《NoSQL精粹》笔记
本书为考虑是否可以使用和如何使用nosql数据库的企业提供了可靠的决策依据。它由世界级软件开发大师和软件开发“教父”Martin Fowler与Jolt生产效率大奖图书作者Pramod J. Sadalage共同撰写。书中全方位比较了关系型数据库与NoSQL数据库的异同;分别以Riak、Mongodb、Cassandra和Neo4J为代表,详细讲解了键值数据库、文档数据库、列族数据库和图数据库这4大类NoSQL数据库的优劣势、用法和适用场合;深入探讨了实现NoSQL数据库系统的各种细节,以及与关系型数据库的混用。
第一部分 概念
第一章 为什么使用NoSQL
- 由于关系模型与内存中的数据结构不匹配,所以应用程序开发人员一直为这种阻抗失谐问题所困扰。
- 促使数据存储方式发生变化的重要原因是:需要在集群上运行大量数据,而关系型数据库不能在集群中高效运行。
- 各种NoSQL的共同特性是:
- 不使用关系模型
- 在集群中运行良好
- 开源
- 无模式
第二章 聚合数据模型
NoSQL技术与传统的关系型数据库相比,一个最明显的转变就是抛弃了关系模型。每种NoSQL解决方案的模型都不同:键值、文档、列族、图。前三类数据模型都有一个共同特征,我们称其为“面向聚合”。
聚合
虽然关系映射能很好地捕捉各种数据元素及其关系,但是它却没有“聚合实体”这一概念。在关系模型中,可以用外键来表达这种关系,但这样做也无法区分某个关系是否表示聚合。因此,无法使用结合结构来帮助其存储与分布数据。
选用面向聚合模型的决定性因素,就在于它非常适合在集群上运行。此时,需要把采集数据时所需的节点数降至最小。如果在数据库中明确包含聚合结构,那么它就可以根据这一重要信息,知道哪些数据需要一起操作了,这些数据应该放在同一节点中。
通常情况下,面向聚合的数据库确实不支持跨越多个聚合的ACID事务,取而代之的是,它每次只能在一个聚合结构上执行原子操作。
面向聚合数据库
- 键值数据模型将聚合看做不透明的整体,这意味着,只能通过键来查询整个聚合,而不能仅仅查询或获取其中的一部分。
- 文档模型的聚合对数据库透明,于是就可以只查询并获取其中一部分数据。不过,由于文档没有模式,因此在优化存储并获取聚合中的部分内容时,数据库不太好调整文档结构。
- 列族模型把数据分为列族,让数据库将其视为行聚合内的一个数据单元。此类聚合的结构有某种限制(列必须属于某个列族,列族需要预先定义),但是数据库可利用此种结构的优点来提高其易访问性(一次访问列族中的所有数据)。
第三章 数据模型详解
- 使用面向聚合的数据库处理不同聚合之间的关系,要比处理同一聚合内部的关系更难。
- 图数据库将数据组织成一张由节点和边所组成的图,它们适合处理关系负责的数据结构。
- 在无模式数据库中,可以给记录随意新增字段。然而在使用数据时,还是要在代码端,对数据结构做一系列约定。此外,由于感知不到模式,所以无法用模式提升存储与查询效率,也无法自行验证数据。
- 面向聚合的数据库通常能够用不同方式重组主聚合的数据,以计算出各种“物化视图”(相比于普通视图,物化视图提前进行计算并保存,而不是使用时再计算)。计算过程一般通过“Map-Reduce”实现。
第四章 分布式模型
数据分布有两种方式,可以选中一种,也可以混合使用:
-
分片:将数据的不同部分存放在多个服务器中,每个数据子集由一台服务器专门负责。
-
复制:将数据复制到多个服务器上。
复制又分为两种形式:
- 主从复制:将其中一个节点作为权威数据源,负责写。其他从节点和主节点保持同步,负责读。
- 对等复制:任何节点均可写入,节点间相互协调以同步数据。
主从复制减少了更新数据时的冲突几率,但会使主节点出现写入瓶颈。
第五章 一致性
一致性有多种表现形式:
- 更新一致性:悲观锁、乐观锁
- 读取一致性
- 逻辑一致性:事务
- 复制一致性:要求从不同副本中读取同一数据时,得到的值相同。解决:最终一致性
- read-your-writes consistency : 照原样读出所写内容的一致性。解决:1.采用粘性会话(绑定到集群的固定节点),保证会话一致性;2.采用版本戳,保证会话一致性
CAP
集群必须容忍“网络分区”,这正是CAP定理的意义所在。当系统遭遇“分区”状况时(如分布式系统),需要在“一致性”和“可用性”之间权衡。这并不是一个二选一的决定,通常来说,我们都会略微舍弃“一致性”,以获取某种程度的“可用性”。这样产生的系统,既不具备完美的一致性,也不具备完美的可用性。但是,这两种不完美的特性结合起来,却能满足特定需求。
CP:
M和P都想预订酒店的最后一个房间,预订系统采用“对等式分布模型”,他由两个节点组成。M使用伦敦的节点,P使用孟买的节点。若要确保一致性,那么当M要通过位于伦敦的节点预订房间时,该节点在确认预订操作之前,必须先告知位于孟买的节点。两个节点必须按照相互一直的顺序来处理他们说收到的操作请求。此方案保证了已制定,但若网络发生故障,则两个“分区”系统都无法预订,于是系统失去了可用性。
权衡C与A:
改善可用性的一种办法是,指派其中一个节点作为某家旅馆的主节点,确保所有预订操作都由主节点处理。假设孟买是主节点,当发生网络故障时,它仍可处理预订工作,P将订到最后一个房间。在使用“主从复制”模型时,位于伦敦的用户看到的房间剩余情况会与孟买不一致,但是他们无法预订客房,于是就出现了更新不一致。而且当发生网络故障时,位于伦敦的节点无法预订客房。
AP:
继续提高可用性,可以让两个分区系统都接收预订请求,即使在发生网路故障时也是如此。那么,M和P有可能都预订到了最后一间客房。
在讨论分布式系统的一致性时,通常可以概括的说:参与交互操作的节点越多,一致性就越好。然而这样会导致产生交互延时,导致可用性下降。
上面预订酒店的例子,就是一步步降低参与预订操作的节点数,来逐渐提高可用性的。
仲裁
为了保证强一致性,不需要所有节点都确认写入操作。
- 写入仲裁:参与写入的节点数W,必须超过副本总数N(又称复制因子)的一半,W>N/2。如果发生两个互相冲突的写入操作,那么只有其中一个操作能成为超过半数的节点认可。
- 读取操作:要想保证能读到最新数据,必须与多少个节点联系?R+W>N。R:读操作需联系的节点个数。
第七章 映射-化简
把数据放在集群之后,立刻就带来一个好处,那就是可以把运算工作分布到多台计算机。然而,此时仍要试着减少通过网络传输的数据量,把某个节点所需的数据尽可能多地放在该节点上执行。
map-reduace 模式是一种安排数据处理流程的手段。可以利用集群中的多台计算机,同时有能将某台计算机所需的数据及处理工作尽量放在本机完成。
以下部分转自https://www.jianshu.com/p/296bacba3510
不同NoSQL类型对比
键值数据库
特点
以Redis为例:
优点如下:
- 性能极高:Redis能支持超过10W的TPS
- 丰富的数据类型: Redis支持包括String,Hash,List,Set,Sorted Set,Bitmap和hyperloglog
- 丰富的特性:Redis还支持 publish/subscribe, 通知, key 过期等等特性
缺点如下:
针对ACID,Redis事务不能支持原子性和持久性(A和D),只支持隔离性和一致性(I和C)
特别说明一下,这里所说的无法保证原子性,是针对Redis的事务操作,因为事务是不支持回滚(roll back),而因为Redis的单线程模型,Redis的普通操作是原子性的
大部分业务不需要严格遵循ACID原则,例如游戏实时排行榜,粉丝关注等场景,即使部分数据持久化失败,其实业务影响也非常小。因此在设计方案时,需要根据业务特征和要求来做选择
使用场景
- 适用场景
储存用户信息(比如会话)、配置文件、参数、购物车等等。这些信息一般都和ID(键)挂钩 - 不适用场景
- 需要通过值来查询,而不是键来查询。Key-Value数据库中根本没有通过值查询的途径。
- 需要储存数据之间的关系。在Key-Value数据库中不能通过两个或以上的键来关联数据
- 需要事务的支持。在Key-Value数据库中故障产生时不可以进行回滚。
文档数据库
相关特性
以MongoDB为例进行说明
优点如下:
- 新增字段简单
无需像关系型数据库一样先执行DDL语句修改表结构,程序代码直接读写即可 - 容易兼容历史数据
对于历史数据,即使没有新增的字段,也不会导致错误,只会返回空值,此时代码兼容处理即可 - 容易存储复杂数据
JSON是一种强大的描述语言,能够描述复杂的数据结构
相比传统关系型数据库,文档数据库的缺点主要是对多条数据记录的事务支持较弱,具体体现如下:
- Atomicity(原子性)
仅支持单行/文档级原子性,不支持多行、多文档、多语句原子性 - Isolation(隔离性)
隔离级别仅支持已提交读(Read committed)级别,可能导致不可重复读,幻读的问题 - 不支持复杂查询
例如join查询,如果需要join查询,需要多次操作数据库
MongonDB还是支持多文档事务的Consistency(一致性)和Durability(持久性)
虽然官方宣布MongoDB将在4.0版本中正式推出多文档ACID事务支持,最后落地情况还有待见证。
使用场景
适用场景:
- 数据量很大或者未来会变得很大
- 表结构不明确,且字段在不断增加,例如内容管理系统,信息管理系统
不适用场景:
- 在不同的文档上需要添加事务。Document-Oriented数据库并不支持文档间的事务
- 多个文档直接需要复杂查询,例如join
列族数据库
相关特性
优点如下:
- 高效的储存空间利用率
列式数据库由于其针对不同列的数据特征而发明的不同算法使其往往有比行式数据库高的多的压缩率,普通的行式数据库一般压缩率在3:1 到5:1 左右,而列式数据库的压缩率一般在8:1到30:1 左右。
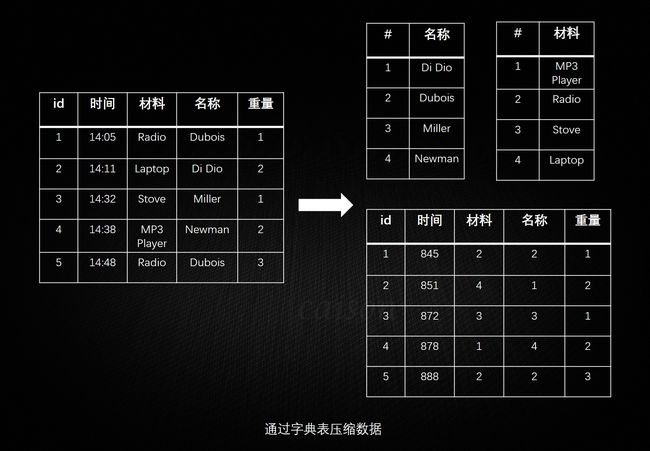
比较常见的,通过字典表压缩数据:
下面中才是那张表本来的样子。经过字典表进行数据压缩后,表中的字符串才都变成数字了。正因为每个字符串在字典表里只出现一次了,所以达到了压缩的目的(有点像规范化和非规范化Normalize和Denomalize)
- 查询效率高
读取多条数据的同一列效率高,因为这些列都是存储在一起的,一次磁盘操作可以数据的指定列全部读取到内存中。
下图通过一条查询的执行过程说明列式存储(以及数据压缩)的优点
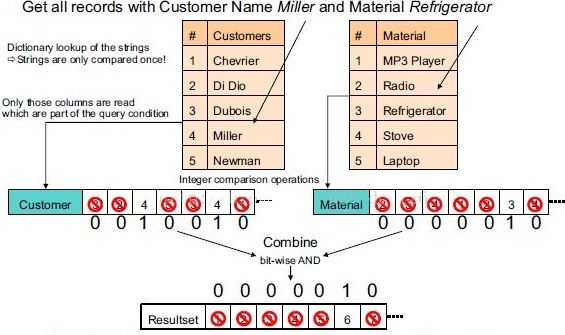
执行步骤如下:
i. 去字典表里找到字符串对应数字(只进行一次字符串比较)。
ii. 用数字去列表里匹配,匹配上的位置设为1。
iii. 把不同列的匹配结果进行位运算得到符合所有条件的记录下标。
iv. 使用这个下标组装出最终的结果集。
- 适合大量的数据而不是小数据
缺点如下:
- 不适合扫描小量数据
- 不适合聚合计算(AVG、SUM),只能把每行数据读到客户端然后处理
- 不适合随机的更新
- 不适合做含有删除和更新的实时操作
- 单行的数据是ACID的,多行的事务时,不支持事务的正常回滚,支持 I(Isolation)隔离性(事务串行提交),D(Durability)持久性,不能保证 A(Atomicity)原子性, C(Consistency)一致性
使用场景
以HBase为例说明:
- 大数据量 (100s TB级数据) 且有快速随机访问的需求
- 同一列族常常需要一起访问
- 写密集型应用,每天写入量巨大,而相对读数量较小的应用
比如IM的历史消息,游戏的日志等等 - 不需要复杂查询条件来查询数据的应用
HBase只支持基于rowkey的查询,对于HBase来说,单条记录或者小范围的查询是可以接受的,大范围的查询由于分布式的原因,可能在性能上有点影响,HBase不适用与有join,多级索引,表关系复杂的数据模型 - 对性能和可靠性要求非常高的应用
由于HBase本身没有单点故障,可用性非常高。 - 数据量较大,而且增长量无法预估的应用,需要进行优雅的数据扩展的
HBase支持在线扩展,即使在一段时间内数据量呈井喷式增长,也可以通过HBase横向扩展来满足功能。 - 存储结构化和半结构化的数据
参考
《NoSQL精粹》
NoSQL 还是 SQL ?这一篇讲清楚