3'])
attributes,属性,即通过标签具有的属性来查找标签,其属性参数需要用字典封装。用法如 find_all(attr={'class':'red'}),或者find_all('class_' = 'red')。
recursive ,是否支持递归,默认为True,意思为是只查找文档的一级标签(子节点),还是查找文档的所有标签(子孙节点)。默认查找所有标签(子孙节点)。
text,文本。去用标签内的文本内容去匹配标签。find_all('a', text='inspirational')
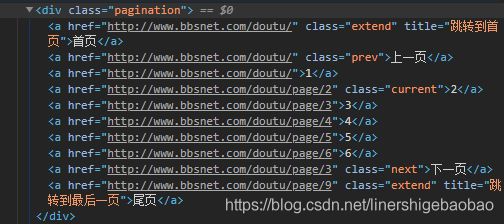
如在此查找下一页,并提取其链接。即可直接soup.find_all('a',text = '下一页')[0]['href']非常方便。
limit 限制获取结果的数目,设置参数后按照网页顺序选择设定好的前几项。
keyword,选择指定属性的标签 find_all(class_ = 'title') ,其相当于直接用属性选择,不设定标签名find_all('', {'class':'title'}) 当然使用关键词查找还是简化了不少。
注意:指定class属性时应该采用class_形式,因为class属于python中的关键字,为了与之区别。
另外text文本局限性比较大,具体详情可以参考https://www.jianshu.com/p/01780025d9a9。
一般我们大规模查找节点使用find_all是比较快速的,但是如果遇到查找比较精确的节点,个人比较推荐soup.select。
2、 soup.select() CSS选择器具体用法,可以参考https://www.runoob.com/cssref/css-selectors.html
soup.select('CSS选择器') 如 soup.select('ul li') 即选择所有ul内部的所有li节点。也可以通过属性的控制来更精确的定位元素。利用CSS选择器通俗易懂的选择方法能够更为精准的定位想要获得的元素。本人觉得主要方便在于
如
![]()
![]()
以索引的方式精确定位具有多个相同标签的某一个。
上边指一群P里边的第二个。下边指倒数第二个。通过输入数字不同,能够精确定位不具有属性区别的标签。