【Pattern学习】概述
1 简介
Pattern的下载地址为:http://www.clips.ua.ac.be/pattern
Pattern是Python编程语言的一个Web挖掘模块。它具有数据挖掘工具(谷歌,推特和维基百科API,Web爬虫,HTML DOM解析器)、自然语言处理(词性标注、n-gram搜索,情感分析,WordNet),机器学习(向量空间模型,聚类,支持向量机)、网络分析和可视化。
这些模块是免费的、有详细的文档说明以及附有50+个例子和350+单元测试。

2 安装
Pattern是为Python 2.5+编写的(不支持Python 3)。除了pattern.vector模块中LSA要求安装NumPy,没有其它外部依赖。
安装Pattern有两种方式。
方式一:使用下载的安装包进行安装。从文章开头给的下载地址中下载Pattern到本地磁盘中,解压后即可在命令行下进行安装,如下:
> cd pattern-2.6
> python setup.py install 方式二:利用pip进行安装。在命令行中使用pip进行自动安装,如下:
> pip install pattern 如果没有上述工作,你可以用三种方法让Python知道这个模块:
1、把Pattern压缩文件(.zip)放在Python中Script文件夹中。
2、把Pattern的子文件夹放在Python模型的标准位置中,这样就对所有的scripts可见。
c:\python27\Lib\site-packages\ (Windows),
/Library/Python/2.7/site-packages/ (Mac),
/usr/lib/python2.7/site-packages/ (Unix).
3、在引入的时候,将Pattern的位置追加到Python的script的系统路径,例如:
>>> import sys; sys.path.append('/users/tom/desktop/pattern')
>>> from pattern.web import Twitter3 模块
Pattern包含众多的子模块,有pattern.web、pattern.db、pattern.search、pattern.vector、pattern.graph、pattern.en、pattern.es、pattern.de、pattern.fr、pattern.it、pattern.nl等。
3.1 pattern.web
pattern.web:该模块具有在线数据挖掘工具,如异步请求、统一的Web服务API(谷歌、Bing、推特、脸谱网、维基百科、维基、Flickr、RSS)、HTML DOM解析器、HTML标签剥离功能、网络、邮件、缓存、支持Unicode。详情:pattern.web
>>> from pattern.web import Twitter, plaintext
>>>
>>> twitter = Twitter(language='en')
>>> for tweet in twitter.search('"more important than"', cached=False):
>>> print plaintext(tweet.text)
'The mobile web is more important than mobile apps.'
'Start slowly, direction is more important than speed.'
'Imagination is more important than knowledge. - Albert Einstein'
...3.2 pattern.en
pattern.en模块是一个英文自然语言处理(NLP)工具包。因为语言是模糊的(例如,我可以↔可以),所以它使用统计方法+正则表达式。这意味着它是快速、相当准确、偶尔不正确;它具有一个词性标注功能来识别词性(如名词、动词、形容词)、词变化(连词,单数)和WordNet的API。详情:pattern.en
>>> from pattern.en import parse
>>>
>>> s = 'The mobile web is more important than mobile apps.'
>>> s = parse(s, relations=True, lemmata=True)
>>> print s
'The/DT/B-NP/O/NP-SBJ-1/the mobile/JJ/I-NP/O/NP-SBJ-1/mobile' ... 
该文本已被注释为词性标注,例如名词(NN)、动词(VB),形容词(JJ)和限定词(DT),词的类型(例如,句子主语SBJ)和介词短语名词(PNP)。为了遍历标记文本中的部分,我们可以构造一个解析树。
>>> from pattern.en import parsetree
>>>
>>> s = 'The mobile web is more important than mobile apps.'
>>> s = parsetree(s)
>>> for sentence in s:
>>> for chunk in sentence.chunks:
>>> for word in chunk.words:
>>> print word,
>>> print
Word(u'The/DT') Word(u'mobile/JJ') Word(u'web/NN')
Word(u'is/VBZ')
Word(u'more/RBR') Word(u'important/JJ')
Word(u'than/IN')
Word(u'mobile/JJ') Word(u'apps/NNS')3.3 pattern.search
该模块有一个类似于正则表达式的模式匹配系统,可以通过语法(单词功能)或语义(单词含义)搜索一个字符串。详情:pattern.search
该模块包含一个从标记文本中检索单词序列的搜索算法(称为n-grams)。
>>> from pattern.en import parsetree
>>> from pattern.search import search
>>>
>>> s = 'The mobile web is more important than mobile apps.'
>>> s = parsetree(s, relations=True, lemmata=True)
>>>
>>> for match in search('NP be RB?+ important than NP', s):
>>> print match.constituents()[-1], '=>', \
>>> match.constituents()[0]
Chunk('mobile apps/NP') => Chunk('The mobile web/NP-SBJ-1')3.4 pattern.vector
该模块包含易于使用的机器学习工具,从字数统计功能、文档词袋和向量空间模型,到潜在语义分析、聚类和分类算法(朴素贝叶斯、K-NN、感知器、SVM)。详情:pattern.vector
>>> from pattern.web import Twitter
>>> from pattern.en import tag
>>> from pattern.vector import KNN, count
>>>
>>> twitter, knn = Twitter(), KNN()
>>>
>>> for i in range(1, 10):
>>> for tweet in twitter.search('#win OR #fail', start=i, count=100):
>>> s = tweet.text.lower()
>>> p = '#win' in s and 'WIN' or 'FAIL'
>>> v = tag(s)
>>> v = [word for word, pos in v if pos == 'JJ'] # JJ = adjective
>>> v = count(v)
>>> if v:
>>> knn.train(v, type=p)
>>>
>>> print knn.classify('sweet potato burger')
>>> print knn.classify('stupid autocorrect')
'WIN'
'FAIL'这个例子训练了从Twitter上挖掘的形容词的分类器。首先,挖掘带有标签#win或#fail的twitter。例如:“$20 tip off a sweet little old lady today #win”。单词的词性被解析,只保留形容词。每一条信息转化为一个向量,一个格式为[形容词,计数]的字典,标记为win或者fail。该分类器使用向量学习其他未知的twitter,判断其看起来更像win(如红薯汉堡)还是fail(例如,愚蠢的“自动更正”)。
3.5 pattern.graph
该模块具有图形分析工具(最短路径、中心)和浏览器中的图形可视化。图是由边连接节点所构成的网络,例如它可以用来研究社会网络或模型概念之间的语义关系。详情:pattern.graph
在下面的例子中,蓝色代表更多的中央节点(即更多传入的流量)。
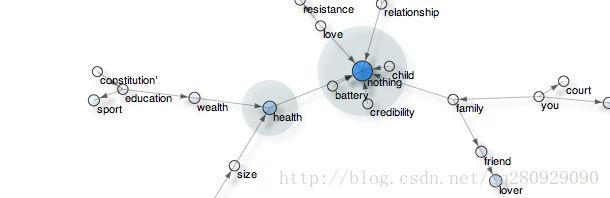
>>> from pattern.web import Bing, plaintext
>>> from pattern.en import parsetree
>>> from pattern.search import search
>>> from pattern.graph import Graph
>>>
>>> g = Graph()
>>> for i in range(10):
>>> for result in Bing().search('"more important than"', start=i+1, count=50):
>>> s = r.text.lower()
>>> s = plaintext(s)
>>> s = parsetree(s)
>>> p = '{NP} (VP) more important than {NP}'
>>> for m in search(p, s):
>>> x = m.group(1).string # NP left
>>> y = m.group(2).string # NP right
>>> if x not in g:
>>> g.add_node(x)
>>> if y not in g:
>>> g.add_node(y)
>>> g.add_edge(g[x], g[y], stroke=(0,0,0,0.75)) # R,G,B,A
>>>
>>> g = g.split()[0] # Largest subgraph.
>>>
>>> for n in g.sorted()[:40]: # Sort by Node.weight.
>>> n.fill = (0, 0.5, 1, 0.75 * n.weight)
>>>
>>> g.export('test', directed=True, weighted=0.6)3.6 其它
Pattern还包含如下子模块:
1、pattern.db:该模块包含包装数据库(SQLite、MySQL)、单码CSV文件和Python日期。它提供了一个便捷的处理表格数据的方式,例如检索与pattern.web模块。详情:pattern.db
2、pattern.es:该模块包含了一个快速的西班牙语词性标注(如在句子中识别名词、形容词、动词等)和西班牙语动词结合和名次单复数的工具。详情:pattern.es
3、pattern.de:该模块包含了一个快速的德语词性标注(如在句子中识别名词、形容词、动词等)和德语动词结合和名次单复数的工具。详情:pattern.de
4、pattern.fr:该模块包含了一个快速的法语词性标注(如在句子中识别名词、形容词、动词等)和法语动词结合和名次单复数的工具。详情:pattern.fr
5、pattern.it:该模块包含了一个快速的意大利语词性标注(如在句子中识别名词、形容词、动词等)和意大利语动词结合和名次单复数的工具。详情:pattern.it
6、pattern.nl:该模块包含了一个快速的荷兰语词性标注(如在句子中识别名词、形容词、动词等)和荷兰语动词结合和名次单复数的工具。详情:pattern.nl