Java多线程网络爬虫(时光网为例)
目录
- 多线程简介
- 多线程网络爬虫
- 分析要爬的数据
- 网络抓包
- 爬虫框架
- model
- MtimeThread主方法
- MtimeParse解析数据
- 数据库操作
多线程简介
Java多线程实现方式主要有三种:继承Thread类、实现Runnable接口、使用ExecutorService、Callable、Future实现有返回结果的多线程。其中前两种方式线程执行完后都没有返回值,只有最后一种是带返回值的。
本文所采用的方法是继承Thread类的方法,Thread本质上也是实现了Runnable接口的一个实例,它代表一个线程的实例。启动线程的唯一方法就是通过Thread类的start()实例方法。start()方法是一个native方法,它将启动一个新线程,并执行run()方法。这种方式实现多线程很简单,通过自己的类直接extend Thread,并复写run()方法,就可以启动新线程并执行自己定义的run()方法。
多线程网络爬虫
为了加快爬虫速度,可以采用多线程网络爬虫的方法。以下我以时光网为例,写一个简单的网络爬虫。
分析要爬的数据
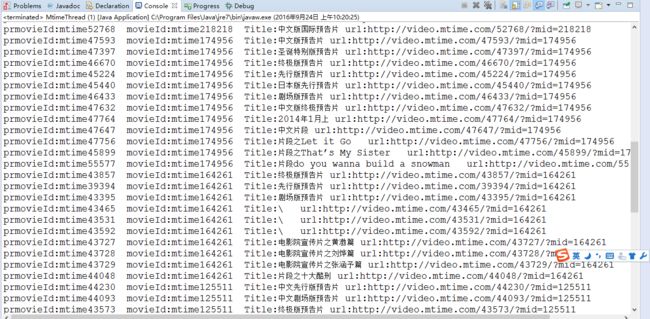
如下面数据,为我爬的一些电影预告片的初始信息,存在数据库movie的这张表中。

下表是我所要爬的预告片相关的数据,包括预告片的id(prmovieId),预告片的链接(url),预告片对应的电影id(movieId),预告片的标题(title)。后面会在model框架中,你会发现,我会把这些待爬取的数据封装在MtimeModel中。
网络抓包
通过网络抓包的方式,查看数据的获取方式、方法。即真实请求的地址及返回数据的格式(html or json).
如果你不会网络抓包,请参考我前面所写的与爬虫相关的一系列博客,或者这个地址:http://blog.csdn.net/qy20115549/article/details/52249232
爬虫框架
如果想了解,为什么这样写,请看我前面的介绍网络爬虫框架的文章。
model
model里面主要写了三个,我们需要的,一个是MtimeUrl封装的是数据库movie这张表中某些数据对应的信息。
MtimeModel封装的是需要爬取数据的信息。
package org.autodata.model;
/*
* author:合肥工业大学 管院学院 钱洋
*[email protected]
*/
public class MtimeUrl {
//待爬取电影的id和对应的连接
private String id;
private String url;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
爬取的数据为:
package org.autodata.model;
/*
* author:合肥工业大学 管院学院 钱洋
*[email protected]
*/
public class MtimeModel {
private String prmovieId;
private String url;
private String movieId;
private String title;
public String getPrmovieId() {
return prmovieId;
}
public void setPrmovieId(String prmovieId) {
this.prmovieId = prmovieId;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getMovieId() {
return movieId;
}
public void setMovieId(String movieId) {
this.movieId = movieId;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
}
Json数据的解析model
package org.autodata.model;
/*
* author:合肥工业大学 管院学院 钱洋
*[email protected]
*/
public class JsonModel {
private String VideoID;
private String MovieID;
private String ShortTitle;
private String prmovieId;
private String url;
public String getVideoID() {
return VideoID;
}
public String getShortTitle() {
return ShortTitle;
}
public void setShortTitle(String shortTitle) {
ShortTitle = shortTitle;
}
public String getPrmovieId() {
return prmovieId;
}
public void setPrmovieId(String prmovieId) {
this.prmovieId = prmovieId;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public void setVideoID(String videoID) {
VideoID = videoID;
}
public String getMovieID() {
return MovieID;
}
public void setMovieID(String movieID) {
MovieID = movieID;
}
}
MtimeThread主方法
主方法里为了方便,我直接使用的是Jsoup去请求数据,建议大家还是使用httpclient,因为有时候Jsoup是失灵的。
package org.autodata.navi.main;
/*
* author:合肥工业大学 管院学院 钱洋
*[email protected]
*/
import java.io.IOException;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import javax.sql.DataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.ResultSetHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.autodata.db.MyDataSource;
import org.autodata.model.MtimeModel;
import org.autodata.model.MtimeUrl;
import org.autodata.parse.MtimeParse;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class MtimeThread extends Thread{
public static DataSource ds = MyDataSource.getDataSource("jdbc:mysql://127.0.0.1:3306/moviedata");
public static QueryRunner qr = new QueryRunner(ds);
String Starturl = "";
String Id="";
//构造函数,初始化使用
public MtimeThread (String Starturl,String Id){
this.Starturl = Starturl;
this.Id = Id;
}
public void run(){
List moviedatas=new ArrayList();
//这里采用jsoup直接模拟访问网页
try {
Document doc = Jsoup.connect(Starturl).userAgent("bbb").timeout(120000).get();
moviedatas =MtimeParse.getData(doc);
} catch (IOException e) {
e.printStackTrace();
}
for (MtimeModel mt:moviedatas) {
System.out.println("prmovieId:"+mt.getPrmovieId()+" movieId:"+mt.getMovieId()+" Title:"+mt.getTitle()
+" url:"+mt.getUrl());
}
try {
MYSQLControl.executeUpdate(moviedatas,Id);
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws SQLException{
ResultSetHandler> h = new BeanListHandler(MtimeUrl.class);
List Starturls = qr.query("SELECT id,url FROM moviedata.movie WHERE website='时光网' and is_crawler=0", h);
//创建固定大小的线程池
ExecutorService exec = Executors.newFixedThreadPool(5);
for (MtimeUrl Start:Starturls) {
//执行线程
exec.execute(new MtimeThread(Start.getUrl(),Start.getId()));
}
//线程关闭
exec.shutdown();
}
}
MtimeParse解析数据
package org.autodata.parse;
/*
* author:合肥工业大学 管院学院 钱洋
*[email protected]
*/
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.autodata.model.JsonModel;
import org.autodata.model.MtimeModel;
import org.jsoup.nodes.Document;
import com.alibaba.fastjson.JSON;
public class MtimeParse {
public static List getData (Document doc) {
List mtimeData=new ArrayList();
//获取待解析的html文件
String html=doc.html();
//fastJson测试
//just contain the preview
List mtimeJsonData=new ArrayList();
Pattern data1 = Pattern.compile("预告片\":(.*?)\\,(\"拍摄花絮|\"精彩片段)");
Matcher dataMatcher1 = data1.matcher(html);
String da1="";
while (dataMatcher1.find()) {
//待解析的json字符串
da1=dataMatcher1.group(1);
}
if (da1.length()!=0) {
List jsonmodel1 = JSON.parseArray(da1,JsonModel.class);
for (JsonModel jso:jsonmodel1 ) {
JsonModel mtimeModel=new JsonModel();
String VideoID="mtime"+jso.getVideoID();
String MovieID="mtime"+jso.getMovieID();
String ShortTitle=jso.getShortTitle();
String url="http://video.mtime.com/"+jso.getVideoID()+"/?mid"+jso.getMovieID();
mtimeModel.setPrmovieId(VideoID);
mtimeModel.setUrl(url);
mtimeModel.setMovieID(MovieID);
mtimeModel.setShortTitle(ShortTitle);
mtimeJsonData.add(mtimeModel);
}
}
return mtimeData;
}
} 数据库操作
MyDataSource
package org.autodata.db;
import javax.sql.DataSource;
import org.apache.commons.dbcp2.BasicDataSource;
/*
* author:合肥工业大学 管院学院 钱洋
*[email protected]
*/
public class MyDataSource {
public static DataSource getDataSource(String connectURI){
BasicDataSource ds = new BasicDataSource();
//MySQL的jdbc驱动
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUsername("root"); //所要连接的数据库名
ds.setPassword("112233"); //MySQL的登陆密码
ds.setUrl(connectURI);
return ds;
}
}package org.autodata.db;
import java.sql.SQLException;
import java.util.List;
import javax.sql.DataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.autodata.model.MtimeCommentModel;
import org.autodata.model.MtimeModel;
/*
* author:合肥工业大学 管院学院 钱洋
*[email protected]
*/
public class MYSQLControl {
static final Log logger = LogFactory.getLog(MYSQLControl.class);
static DataSource ds = MyDataSource.getDataSource("jdbc:mysql://127.0.0.1:3306/moviedata");
static QueryRunner qr = new QueryRunner(ds);
//第一类方法
public static void executeUpdate(String sql){
try {
qr.update(sql);
} catch (SQLException e) {
logger.error(e);
}
}
//第二类数据库操作方法
public static void executeUpdate(List moviedata,String id) throws SQLException {
//定义一个Object数组,行列
Object[][] params = new Object[moviedata.size()][4];
for ( int i=0; i0] = moviedata.get(i).getPrmovieId();
params[i][1] = moviedata.get(i).getMovieId();
params[i][2] = moviedata.get(i).getUrl();
params[i][3] = moviedata.get(i).getTitle();
}
try{
qr.batch("insert into movieURL (prmovieId, movieId, url, title)"
+ "values (?,?,?,?)", params);
qr.update("update movie set is_crawler=1 where id='"+id+"'");
}catch( Exception e){
logger.error(e);
}
}
//操作评论的数据库
public static void executeUpdate1(List moviedata,String id) throws SQLException {
Object[][] params = new Object[moviedata.size()][3];
for ( int i=0; i0] = moviedata.get(i).getComm_id();
params[i][1] = moviedata.get(i).getComment();
params[i][2] = moviedata.get(i).getTime() ;
}
try{
qr.batch("insert into moviecomment (comm_id, prmovieId,comment, time)"
+ "values (?,'"+id+"',?,?)", params);
qr.update("update movieurl set is_crawler=1 where prmovieId='"+id+"'");
}catch( Exception e){
logger.error(e);
}
}
}
程序运行结果: