redis集群的创建
实验环境
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。
Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误。
Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令. Redis 集群的优势:
- 自动分割数据到不同的节点上。
- 整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
如果电脑内存较小的可进行如下设置:
overcomit_memory 参数有三个值:0,1,2。
| 数值 | 含义 |
|---|---|
| 0 | 用户申请内存的时候,系统会判断剩余的内存多少,如果不够的话那么就会失败。 |
| 1 | 用户申请内存的时候,系统不进行任何检查任务内存足够用,直到使用内存超过可用内存。 |
| 2 | 用户一次申请的内存大小不允许超过可用内存的大小。 |
为实验过程中不出现报错,我们将此参数设置为1.
[root@sever1~]# sysctl vm.overcommit_memory #查看参数
vm.overcommit_memory = 0
[root@server1 ~]# sysctl -w vm.overcommit_memory=1 #设置参数
vm.overcommit_memory = 1
一、创建集群目录并配置文件
[root@server1 ~]# mkdir /usr/local/rediscluster
[root@server1 ~]# cd /usr/local/rediscluster/
[root@server1 rediscluster]# mkdir 700{1..6}
[root@server1 rediscluster]# cd 7001/
[root@server1 7001]# vim redis.conf
port 7001
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
pidfile "/usr/local/rediscluster/7001/redis.pid"
logfile "/usr/local/rediscluster/7001/redis.log"
daemonize yes
dir "/usr/local/rediscluster/7001"
[root@server1 7001]# cp redis.conf ../7002/(修改成对应的端口号)
[root@server1 7001]# cp redis.conf ../7003/
[root@server1 7001]# cp redis.conf ../7004/
[root@server1 7001]# cp redis.conf ../7005/
[root@server1 7001]# cp redis.conf ../7006/
二、打开每一个端口
其余端口与其打开方法相同[root@server1 7003]# redis-server redis.conf
[root@server1 7003]# redis-cli -p 7003
127.0.0.1:7003> quit
三、创建集群
[root@server1 7006]# redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006
这个命令在这里用于创建一个新的集群, 选项–replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
之后跟着的其他参数则是这个集群实例的地址列表,3个master3个slave redis-trib 会打印出一份预想中的配置给你看, 如果你觉得没问题的话, 就可以输入 yes , redis-trib 就会将这份配置应用到集群当中,让各个节点开始互相通讯。
测试集群


查看日志
[root@server1 7002]# cat appendonly.aof
*2
$6
SELECT
$1
0
*3
$3
set
$4
name
$6
redhat
查看主从关系
如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了。不过当B和B1 都失败后,集群是不可用的.
关闭一个slave
[root@server1 7006]# redis-cli -c -p 7004
127.0.0.1:7004> shutdown
not connected> quit

如果再关闭7002,最后一行消失。
如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,因为集群的slot映射[0-16383]不完整,集群进入fail状态。
四、为集群添加节点
[root@server1 7004]# redis-server redis.conf (打开7004)

创建新节点目录与编辑配置文件
[root@server1 7002]# mkdir ../7007
[root@server1 7002]# cp redis.conf ../7007
[root@server1 7002]# vim ../7007/redis.conf (文件中的端口号改为7007)
[root@server1 7007]# redis-server redis.conf
添加新节点:
[root@server1 7007]# redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001
可以看到.使用add-node命令来添加节点,第一个参数是新节点的地址,第二个参数是任意一个已经存在的节点的IP和端口。

再添加一个slave节点
[root@server1 7007]# mkdir ../7008
[root@server1 7007]# cp redis.conf ../7008
[root@server1 7007]# cd ../7008
[root@server1 7008]# vi redis.conf
此命令中的id是作为7008master的节点对应的id。如果不指出id,集群会任意添加给某个master。
[root@server1 7008]# redis-cli --cluster add-node --cluster-slave --cluster-master-id "25808d63494d3fd16b20590134e41d0a4eb499cc" 127.0.0.1:7008 127.0.0.1:7007

但是我们可以从上图看到新的master节点127.0.0.1:7007没有分到slots。
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
节点 A 包含 0 到 5500号哈希槽.
节点 B 包含5501 到 11000 号哈希槽.
节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
五、为新添加的节点分配哈希槽
[root@server1 7001]# redis-cli --cluster rebalance --cluster-threshold 1 --cluster-use-empty-masters 127.0.0.1:7001
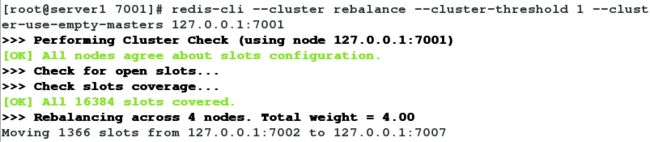
此时,可以看到哈希槽分布均匀。
