线性回归&梯度下降
什么是线性回归?
学习首先从定义开始,下面是百度百科和维基百科对线性回归的定义:
百度百科
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。
维基百科
线性回归(linear regression)是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。
了解了线性回归的定义,接下来我们再说一下什么是线性、什么是回归?
什么是线性?
线性:自变量之间只存在线性关系,即自变量只能通过相加、或者相减进行组合1
这里我们举一个例子:假设我们要找到变量x、y之间的关系,那我们能进行组合的就只有像 y = a x + b y=ax+b y=ax+b 这样的,我们可以对x,y进行任意加减,但不能进行乘除操作,也就是像 y = a x 2 + b y=ax^2+b y=ax2+b 或者 y 2 = a x + b y^2=ax+b y2=ax+b 就是非线性关系。同理我们可以扩展到变量超过两种的,例如: y = a 1 x 1 + a 2 x 2 + a 3 x 3 . . . a n x n + b y=a_1x_1+a_2x_2+a_3x_3...a_nx_n+b y=a1x1+a2x2+a3x3...anxn+b
下面我们形象的看一下图像:
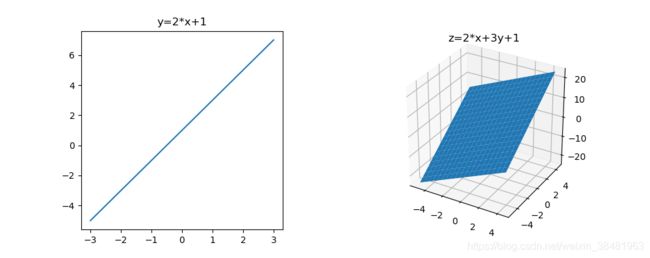
上面左图是二维空间中的两个变量之间的线性关系,是一条直线,右图是三维空间中三个变量之间的线性关系,是一个平面,超过三维则是一个超平面。
什么是回归?
回归:预测连续的变量称为回归。
线性回归的分类?
分为一元线性回归和多元线性回归
如果只包括一个自变量和一个因变量,且二者关系是线性的,称为一元线性回归
如果包括两个及以上自变量,且自变量和因变量关系是线性的,称为多元线性回归
一元线性回归
问题提出:
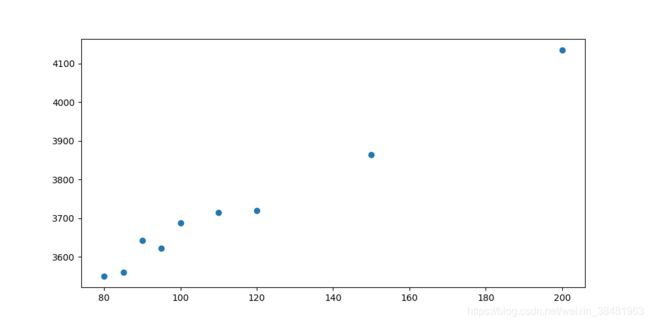
给定一组房屋面积和对应的房价,预测任意房屋面积所对应的房价?
| 房屋面积 | 房价 |
|---|---|
| 80 | 3550 |
| 85 | 3560 |
| 90 | 3642 |
| 95 | 3622 |
| 100 | 3688 |
| 110 | 3714 |
| 120 | 3719 |
| 150 | 3865 |
| 200 | 4135 |
散点图如下:
解:
假设要拟合的函数为 y ^ = w x + b \hat{y} = wx + b y^=wx+b ,既然找到了要拟合的直线,接下来只要确定参数w和b即可。那么如何确定w和b呢?这就需要我们接下来要介绍的内容–损失函数(cost function)。
什么是损失函数?
损失函数可以理解为用来量化真实值与预测值之间差异程度的函数。简单来说,真实值就是我们实际收集到的数据,预测值是用我们的模型估算出的数据。那么估算出的数据跟真实数据越接近,说明我们的模型的可靠程度越高。
损失函数是一类函数,包括平方损失函数、指数损失函数、对数损失函数、绝对值损失函数、0-1损失函数、Hinge损失函数等。
针对线性回归问题,我们使用平方损失函数,下面是这个损失函数的表达形式:
J ( w , b ) = 1 2 ∑ i = 1 n ( y i − y ^ i ) 2 J(w,b)=\frac{1}{2} \sum_{i=1}^{n} (y_i-\hat{y}_i)^2 J(w,b)=21i=1∑n(yi−y^i)2
其中 y i y_i yi 表示真实值, y i ^ \hat{y_i} yi^ 代表给定输入 x i x_i xi 的预测值。将目标函数带入可得:
J ( w , b ) = 1 2 ∑ i = 1 n ( y i − w x i − b ) 2 J(w,b)=\frac{1}{2} \sum_{i=1}^{n} (y_i-wx_i-b)^2 J(w,b)=21i=1∑n(yi−wxi−b)2
于是为了求得w和b,我们只需找到一组w和b使上式最小即可,即:
arg min w , b J ( w , b ) = arg min w , b 1 2 ∑ i = 1 n ( y i − y ^ i ) 2 = arg min w , b 1 2 ∑ i = 1 n ( y i − w x i − b ) 2 \begin{aligned} \underset{w,b}{\operatorname{arg\,min}} J(w,b) &= \underset{w,b}{\operatorname{arg\,min}} \frac{1}{2}\sum_{i=1}^{n} (y_i-\hat{y}_i)^2 \\ &= \underset{w,b}{\operatorname{arg\,min}} \frac{1}{2} \sum_{i=1}^{n} (y_i-wx_i-b)^2 \end{aligned} w,bargminJ(w,b)=w,bargmin21i=1∑n(yi−y^i)2=w,bargmin21i=1∑n(yi−wxi−b)2
注:这个公式前面的常数 1 2 \frac{1}{2} 21 主要是为了求解方便,也有用 1 n \frac{1}{n} n1的还有什么都不加的,不影响最终结果,至于原因,可以从下面推导过程看出来。
接下来是对公式的推导求解过程:
思路:既然是求上述公式的最小值,那么我们只需要找到其最小值点即可,又因其为凸函数,故最小值点必然存在。所以分别对w和b求导,然后另其等于0即可。
∂ J ( w , b ) ∂ w = ∑ i = 1 n ( y i − w x i − b ) x = 0 ∂ J ( w , b ) ∂ b = ∑ i = 1 n ( y i − w x i − b ) = 0 \frac{\partial J(w,b)}{\partial w} = \sum_{i=1}^{n}(y_i-wx_i-b)x = 0 \\ \frac{\partial J(w,b)}{\partial b} = \sum_{i=1}^{n}(y_i-wx_i-b) = 0 ∂w∂J(w,b)=i=1∑n(yi−wxi−b)x=0∂b∂J(w,b)=i=1∑n(yi−wxi−b)=0
从这个公式可以看出,无论前面的非零系数是多少,最终都可以被消去。
先求解第二个公式:
∑ i = 1 n ( y i − w x i − b ) = 0 \sum_{i=1}^{n}(y_i-wx_i-b) = 0 i=1∑n(yi−wxi−b)=0
求得:
b = 1 n ∑ i = 1 n y i − w n ∑ i = 1 n x i b = \frac{1}{n} \sum_{i=1}^{n}y_i - \frac{w}{n}\sum_{i=1}^{n}x_i b=n1i=1∑nyi−nwi=1∑nxi
之后令 x ‾ = 1 n ∑ i = 1 n x i \overline{x} = \frac{1}{n} \sum_{i=1}^{n}x_i x=n1∑i=1nxi , y ‾ = 1 n ∑ i = 1 n y i \overline{y} = \frac{1}{n} \sum_{i=1}^{n}y_i y=n1∑i=1nyi 得到:
b = y ‾ − w x ‾ b = \overline{y} - w\overline{x} b=y−wx
再求解第一个公式:
∑ i = 1 n ( y i − w x i − b ) x = 0 \sum_{i=1}^{n}(y_i-wx_i-b)x = 0 i=1∑n(yi−wxi−b)x=0
将之前求得的b带入这个公式,可求得w:
w = ∑ i = 1 n x i y i − y ‾ ∑ i = 1 n x i ∑ i = 1 n x i 2 − x ‾ ∑ i = 1 n x i = ∑ i = 1 n x i y i − 1 n ∑ i = 1 n y i ∑ i = 1 n x i ∑ i = 1 n x i 2 − 1 n ∑ i = 1 n x i ∑ i = 1 n x i = ∑ i = 1 n ( x i − x ‾ ) ( y i − y ‾ ) ∑ i = 1 n ( x i − x ‾ ) 2 \begin{aligned} w &= \frac{\sum_{i=1}^{n}x_iy_i - \overline{y}\sum_{i=1}^{n}x_i}{\sum_{i=1}^{n}x_i^2-\overline{x}\sum_{i=1}^{n}x_i} \\ &= \frac{\sum_{i=1}^{n}x_iy_i - \frac{1}{n}\sum_{i=1}^{n}y_i\sum_{i=1}^{n}x_i}{\sum_{i=1}^{n}x_i^2-\frac{1}{n}\sum_{i=1}^{n}x_i\sum_{i=1}^{n}x_i} \\ &=\frac{\sum_{i=1}^{n}(x_i-\overline{x})(y_i-\overline{y})}{\sum_{i=1}^{n}(x_i-\overline{x})^2} \end{aligned} w=∑i=1nxi2−x∑i=1nxi∑i=1nxiyi−y∑i=1nxi=∑i=1nxi2−n1∑i=1nxi∑i=1nxi∑i=1nxiyi−n1∑i=1nyi∑i=1nxi=∑i=1n(xi−x)2∑i=1n(xi−x)(yi−y)
上述推导的最后两个步骤,是下述公式转换得到的:
∑ i = 1 n x i y i − 1 n ∑ i = 1 n y i ∑ i = 1 n x i = ∑ i = 1 n ( x i − x ‾ ) ( y i − y ‾ ) ∑ i = 1 n x i 2 − 1 n ∑ i = 1 n x i ∑ i = 1 n x i = ∑ i = 1 n ( x i − x ‾ ) 2 \sum_{i=1}^{n}x_iy_i - \frac{1}{n}\sum_{i=1}^{n}y_i\sum_{i=1}^{n}x_i = \sum_{i=1}^{n}(x_i-\overline{x})(y_i-\overline{y}) \\ \sum_{i=1}^{n}x_i^2-\frac{1}{n}\sum_{i=1}^{n}x_i\sum_{i=1}^{n}x_i=\sum_{i=1}^{n}(x_i-\overline{x})^2 i=1∑nxiyi−n1i=1∑nyii=1∑nxi=i=1∑n(xi−x)(yi−y)i=1∑nxi2−n1i=1∑nxii=1∑nxi=i=1∑n(xi−x)2
上面的公式可以通过右边推导得到左边来证明其正确性。
∑ i = 1 n ( x i − x ‾ ) ( y i − y ‾ ) = ∑ i = 1 n ( x i y i − x i y ‾ − x ‾ y i + x ‾ y ‾ ) = ∑ i = 1 n ( x i y i ) − ∑ i = 1 n x i 1 n ∑ i = 1 n y i − 1 n ∑ i = 1 n x i ∑ i = 1 n y i + ∑ i = 1 n ( 1 n 2 ∑ i = 1 n x i ∑ i = 1 n y i ) = ∑ i = 1 n x i y i − 1 n ∑ i = 1 n y i ∑ i = 1 n x i \begin{aligned} &\sum_{i=1}^{n}(x_i-\overline{x})(y_i-\overline{y}) \\ &= \sum_{i=1}^{n}(x_iy_i-x_i\overline{y}-\overline{x}y_i+\overline{x}\overline{y}) \\ &= \sum_{i=1}^{n}(x_iy_i) - \sum_{i=1}^{n}x_i\frac{1}{n}\sum_{i=1}^{n}y_i - \frac{1}{n}\sum_{i=1}^{n}x_i\sum_{i=1}^{n}y_i + \sum_{i=1}^{n}(\frac{1}{n^2}\sum_{i=1}^{n}x_i\sum_{i=1}^{n}y_i) \\ &=\sum_{i=1}^{n}x_iy_i - \frac{1}{n}\sum_{i=1}^{n}y_i\sum_{i=1}^{n}x_i \end{aligned} i=1∑n(xi−x)(yi−y)=i=1∑n(xiyi−xiy−xyi+xy)=i=1∑n(xiyi)−i=1∑nxin1i=1∑nyi−n1i=1∑nxii=1∑nyi+i=1∑n(n21i=1∑nxii=1∑nyi)=i=1∑nxiyi−n1i=1∑nyii=1∑nxi
这里需要注意的是 ∑ i = 1 n x i \sum_{i=1}^{n}x_i ∑i=1nxi 跟 ∑ i = 1 n y i \sum_{i=1}^{n}y_i ∑i=1nyi 都是常数,因为他们的值一开始就是已知的。
∑ i = 1 n ( x i − x ‾ ) 2 = ∑ i = 1 n ( x i 2 − 2 x i x ‾ + x ‾ 2 ) = ∑ i = 1 n x i 2 − 2 ∑ i = 1 n x i 1 n ∑ i = 1 n x i + ∑ i = 1 n ( 1 n 2 ∑ i = 1 n x i ∑ i = 1 n x i ) = ∑ i = 1 n x i 2 − 1 n ∑ i = 1 n x i ∑ i = 1 n x i \begin{aligned} \sum_{i=1}^{n}(x_i-\overline{x})^2 &= \sum_{i=1}^{n}(x_i^2-2x_i\overline{x}+\overline{x}^2) \\ &= \sum_{i=1}^{n}x_i^2 - 2\sum_{i=1}^{n}x_i\frac{1}{n}\sum_{i=1}^{n}x_i + \sum_{i=1}^{n}(\frac{1}{n^2}\sum_{i=1}^{n}x_i\sum_{i=1}^{n}x_i) \\ &= \sum_{i=1}^{n}x_i^2-\frac{1}{n}\sum_{i=1}^{n}x_i\sum_{i=1}^{n}x_i \end{aligned} i=1∑n(xi−x)2=i=1∑n(xi2−2xix+x2)=i=1∑nxi2−2i=1∑nxin1i=1∑nxi+i=1∑n(n21i=1∑nxii=1∑nxi)=i=1∑nxi2−n1i=1∑nxii=1∑nxi
最后将w带入可求得b:
b = y ‾ − ∑ i = 1 n ( x i − x ‾ ) ( y i − y ‾ ) ∑ i = 1 n ( x i − x ‾ ) 2 x ‾ b = \overline{y} - \frac{\sum_{i=1}^{n}(x_i-\overline{x})(y_i-\overline{y})}{\sum_{i=1}^{n}(x_i-\overline{x})^2}\overline{x} b=y−∑i=1n(xi−x)2∑i=1n(xi−x)(yi−y)x
有了w和b,代入 y ^ = w x + b \hat{y} = wx + b y^=wx+b ,便得到了房价的预测函数。
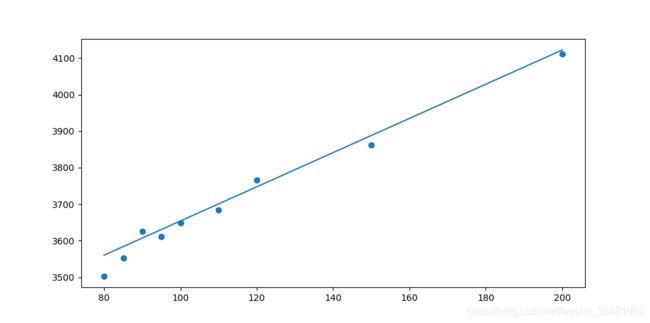
这里我们可以计算一下,根据上述数据,带入公式可求得 w = 4.676743097800655 , b = 3186.4394010294805 w=4.676743097800655,b=3186.4394010294805 w=4.676743097800655,b=3186.4394010294805 .画出图像如下图:
多元线性回归
一元线性回归问题比较简单,只包含两个变量,只需要将数据带入公式就可以直接求出回归方程。接下来介绍涉及两个以上线性回归问题的求解思路,即多元线性回归问题。
这里我们假设有n个样本,每个样本有m个属性,以房价为例:我们获取了n条房价信息,但是影响房价的因素不止房屋面积这一条,还可能包含房子到市中心的距离(北京几环),房子到学校的距离(学区房),房屋的配置(几室几厅)、是否有阳台、是否装修、装修程度、是否包含家具等因素。假设影响因素为 ( x 1 , x 2 , . . . x m ) (x_1,x_2,...x_m) (x1,x2,...xm) 共m个,于是我们要找的便是这m个影响因素 ( x 1 , x 2 , . . . x m ) (x_1,x_2,...x_m) (x1,x2,...xm) 跟房价 y y y 之间的关系(注:这里仅是以房价预测作为例子以便于理解)。
因此,多元线性回归方程可写为如下形式:
y ^ ( i ) = w 0 + w 1 x 1 ( i ) + w 2 x 2 ( i ) + w 3 x 3 ( i ) + . . . + w n x n ( i ) \hat{y}^{(i)}=w_0+ w_1x_1^{(i)} + w_2x_2^{(i)} + w_3x_3^{(i)} +...+w_nx_n^{(i)} y^(i)=w0+w1x1(i)+w2x2(i)+w3x3(i)+...+wnxn(i)
其中 x j i x_j^i xji ,i代表第i个样本,j代表样本的第j个属性。
为了简化表示,同时也为了方便计算,我们用矩阵对上述形式进行转换:
令:
Y = [ y 1 y 2 y 3 . . . y n ] X = [ 1 x 1 ( 1 ) x 2 ( 1 ) . . . x m ( 1 ) 1 x 1 ( 2 ) x 2 ( 2 ) . . . x m ( 2 ) 1 x 1 ( 3 ) x 2 ( 3 ) . . . x m ( 3 ) . . . . . . . . . . . . . . . 1 x 1 ( n ) x 2 ( n ) . . . x m ( n ) ] W = [ w 0 w 1 w 2 . . . w m ] Y = \left[ \begin{matrix} y_1 \\ y_2 \\ y_3 \\ ... \\ y_n \end{matrix} \right] X=\left[\begin{matrix} 1 & x_1^{(1)} & x_2^{(1)} & ... &x_m^{(1)} \\ 1 & x_1^{(2)} & x_2^{(2)} & ... & x_m^{(2)} \\ 1 & x_1^{(3)} & x_2^{(3)} & ... & x_m^{(3)} \\ ... & ... & ... & ... & ... \\ 1 & x_1^{(n)} & x_2^{(n)} & ... & x_m^{(n)} \\ \end{matrix}\right] W=\left[\begin{matrix} w_0 \\ w_1 \\ w_2 \\ ... \\w_m \end{matrix}\right] Y=⎣⎢⎢⎢⎢⎡y1y2y3...yn⎦⎥⎥⎥⎥⎤X=⎣⎢⎢⎢⎢⎢⎡111...1x1(1)x1(2)x1(3)...x1(n)x2(1)x2(2)x2(3)...x2(n)...............xm(1)xm(2)xm(3)...xm(n)⎦⎥⎥⎥⎥⎥⎤W=⎣⎢⎢⎢⎢⎡w0w1w2...wm⎦⎥⎥⎥⎥⎤
其中, Y Y Y 矩阵每一行代表一个房价信息,共n行,需要注意的是这个是实际的房价,不是预测的房价; X X X 矩阵每一行代表一条样本数据(影响房价的属性),同样是n行; W W W 矩阵则是对应影响房价属性的权值。 X X X 和 Y Y Y 矩阵代表了我们的收集的所有样本数据。
于是可以将要求得的多元线性回归方程简化表示为:
y ^ = X W \hat{y}=XW y^=XW
于是我们可以用下面的形式表示损失函数:
J ( W ) = 1 2 ( Y − X W ) T ( Y − X W ) J(W) = \frac{1}{2}(Y-XW)^T(Y-XW) J(W)=21(Y−XW)T(Y−XW)
顺带一提,之所以能代替 1 2 ∑ i = 1 n ( y i − y ^ i ) 2 \frac{1}{2}\sum_{i=1}^{n} (y_i-\hat{y}_i)^2 21∑i=1n(yi−y^i)2,是因为Y和X矩阵中已经包含了所有的样本数据,不需要再逐条样本求和。
接下来对其化简求导,并令其等于0,即可求得权重矩阵W。
J ( W ) = 1 2 ( Y − X W ) T ( Y − X W ) = 1 2 ( Y T − ( X W ) T ) ( Y − X W ) = 1 2 ( Y T Y − Y T X W − ( X W ) T Y + ( X W ) T X W ) = 1 2 Y T Y − Y T X W + 1 2 W T X T X W \begin{aligned} J(W) &= \frac{1}{2}(Y-XW)^T(Y-XW) \\ &= \frac{1}{2}(Y^T-(XW)^T)(Y-XW) \\ &= \frac{1}{2}(Y^TY-Y^TXW-(XW)^TY+(XW)^TXW) \\ &= \frac{1}{2}Y^TY-Y^TXW + \frac{1}{2}W^TX^TXW \end{aligned} \\ J(W)=21(Y−XW)T(Y−XW)=21(YT−(XW)T)(Y−XW)=21(YTY−YTXW−(XW)TY+(XW)TXW)=21YTY−YTXW+21WTXTXW
根据求导公式:
∂ A x ∂ x = A T ∂ x T A x ∂ x = ( A + A T ) x \begin{aligned} & \frac{\partial{Ax}}{\partial{x}} = A^T \\ & \frac{\partial{x^TAx}}{\partial{x}} = (A+A^T)x \end{aligned} ∂x∂Ax=AT∂x∂xTAx=(A+AT)x
对其求导可得:
∂ J ( W ) ∂ W = − X T Y + X T X W \frac{\partial J(W)}{\partial W} = -X^TY+X^TXW ∂W∂J(W)=−XTY+XTXW
令其等于0可求得:
W = ( X T X ) − 1 X T Y W = (X^TX)^{-1}X^TY W=(XTX)−1XTY
到这一步已经求得权重矩阵W,但是需要讨论一下:结果中用到了矩阵的逆,但是无法保证在所有情况下 X T X X^TX XTX 是满秩矩阵,因此无法求得唯一的解。
解决办法:对原始数据进行特征筛选或者正则化。(这一块也有一些问题)
为什么正则化之后解就是唯一的了?
以上是用正规方程的方式进行求解,使用正规方程的形式可以直接进行求解,但是也有其不足之处,如果数据量巨大,比如上百万条数据,还是用矩阵进行计算的话,复杂度过高。下面我们引入另一种解决方案–梯度下降法
梯度下降
什么是梯度?
梯度是一个向量,沿梯度方向函数增长速度最快。
如何求梯度?
g r a d f ( x 0 , x 1 , . . . x n ) = ( ∂ f ∂ x 0 , ∂ f ∂ x 1 , ∂ f ∂ x 2 , . . . , ∂ f ∂ x n ) gradf(x_0,x_1,...x_n)=(\frac{\partial{f}}{\partial{x_0}},\frac{\partial{f}}{\partial{x_1}},\frac{\partial{f}}{\partial{x_2}},...,\frac{\partial{f}}{\partial{x_n}}) gradf(x0,x1,...xn)=(∂x0∂f,∂x1∂f,∂x2∂f,...,∂xn∂f)
什么是梯度下降?
梯度下降是迭代算法的一种,通过一步步的迭代来找到损失函数的最小值。前面我们提到梯度方向是函数增长速度最快的方向,那么我们只要沿梯度反方向走就可以找到函数的最小值(也可能是局部最小值)。
梯度下降算法可以用下面公式表示:
r e p e a t u n t i l c o v e r a g g e { w 0 = w 0 − α ∂ J ( w 0 , w 1 , w 2 , . . . w n ) ∂ w 0 w 1 = w 1 − α ∂ J ( w 0 , w 1 , w 2 , . . . w n ) ∂ w 1 w 2 = w 2 − α ∂ J ( w 0 , w 1 , w 2 , . . . w n ) ∂ w 2 . . . w n = w n − α ∂ J ( w 0 , w 1 , w 2 , . . . w n ) ∂ w n } \begin{aligned} & repeat \quad until \quad coveragge \{\\ & w_0 = w_0 - \alpha \frac{\partial{J(w_0, w_1, w_2, ...w_n)}}{\partial{w_0}} \\ & w_1 = w_1 - \alpha \frac{\partial{J(w_0, w_1, w_2, ...w_n)}}{\partial{w_1}} \\ & w_2 = w_2 - \alpha \frac{\partial{J(w_0, w_1, w_2, ...w_n)}}{\partial{w_2}} \\ & ... \\ & w_n = w_n - \alpha \frac{\partial{J(w_0, w_1, w_2, ...w_n)}}{\partial{w_n}} \\ \\ \} \end{aligned} }repeatuntilcoveragge{w0=w0−α∂w0∂J(w0,w1,w2,...wn)w1=w1−α∂w1∂J(w0,w1,w2,...wn)w2=w2−α∂w2∂J(w0,w1,w2,...wn)...wn=wn−α∂wn∂J(w0,w1,w2,...wn)
简化表示为:
r e p e a t u n t i l c o v e r a g e { w i = w i − α ∂ J ( w 0 , w 1 , w 2 , . . . w n ) ∂ w i } \begin{aligned} &repeat \quad until \quad coverage \{ \\ &w_i = w_i - \alpha \frac{\partial{J(w_0, w_1, w_2, ...w_n)}}{\partial{w_i}} \\ \} \end{aligned} }repeatuntilcoverage{wi=wi−α∂wi∂J(w0,w1,w2,...wn)
其中 w 0 , w 1 , . . . w n w_0,w_1,...w_n w0,w1,...wn 是待更新的权重,也是我们梯度下降算法要求得的值; α \alpha α 代表学习率,决定梯度下降的快慢。
如何形象的理解?
以 y = 0.5 x 2 + 1 y=0.5 x ^2+1 y=0.5x2+1 的图像为例,理解梯度下降算法。
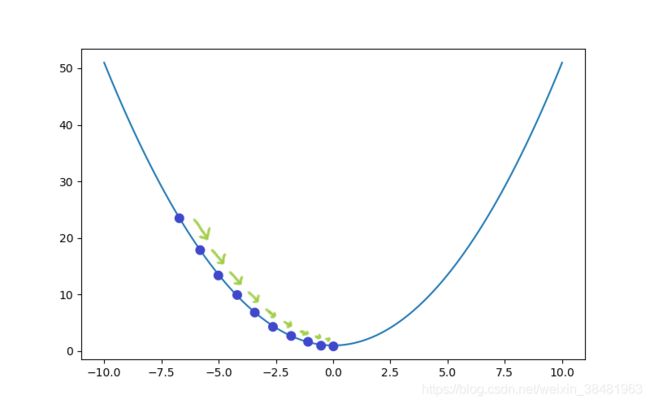
首先选取一个随机的x值,为了便于计算,我们选择 x = − 4 x=-4 x=−4 , α = 0.5 \alpha=0.5 α=0.5。确定了初始的点,接下来我们就根据这个初始点找到函数的最小值。
(1)第1次迭代:
x = x − α ∂ y ∂ x = − 4 − 0.5 ∗ ( − 4 ) = − 2 x = x - \alpha \frac{\partial{y}}{\partial{x}}=-4-0.5*(-4)=-2 x=x−α∂x∂y=−4−0.5∗(−4)=−2
(2)第2次迭代:
x = x − α ∂ y ∂ x = − 2 − 0.5 ∗ ( − 2 ) = − 1 x = x - \alpha \frac{\partial{y}}{\partial{x}}=-2-0.5*(-2)=-1 x=x−α∂x∂y=−2−0.5∗(−2)=−1
(3)第3次迭代:
x = x − α ∂ y ∂ x = − 1 − 0.5 ∗ ( − 1 ) = − 0.5 x = x - \alpha \frac{\partial{y}}{\partial{x}}=-1-0.5*(-1)=-0.5 x=x−α∂x∂y=−1−0.5∗(−1)=−0.5
…
(15) 第15次迭代:
x = x − α ∂ y ∂ x = − 0.0001220703125 x = x - \alpha \frac{\partial{y}}{\partial{x}}=-0.0001220703125 x=x−α∂x∂y=−0.0001220703125
很明显,才经过15次迭代, x x x 就已经十分接近函数的最低点0了。
为什么这种方法可以找到函数的最低点?
首先看公式中的求导部分 ∂ J ( w 0 , w 1 , w 2 , . . . w n ) ∂ w i \frac{\partial{J(w_0, w_1, w_2, ...w_n)}}{\partial{w_i}} ∂wi∂J(w0,w1,w2,...wn) ,它代表的是函数在该点的切线斜率,如果是正斜率,为了找到最小值,需要向左移动,用原来的值减去要移动的距离( α \alpha α 乘上正斜率);如果是负斜率,那么为了找到最小值,需要向右移动,用原来的值加上要移动的距离,但是因为 α \alpha α 乘负斜率结果是负值,所以还是要减去这个值。因此 x x x 的更新步骤是 w i − α ∂ J ( w 0 , w 1 , w 2 , . . . w n ) ∂ w i ( i = 0 , 1 , 2... n ) w_i - \alpha \frac{\partial{J(w_0, w_1, w_2, ...w_n)}}{\partial{w_i}} (i=0,1,2...n) wi−α∂wi∂J(w0,w1,w2,...wn)(i=0,1,2...n) 。可以结合下图进行理解,在A点斜率为正,需要向左移动;在B点斜率为负,需要向右移动。
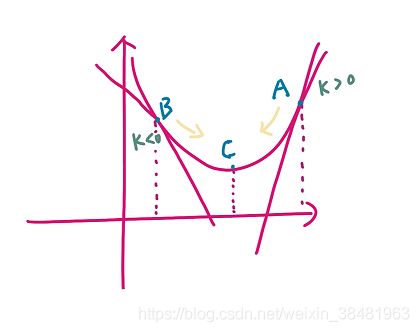
这里 α \alpha α 的作用是什么?
α \alpha α 代表学习率,它决定了沿函数下降速度最快方向能够移动的距离有多大。
如果 α \alpha α 过大,就会导致移动的时候越过最低点,甚至可能无法收敛;
如果 α \alpha α 过小,就会导致每次移动的距离很小,需要迭代更多次才能到达最低点;
从公式上看,斜率更重要的作用是指明了移动的方向,那么是否可以只保留方向而将斜率值换成其他值呢?
这里我们假设将斜率值换成一个常数a,如果a值比较小,那么我们要达到最低点需要更多的迭代步数(值越小,需要迭代的次数越多);如果a值比较大,就可能导致在原点左右无限摆动,而无法收敛到原点。显然替换成常数是不合适的。
既然常数不合适,那么使用斜率又有什么好处呢?
使用斜率的最大好处是它是变化的。最初的时候斜率比较大,每更新一步,移动的也距离比较大,可以快速接近函数最小值点;随着x值越来越接近最小值,斜率也无限趋近于0,因此更新的时候,移动的距离就会非常小,可以防止越过最小值点;
再以一个三维图像为例,理解梯度下降算法:
下图是函数 z = x 2 + y 2 z=x^2+y^2 z=x2+y2 在三维坐标系中的图像。
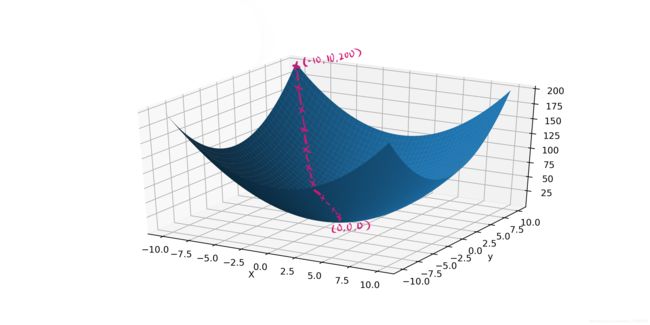
这里以 x = − 10 , y = 10 x=-10, y=10 x=−10,y=10 为起点, α = 0.1 \alpha=0.1 α=0.1 ,进行梯度下降求最小值;
(1)第1次迭代:
x = x − α ∂ z x = − 10 − 0.1 ∗ ( − 20 ) = − 8 y = y − α ∂ z y = 10 − 0.1 ∗ 20 = 8 \begin{aligned} & x = x-\alpha \frac{\partial{z}}{x} = -10 - 0.1*(-20) = -8 \\ & y = y-\alpha \frac{\partial{z}}{y} = 10 - 0.1*20 = 8 \end{aligned} x=x−αx∂z=−10−0.1∗(−20)=−8y=y−αy∂z=10−0.1∗20=8
(2)第2次迭代:
x = x − α ∂ z x = − 8 − 0.1 ∗ ( − 16 ) = − 6.4 y = y − α ∂ z y = 8 − 0.1 ∗ 16 = 6.4 \begin{aligned} & x = x-\alpha \frac{\partial{z}}{x} = -8 - 0.1*(-16) = -6.4 \\ & y = y-\alpha \frac{\partial{z}}{y} = 8 - 0.1*16 = 6.4 \end{aligned} x=x−αx∂z=−8−0.1∗(−16)=−6.4y=y−αy∂z=8−0.1∗16=6.4
(3)第3次迭代:
x = x − α ∂ z x = − 6.4 − 0.1 ∗ ( − 12.8 ) = − 5.12 y = y − α ∂ z y = 6.4 − 0.1 ∗ 12.8 = 5.12 \begin{aligned} & x = x-\alpha \frac{\partial{z}}{x} = -6.4 - 0.1*(-12.8) = -5.12 \\ & y = y-\alpha \frac{\partial{z}}{y} = 6.4 - 0.1*12.8 = 5.12 \end{aligned} x=x−αx∂z=−6.4−0.1∗(−12.8)=−5.12y=y−αy∂z=6.4−0.1∗12.8=5.12
…
(4)第51次迭代:
x = x − α ∂ z x = − 6.4 − 0.1 ∗ ( − 12.8 ) = − 0.00011417981541647683 y = y − α ∂ z y = 6.4 − 0.1 ∗ 12.8 = 0.00011417981541647683 \begin{aligned} & x = x-\alpha \frac{\partial{z}}{x} = -6.4 - 0.1*(-12.8) = -0.00011417981541647683 \\ & y = y-\alpha \frac{\partial{z}}{y} = 6.4 - 0.1*12.8 = 0.00011417981541647683 \end{aligned} x=x−αx∂z=−6.4−0.1∗(−12.8)=−0.00011417981541647683y=y−αy∂z=6.4−0.1∗12.8=0.00011417981541647683
经过51次迭代后也接近最小值点(0,0,0)了,只要无限迭代下去,就可以无限接近于0,而我们只需要取到某一精度即可。
我们还可以比较一下 α \alpha α 对迭代次数的影响,我们这次选择的 α = 0.2 \alpha = 0.2 α=0.2 迭代51次才接近最低点,如果选择 α = 0.5 \alpha = 0.5 α=0.5 ,我们只需要迭代一次就可以到达最低点。因此选择合适的 α \alpha α 可以省去很多迭代步骤。
参考:
【1】 【从入门到放弃】线性回归
【2】 小白入门线性回归:原理+代码
【3】线性回归与最小二乘法
【4】[机器学习] ML重要概念:梯度(Gradient)与梯度下降法(Gradient Descent)
【5】梯度下降算法原理讲解——机器学习