2、python爬虫学习项目之第三方代理IP的使用
在做爬虫的过程中,如果你爬取的频率过快,不符合人的操作模式。有些网站的反爬虫机制通过监测到你的IP异常,访问频率过高。就会对你进行封IP处理。目前已有比较多的第三方平台专门进行代理IP的服务,我们调用其API接口就可以随机获取到平台给定的IP。这里推荐几个比较常用的代理平台:
- 阿布云:https://www.abuyun.com/
- 讯代理:http://www.xdaili.cn/web
- 芝麻HTTP:http://h.zhimaruanjian.com/
- 蘑菇代理:http://www.moguproxy.com/
- goubanjia:http://www.goubanjia.com/(这个有少量的免费代理IP在主页,可以进行使用)
- 知乎总结:https://www.zhihu.com/question/55807309/answer/294370242
目前并不推荐使用讯代理的动态转发了,动态转发虽然便宜实惠,但是不够稳定,对于需要稳定爬取的程序来说,这并不友好。目前使用的芝麻HTTP,相对来说会稳定的多,0.4毛一个代理,有效时间5-25分钟,对于小爬虫来说性价比还是很高的。
--------------------分割线-----------------
今天这篇文章使用的第三方平台代理是讯代理,这个网站提供了HTTP代理、固定IP、动态转发等多种代理模式。对于目前自己做小型项目学习的朋友来说,使用动态转发就可以了。动态转发相较于传统的代理池来说也是比较方便的,讯代理官方也给出了2个方法的比较图:
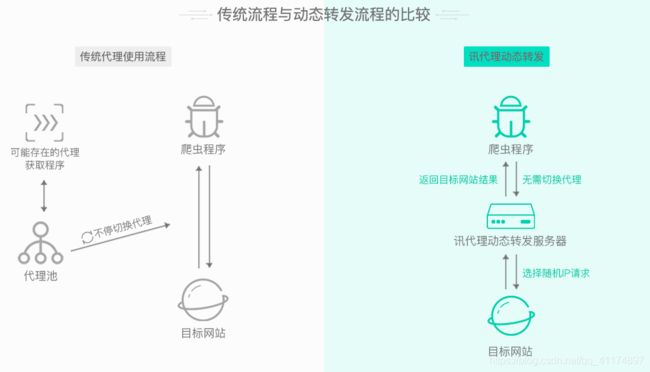
- 打开首页到购买代理,滑动到最下方,点击购买即可
- 20块钱10W次,有效期半年,基本是够用了
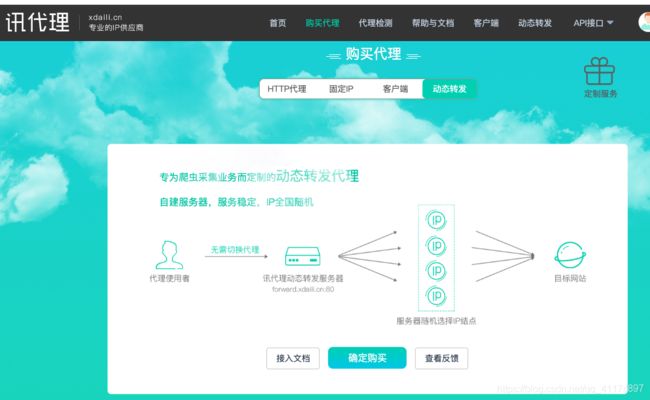

购买动态转发后,来到帮助与文档页面,这里也有相应的接入文档教程和在github上的示例代码

接下来说一下这使用这个第三方平台代理的时候遇到了几个问题:
1、根据官方文档,我们需要传入3个参数secret、orderno、timestamp
- orderno:在个人中心-->我的订单
- secret:个人中心-->账户管理(之前找了很久- -)
- timestamp:这个是在代码中通过调用time( )方法返回当前时间的时间戳外网
2、在代码中会出现几个容易出错的错误点:
- 按照官方文档,需要对以上三个参数组合的字符串进行哈希算法加密生成一个sign。而如果想要使用哈希算法对字符串进行处理,需要制定它的编码格式,否则会报错:string.encode()(这里可以选填'utf-8')
- 在对三个参数进行拼接成字符串的时候需要注意:orderno、secret、timestamp单词不能出现错误,否则你在向讯代理平台请求代理的时候会报各种错误:
- 之前把timestamp单词写错,报错:

- 而后把orderno写错,报错:

- 所以这里还是提醒大家注意书写格式,最好是直接复制粘贴,手写容易出现不必要的错误
3、这里再提供一个网站进行IP测试:http://2000019.ip138.com/(目前这个位置已经更换,不能使用)
现在改用访问:https://2020.ip138.com/
访问这个网站它会自动将你的IP地址显示出来。我们爬虫程序只要对get请求中的参数传入proxies=proxy,在proxy中进行ip封装如:proxy={"https":"127.0.0.0:80"}。就会自动将IP伪装在请求中。再通过打印访问这个网站返回的响应数据,就可以查看到代理IP是否起作用了。以下为示例代码:
import requests
import time
import hashlib
#从个人中心中获得
orderno = "ZF2020218xxxxxx"
secret = "a2b58eccc5ae4fxxxxxxxxxxxxxxxxxxxx"
t = time.time()
timestamp = str(int(time.time()))
ip = "forward.xdaili.cn"
port = "80"
ip_port = ip +":"+port
string = "orderno=%s,secret=%s,timestamp=%s"%(orderno,secret,timestamp)
#如果你要使用哈希算法进行加密,必须对字符串进行encode处理.可以填utf-8,也可以不填
string = string.encode('utf-8')
md5_string = hashlib.md5(string).hexdigest()
sign = md5_string.upper()
auth = "sign=%s&orderno=%s&secret=%s×tamp=%s"%(sign,orderno,secret,timestamp)
proxy = {
'http':'http://'+ip_port,
'https': 'https://' +ip_port
}
headers = {
"Proxy-Authorization":auth,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"
}
r = requests.get("http://2000019.ip138.com", headers=headers, proxies=proxy)
r.encoding = 'utf-8'
print(r.text)-------------------分割线--------------
2019.3.10更新:
对于使用讯代理,一直忽略了一个重要的问题,导致有时候出错找不到问题点。
但若没有忽略证书验证,按照代码在proxy下将http和https开启的话会怎样?会报错!这个错误出现的原因是在设置动态代理获取的headers-->Proxy-Authorization中没有获取到IP值。按照之前部分在网络上查到的资料,有的网友说需要把https的链接给注释
requests.exceptions.ProxyError: HTTPSConnectionPool(host='2020.ip138.com', port=443): Max retries exceeded with url: / (Caused by ProxyError('Cannot connect to proxy.', ConnectionResetError(54, 'Connection reset by peer')))
然而按照注释,仍然有时候出现错误,困恼许久。

requests.exceptions.SSLError: HTTPSConnectionPool(host='2020.ip138.com', port=443): Max retries exceeded with url: / (Caused by SSLError(SSLError("bad handshake: SysCallError(-1, 'Unexpected EOF')")))
终于重新刷一遍开发文档,才发现对于https,需要忽略证书验证!!!因为访问的是https的网站,所以如果把这个注释了的话会出现以上错误。所以需要在访问时,开启忽略证书验证。
verify:是否验证证书
allow_redirects:是否重定向
response = requests.get(url=url,headers=headers,proxies=proxy,verify=False,allow_redirects=False)
至此,就能完美的使用讯代理的动态转发了,开发文档要好好开- -