2019.5.23,今天学习了selenium+chromedriver获取动态数据:
selenium相当于是一个机器人一样,可以模拟人的行为,例如:点击,填充数据,翻页等。chromedriver是驱动Chrome浏览器的一个驱动程序。必须通过chromedriver才能得到一个driver,爬虫才能模拟人的行为。


1 # Author:K 2 from selenium import webdriver 3 import time 4 driver_path = r'D:\ChromeDriver\chromedriver.exe' 5 6 driver = webdriver.Chrome(executable_path = driver_path) 7 8 url = 'https://www.baidu.com/' 9 driver.get(url) 10 11 # 用类名查找的方式 12 inputTag = driver.find_element_by_class_name('s_ipt') 13 inputTag.send_keys('python') 14 15 ################################################## 测试点击按钮 ################################################## 16 submitTag = driver.find_element_by_id('su') 17 submitTag.click() 18 19 ################################################### 测试checkbox ################################################### 20 url = 'http://www.renren.com/' 21 driver.get(url) 22 autoLoginBtn = driver.find_element_by_id('autoLogin') 23 autoLoginBtn.click() 24 25 # 测试select下拉菜单 由于没找到对应的网站,找到后将xxx写成相应数据即可 26 from selenium.webdriver.support.ui import Select 27 url = 'xxx' 28 select = Select(driver.find_element_by_id('xxx')) # 要用Select修饰一下 29 select.select_by_value('xxx') 30 31 ################################################### 行为链测试 ################################################### 32 from selenium.webdriver.common.action_chains import ActionChains 33 34 driver = webdriver.Chrome(executable_path = driver_path) 35 36 url = 'https://www.baidu.com/' 37 driver.get(url) 38 39 inputTag = driver.find_element_by_id('kw') 40 print(inputTag) # !!!!!!!!!!为什么这里打印的是元素,下面测试WebElement打印的是列表?!!!!因为这里写的是element 41 summitBtn = driver.find_elements_by_id('su')[0] # 返回一个button的时候是列表 42 print(summitBtn) 43 44 actions = ActionChains(driver) 45 actions.move_to_element(inputTag) 46 actions.send_keys_to_element(inputTag,'python') 47 actions.move_to_element(summitBtn) 48 actions.click(summitBtn) 49 actions.perform() # 为什么会出错???? 50 51 ################################################### 测试 cookie ################################################### 52 url = 'https://www.baidu.com/' 53 driver.get(url) 54 for cookie in driver.get_cookies(): 55 print(cookie) 56 57 cookie = driver.get_cookie('BDORZ') 58 print(cookie) 59 60 driver.delete_all_cookies() # 删除所有cookie 61 62 ################################################### 测试页面等待 ################################################### 63 from selenium.webdriver.support.ui import WebDriverWait 64 from selenium.webdriver.support import expected_conditions as EC 65 from selenium.webdriver.common.by import By 66 67 url = 'https://www.baidu.com' 68 driver.get(url) 69 70 ''' 71 隐式等待:创建driver时就创建一个最长等待时间,得不到元素就一直等直到超时 72 (弊端:要等待整个页面加载完成,那些不需要用到的元素也必须加载出来才算完成) 73 ''' 74 driver.implicitly_wait(5) 75 76 ''' 77 显式等待:等5秒,条件满足就执行,否则等到时间结束 78 ''' 79 element = WebDriverWait(driver,5).until( 80 EC.presence_of_element_located((By.ID,'su')) 81 ) 82 83 print(element) 84 85 time.sleep(10) 86 driver.close() 87 88 ################################################### 测试页面切换 ################################################### 89 90 url = 'https://www.baidu.com' 91 driver.get(url) 92 driver.execute_script('window.open("http://www.renren.com/")') 93 print(driver.current_url) 94 print(driver.window_handles) # 打印浏览器中网页的句柄 95 driver.switch_to.window(driver.window_handles[1]) # 将driver转到句柄列表为1的窗口下 96 print(driver.current_url) 97 98 ################################################### 测试代理 ################################################### 99 100 url = 'http://httpbin.org/ip' 101 102 options = webdriver.ChromeOptions() 103 options.add_argument('--proxy-server=http://120.234.63.196:3128') 104 105 driver = webdriver.Chrome(executable_path = driver_path,chrome_options = options) 106 driver.get(url) 107 108 ################################################### 测试WebElement ################################################### 109 url = 'https://www.baidu.com' 110 driver.get(url) 111 summitBtn = driver.find_elements_by_id('kw') #find返回的是一个列表 112 print(summitBtn) # !!!!!!!!!为什么这里打印的是列表,上面测试行为链打印的是元素?!!!!因为这里写的是elements 113 print(summitBtn.get_attribute('class')) 114 115 time.sleep(10) 116 117 driver.quit()
另外,今天做了一个小案例,爬取“乌托家”的家具公司的数据,代码如下:
1 # Author:K 2 import requests 3 from lxml import etree 4 import os 5 6 HEADERS = { 7 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36' 8 } 9 10 def parse_page(url): 11 response = requests.get(url=url, headers=HEADERS) 12 page_text = response.text 13 tree = etree.HTML(page_text) 14 li_list = tree.xpath('//ul[@class="rec-commodity-ul targetElement"]/li') 15 for li in li_list: 16 merchant_href = li.xpath('.//div[@class="impression"]/a/@href')[0] 17 merchant_name = li.xpath('.//div[@class="impression"]/a/text()')[0] 18 commodity_name = li.xpath('.//div[@class="material"]/a/text()')[0] 19 # print(merchant_href,merchant_name,commodity_name) 20 detail_page_text = requests.get(url=merchant_href, headers=HEADERS).text 21 tree = etree.HTML(detail_page_text) 22 div_infos = tree.xpath('//div[@class="brand-r"]') 23 for div in div_infos: 24 try: 25 brand_name = div.xpath('./div[4]/dl/dd/text()')[0] 26 addr = div.xpath('.//p/text()')[0] 27 phone = div.xpath('.//dd[2]/text()')[0] 28 # print(brand_name, addr, phone) 29 30 # 持久化存储 31 file_path = 'H:/乌托家/乌托家家具公司.txt' 32 fp = open(file_path, 'r+', encoding='utf-8') 33 if brand_name not in fp.read(): 34 if str(addr).__contains__('广东'): 35 fp.write(brand_name+' '+addr+' '+phone+'\n\n') 36 print(brand_name,'爬取成功!!!') 37 fp.close() 38 except Exception as e: 39 print(e) 40 41 42 def get_page(): 43 for page in range(1,413): 44 url = 'http://www.wutuojia.com/item/list.html?page=' + str(page) 45 parse_page(url) 46 47 48 49 def main(): 50 get_page() 51 52 53 if __name__ == '__main__': 54 # 持久化存储 55 if not os.path.exists('H:/乌托家'): 56 os.mkdir('H:/乌托家') 57 main()
划重点了!写XPATH的时候尽量避免class的值有空格的标签!
补充:2019.5.24,今天分别用requests和selenium爬拉勾网,遇到不少问题:
首先是用resquests爬取,如果从首页进去则不用获取JSON数据了,所以不用以下参数 ;如果搜索的话就要获取json数据
其次是用selenium爬取,为什么只能提取两页,第三页就要登录?而且为什么第二页和第一页的信息一样?
1 # Author:K 2 import requests 3 from lxml import etree 4 import re 5 import time 6 import csv 7 8 HEADERS = { 9 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36', 10 # 如果从首页进去则不用获取JSON数据了,所以不用以下参数 ;如果搜索的话就要获取json数据 11 # 'Referer':'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=', 12 # 'Cookie':'JSESSIONID=ABAAABAAAGFABEF23F973C7DA9EFCF4CFE88AB8D87FB58E; _ga=GA1.2.1328313976.1558606630; _gid=GA1.2.1095083654.1558606630; user_trace_token=20190523181726-f6923953-7d43-11e9-a6cf-525400f775ce; LGUID=20190523181726-f6923dac-7d43-11e9-a6cf-525400f775ce; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1558606631; index_location_city=%E5%85%A8%E5%9B%BD; LGSID=20190523223505-f4d6a980-7d67-11e9-a6d0-525400f775ce; TG-TRACK-CODE=index_navigation; _gat=1; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1558624890; X_MIDDLE_TOKEN=9b65220a766ed951ca1a7dbd899dc36b; LGRID=20190523232554-0e6dd7d5-7d6f-11e9-a11a-5254005c3644; X_HTTP_TOKEN=33709e756aaf682260252685512be02aea6a03057c; SEARCH_ID=c0550a07c12045b4879a92a90883b79b', 13 } 14 15 16 # 如果从首页进去则不用获取JSON数据了,所以不用以下参数 ;如果搜索的话就要获取json数据 17 # DATA = { 18 # 'first':'false', 19 # 'pn':'1', 20 # 'kd':'python', 21 # } 22 23 def data_visualization(data): 24 ''' 25 数据可视化 26 :param data: 27 :return: 28 ''' 29 # headers = ['job_name','salary','place','experience','education','job_detail','work_addr'] 30 with open('requests_lagou.csv','a+',encoding = 'utf_8_sig',newline = '') as fp: 31 writer = csv.writer(fp) 32 writer.writerow(data) 33 34 35 36 def parse_page(urls): 37 ''' 38 解析页面 39 :param urls: 40 :return: 41 ''' 42 for url in urls: 43 response = requests.get(url = url,headers = HEADERS,proxies = {'https':'120.234.63.196:3128'}) 44 detail_page_text = response.text 45 tree = etree.HTML(detail_page_text) 46 47 data = [] 48 job_name = tree.xpath('//div[@class="job-name"]/@title')[0] 49 data.append(job_name) 50 salary = tree.xpath('//span[@class="salary"]/text()')[0] 51 data.append(salary) 52 place = tree.xpath('//dd[@class="job_request"]/p[1]/span[2]/text()')[0] 53 place = re.sub(r'[\s/]', '', place) # 将空格和/去掉 54 data.append(place) 55 experience = tree.xpath('//dd[@class="job_request"]/p[1]/span[3]/text()')[0] 56 experience = re.sub(r'[\s/]', '', experience) # 将空格和/去掉 57 data.append(experience) 58 education = tree.xpath('//dd[@class="job_request"]/p[1]/span[4]/text()')[0] 59 education = re.sub(r'[\s/]', '', education) # 将空格和/去掉 60 data.append(education) 61 job_detail = ''.join(tree.xpath('//div[@class="job-detail"]//text()')).strip() 62 # data.append(job_detail) 63 work_addr = ''.join(tree.xpath('//div[@class="work_addr"]//text()')).strip() 64 work_addr = re.sub(r'[\s(查看地图)]', '', work_addr) 65 data.append(work_addr) 66 67 # print(job_name,salary,place,experience,education) 68 # print(job_detail) 69 # print(work_addr) 70 # print(data) 71 # 数据可视化 72 data_visualization(data) 73 print(job_name,'爬取成功!!!') 74 time.sleep(5) 75 76 77 78 def get_page(): 79 ''' 80 得到起始页面 81 :return: 82 ''' 83 # 如果从首页进去则不用获取JSON数据了,所以不用以下参数 ;如果搜索的话就要获取json数据 84 # url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false' 85 url = 'https://www.lagou.com/zhaopin/Python/1/?filterOption=1' 86 response = requests.post(url = url,headers = HEADERS,proxies = {'https':'120.234.63.196:3128'}) 87 page_text = response.text 88 tree = etree.HTML(page_text) 89 detail_urls = tree.xpath('//a[@class="position_link"]/@href') # 得到详情页的url列表 90 parse_page(detail_urls) # 解析详情页 91 92 93 def main(): 94 get_page() 95 96 97 if __name__ == '__main__': 98 main()
1 # Author:K 2 # ------------------------------------为什么只能提取两页,第三页就要登录?而且为什么第二页和第一页的信息一样? 3 from selenium import webdriver 4 from lxml import etree 5 import re 6 from selenium.webdriver.support.ui import WebDriverWait 7 from selenium.webdriver.support import expected_conditions as EC 8 from selenium.webdriver.common.by import By 9 10 class LagouSpider(object): 11 driver_path = r'D:\ChromeDriver\chromedriver.exe' 12 13 def __init__(self): 14 # self.options = webdriver.ChromeOptions() 15 # self.options.add_argument('--proxy-server=http://163.204.247.107:9999') 16 self.driver = webdriver.Chrome(executable_path = self.__class__.driver_path) # chrome_options = self.options 17 self.url = 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=' 18 19 20 def run(self): 21 ''' 22 执行函数 23 :return: 24 ''' 25 self.get_page() 26 27 28 def get_page(self): 29 ''' 30 得到详情页面的源码,将源码作为参数传递给解析页面函数 31 :return: 32 ''' 33 self.driver.get(self.url) # 进入起始页 34 35 self.page = 0 36 while True: 37 tree = etree.HTML(self.driver.page_source) 38 # aTag_list = self.driver.find_elements_by_class_name('position_link') 39 detail_url_list = tree.xpath('//a[@class="position_link"]/@href') # 拿到详情页面的url_list 40 # print(detail_url_list) # 测试 41 for detail_url in detail_url_list: 42 # print(detail_url) # 测试 43 self.driver.execute_script('window.open("%s")' % detail_url) # 利用JS代码打开新的窗口 44 self.driver.switch_to.window(self.driver.window_handles[1]) # 切换到第二个页面中 45 source = self.driver.page_source # 拿到详情页面的源码 46 # print(source) # 测试 47 48 # 在解析页面之前,先等一会儿,确保页面正常打开再解析 49 # WebDriverWait(self.driver,10).until( 50 # EC.presence_of_element_located((By.XPATH,'//div[@class="job-name"]/@title')) 51 # ) 52 53 self.parse_page(source) 54 self.driver.close() # 关闭当前详情页 55 self.driver.switch_to.window(self.driver.window_handles[0]) # 切换回起始页 56 # break # 为了测试,因为循环太多遍不好测试 57 self.page += 1 58 print('===============page %s was over===============' % self.page) 59 60 # 等10秒,直到拿到下一页按钮为止 61 WebDriverWait(self.driver, 10).until( 62 EC.presence_of_element_located((By.XPATH, '//div[@class="pager_container"]/span[last()]')) 63 ) 64 65 next_button = self.driver.find_elements_by_xpath('//div[@class="pager_container"]/span[last()]')[0] # 拿到下一页按钮 66 print(next_button.get_attribute('class')) # 测试 67 if next_button.get_attribute('class') == 'pager_next pager_next_disabled': # 循环结束条件。因为最后一页的下一页按钮按了没有 68 break 69 else: 70 next_button.click() 71 72 73 74 75 def parse_page(self,source): 76 ''' 77 解析详情页面 78 :param source: 79 :return: 80 ''' 81 82 tree = etree.HTML(source) 83 84 data = [] 85 job_name = tree.xpath('//div[@class="job-name"]/@title')[0] 86 data.append(job_name) 87 salary = tree.xpath('//span[@class="salary"]/text()')[0] 88 data.append(salary) 89 place = tree.xpath('//dd[@class="job_request"]/p[1]/span[2]/text()')[0] 90 place = re.sub(r'[\s/]', '', place) # 将空格和/去掉 91 data.append(place) 92 experience = tree.xpath('//dd[@class="job_request"]/p[1]/span[3]/text()')[0] 93 experience = re.sub(r'[\s/]', '', experience) # 将空格和/去掉 94 data.append(experience) 95 education = tree.xpath('//dd[@class="job_request"]/p[1]/span[4]/text()')[0] 96 education = re.sub(r'[\s/]', '', education) # 将空格和/去掉 97 data.append(education) 98 job_detail = ''.join(tree.xpath('//div[@class="job-detail"]//text()')).strip() 99 data.append(job_detail) 100 work_addr = ''.join(tree.xpath('//div[@class="work_addr"]//text()')).strip() 101 work_addr = re.sub(r'[\s(查看地图)]', '', work_addr) 102 data.append(work_addr) 103 104 print(data) 105 106 107 if __name__ == '__main__': 108 spider = LagouSpider() 109 spider.run()
这个案例的问题:爬到第三页的时候就弹出登录页面
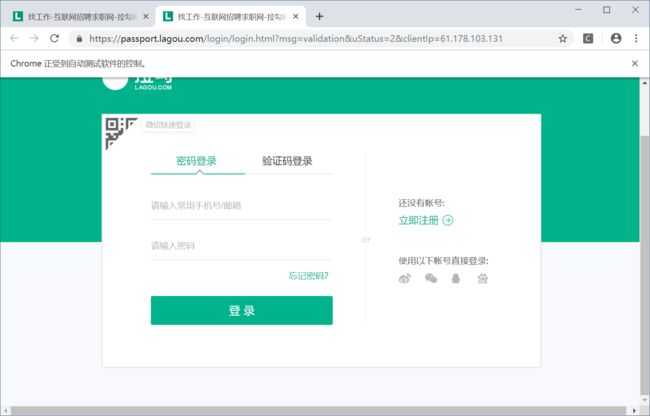
错误是:
job_name = tree.xpath('//div[@class="job-name"]/@title')[0]
IndexError: list index out of range
另外,还用selenium做了一个小案例,就是爬取多多看书的小说。最多只能爬前几十章,不知道为什么到后面就不行了。
1 # Author:K 2 from selenium import webdriver 3 from lxml import etree 4 import re 5 import time 6 from selenium.webdriver.support.ui import WebDriverWait 7 from selenium.webdriver.support import expected_conditions as EC 8 from selenium.webdriver.common.by import By 9 10 driver_path = r'D:\ChromeDriver\chromedriver.exe' 11 12 driver = webdriver.Chrome(executable_path = driver_path) 13 14 15 def parse_page(source): 16 # WebDriverWait(driver,20).until( 17 # EC.presence_of_element_located((By.XPATH,'//div[@id="contentWp"]//text()')) 18 # ) 19 driver.implicitly_wait(100) 20 name = re.findall(r"bname = '(.*?)'", source)[0] # 获取小说名字 21 chapter = re.findall(r'(第.*?)
',source)[0] 22 # print(name,chapter) # 测试 23 tree = etree.HTML(source) 24 content = ''.join(tree.xpath('//div[@id="contentWp"]//text()')).strip() 25 file_path = 'H:/多多看书/' + name + '/' + chapter + '.txt' 26 27 with open(file_path,'w',encoding = 'utf-8') as fp: 28 fp.write(content) 29 30 aTag_button = driver.find_elements_by_class_name('next')[0] 31 32 33 if aTag_button: 34 aTag_button.click() 35 if len(driver.window_handles) > 1: 36 driver.switch_to.window(driver.window_handles[1]) 37 driver.close() 38 driver.switch_to.window(driver.window_handles[0]) 39 time.sleep(3) 40 new_source = driver.page_source 41 return parse_page(new_source) 42 43 44 45 def get_page(url): 46 driver.get(url) 47 close_button = driver.find_element_by_class_name('close') 48 close_button.click() 49 source = driver.page_source 50 # print(source) # 测试 51 parse_page(source) 52 53 54 55 56 def main(): 57 url = 'https://xs.sogou.com/chapter/4579119319_150046829984508/' 58 get_page(url) 59 60 61 if __name__ == '__main__': 62 main()
这个案例的问题:
selenium.common.exceptions.WebDriverException: Message: unknown error: Element 下一章 is not clickable at point (874, 515). Other element would receive the click:
(Session info: chrome=74.0.3729.108)
(Driver info: chromedriver=2.46.628402 (536cd7adbad73a3783fdc2cab92ab2ba7ec361e1),platform=Windows NT 10.0.17134 x86_64)
以后弄懂了回来补充!!!