爬取策略
1.需要安装python selenium模块包,通过selenium中的webdriver驱动浏览器获取Cookie的方法、来达到登录的效果
pip3 install selenium
chromedriver:
下载地址:http://chromedriver.storage.googleapis.com/index.html
chromedriver与chrome的对应关系表
http://blog.csdn.net/huilan_same/article/details/51896672
2.微信公众号登陆地址:https://mp.weixin.qq.com/ ,需要在https://mp.weixin.qq.com/注册一个账户用于登录
3.微信公众号文章接口地址可以在微信公众号后台中新建图文消息,超链接功能中获取:
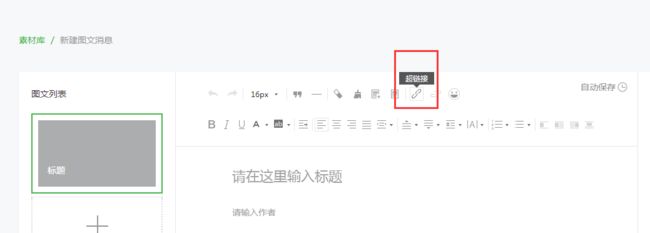

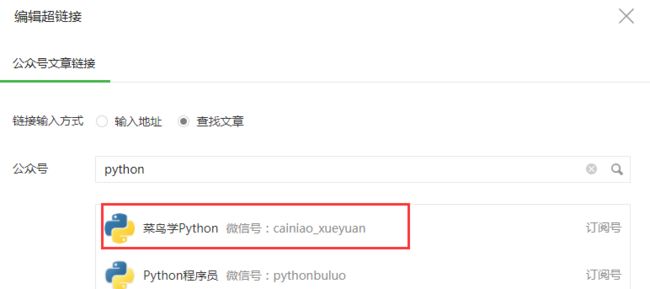
4. 搜索公众号名称
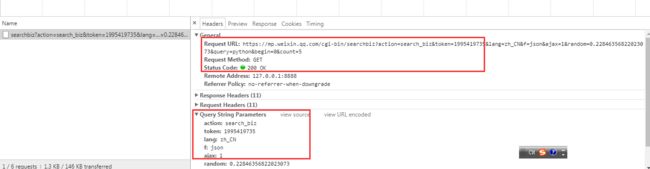
搜索可以获取所有相关的公众号信息,只取第一个做测试
获取要爬取的公众号的fakeid

选定要爬取的公众号,获取文章接口地址
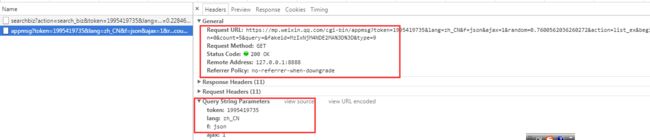
文章列表翻页及内容获取
爬取代码
from selenium import webdriver
import time
import json
import random
import requests
import re
account_name = "xx"
password = "xx"
# 登录微信公众号,获取登录之后的cookies信息,并保存到本地文本中
def wechat_login():
# 用webdriver启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome()
driver.get("https://mp.weixin.qq.com/")
time.sleep(2)
print("正在输入微信公众号登录账号和密码......")
# 清空账号框中的内容
driver.find_element_by_name("account").clear()
driver.find_element_by_name("account").send_keys(account_name)
time.sleep(1)
driver.find_element_by_name("password").clear()
driver.find_element_by_name("password").send_keys(password)
time.sleep(1)
# 在自动输完密码之后需要手动点一下记住我
print("请在登录界面点击:记住账号")
driver.find_element_by_class_name("frm_checkbox_label").click()
time.sleep(5)
# 自动点击登录按钮进行登录
driver.find_element_by_class_name("btn_login").click()
# 拿手机扫二维码!
print("请拿手机扫码二维码登录公众号")
time.sleep(20)
print("登录成功")
cookies = driver.get_cookies()
# 获取cookies
cookie_items = driver.get_cookies()
post = {}
# 获取到的cookies是列表形式,将cookies转成json形式并存入本地名为cookie的文本中
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print("cookies信息已保存到本地")
driver.quit()
# 爬取微信公众号文章,并存在本地文本中
def get_content(query):
# query为要爬取的公众号名称
# 公众号主页
url = 'https://mp.weixin.qq.com'
# 设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
from requests.packages import urllib3
urllib3.disable_warnings() # 关闭警告
# 读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
# 增加重试连接次数
session = requests.Session()
session.keep_alive = False
# 增加重试连接次数
session.adapters.DEFAULT_RETRIES = 511
time.sleep(5)
# 登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-bin/home?t=home/index&lang=zh_CN&token=1849751598,从这里获取token信息
response = session.get(url=url, cookies=cookies, verify=False)
token = re.findall(r'token=(\d+)', str(response.url))[0]
time.sleep(2)
# 搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
# 搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': query,
'begin': '0',
'count': '5'
}
# 打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = session.get(
search_url,
cookies=cookies,
headers=header,
params=query_id)
# 取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
print(lists)
# 获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
# 微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
# 搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0', # 不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
# 打开搜索的微信公众号文章列表页
appmsg_response = session.get(
appmsg_url,
cookies=cookies,
headers=header,
params=query_id_data)
# 获取文章总数
max_num = appmsg_response.json().get('app_msg_cnt')
# 每页至少有5条,获取文章总的页数,爬取时需要分页爬
num = int(int(max_num) / 5)
# 起始页begin参数,往后每页加5
begin = 0
seq = 0
while num + 1 > 0:
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('正在翻页:--------------', begin)
time.sleep(5)
# 获取每一页文章的标题和链接地址,并写入本地文本中
query_fakeid_response = requests.get(
appmsg_url,
cookies=cookies,
headers=header,
params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
if fakeid_list:
for item in fakeid_list:
content_link = item.get('link')
content_title = item.get('title')
fileName = query + '.txt'
seq += 1
with open(fileName, 'a', encoding='utf-8') as fh:
fh.write(
str(seq) +
"|" +
content_title +
"|" +
content_link +
"\n")
num -= 1
begin = int(begin)
begin += 5
if __name__ == '__main__':
# 登录微信公众号,获取登录之后的cookies信息,并保存到本地文本中
wechat_login()
query = "XXX"
print("开始爬取公众号:" + query)
get_content(query)
print("爬取完成")
# #登录之后,通过微信公众号后台提供的微信公众号文章接口爬取文章
# for query in gzlist:
# #爬取微信公众号文章,并存在本地文本中
# print("开始爬取公众号:"+query)
# get_content(query)
# print("爬取完成")