OpenCV官方教程中文版——学习笔记(三)
23 图像变换
23.1 傅里叶变换
傅里叶变换经常被用来分析不同滤波器的频率特性。我们可以使用 2D 离散傅里叶变换 (DFT) 分析图像的频域特性。实现 DFT 的一个快速算法被称为快速傅里叶变换(FFT)
可以把图像想象成沿着两个方向采集的信号。所以对图像同时进行 X 方向和 Y 方向的傅里叶变换,我们就会得到这幅图像的频域表示(频谱图)。
更直观一点,对于一个正弦信号,如果它的幅度变化非常快,我们可以说他是高频信号,如果变化非常慢,我们称之为低频信号。
把这种想法应用到图像中,图像哪里的幅度变化非常大呢?边界点或者噪声。所以我们说边界和噪声是图像中的高频分量(注意这里的高频是指变化非常快,而非出现的次数多)。如果没有如此大的幅度变化我们称之为低频分量。
23.1.1 Numpy 中的傅里叶变换
Numpy 中的 FFT 包可以帮助我们实现快速傅里叶变换。
np.fft.fft2() 可以对信号进行频率转换,输出结果是一个复杂的数组。
该函数的第一个参数是输入图像,要求是灰度格式。第二个参数是可选的, 决定输出数组的大小。输出数组的大小和输入图像大小一样。如果输出结果比输入图像大,输入图像就需要在进行 FFT 前补0。如果输出结果比输入图像小的话,输入图像就会被切割。
现在得到了结果, 频率为 0 的部分(直流分量)在输出图像的左上角。如果想让它(直流分量)在输出图像的中心,还需要将结果沿两个方向平移 N/2 。 函数 np.fft.fftshift() 可以帮助我们实现这一步。(这样更容易分析)。进行完频率变换之后,就可以构建振幅谱了。
现在可以进行频域变换:在频域对图像进行一些操作,例如高通滤波和重建图像(DFT 的逆变换)。比如可以使用一个60x60 的矩形窗口对图像进行掩模操作从而去除低频分量。然后再使用函数np.fft.ifftshift() 进行逆平移操作,所以现在直流分量又回到左上角了,之后使用函数 np.ifft2()进行 FFT 逆变换。同样又得到一堆复杂的数字,可以对他们取绝对值。
23.1.2 OpenCV 中的傅里叶变换
cv2.dft() 和 cv2.idft()
和前面输出的结果一样,但是是双通道的。第一个通道是结果的实数部分,第二个通道是结果的虚数部分。输入图像要首先转换成np.float32
可以使用函数 cv2.cartToPolar()同时返回幅度和相位。
现在来做逆 DFT。在前面的部分实现了 HPF(高通滤波),现在来做 LPF(低通滤波)将高频部分去除。其实就是对图像进行模糊操作。首先需要构建一个掩模,与低频区域对应的地方设置为 1, 与高频区域对应的地方设置为 0。
注意: OpenCV 中的函数 cv2.dft() 和 cv2.idft() 要比 Numpy 快。但是Numpy 函数更加用户友好。
23.1.3 DFT 的性能优化
当数组的大小为某些值时 DFT 的性能会更好。
当数组的大小是 2 的指数时 DFT 效率最高。当数组的大小是 2, 3, 5 的倍数时效率也会很高。所以如果你想提高代码的运行效率时,你可以修改输入图像的大小(补 0)。对于OpenCV 你必须自己手动补 0。但是 Numpy,你只需要指定 FFT 运算的大小,它会自动补 0。
那怎样确定最佳大小呢?OpenCV 提供了一个函数:cv2.getOptimalDFTSize()。它可以同时被 cv2.dft() 和 np.fft.fft2() 使用。
23.1.4 为什么拉普拉斯算子是高通滤波器?
对不同的算子进行傅里叶变换并分析它们:
为什么 Sobel 是 HPF?
24 模板匹配
使用模板匹配在一幅图像中查找目标
模板匹配是用来在一大图中搜寻查找模版图像位置的方法。
OpenCV 为我们提供了函数: cv2.matchTemplate()。和 2D 卷积一样,它也是用模板图像在输入图像(大图)上滑动,并在每一个位置对模板图像和与其对应的输入图像的子区域进行比较。 返回的结果是一个灰度图像,每一个像素值表示了此区域与模板的匹配程度。
如果输入图像的大小是(WxH),模板的大小是(wxh),输出的结果的大小就是(W-w+1, H-h+1)。
当你得到这幅图之后,就可以使用函数cv2.minMaxLoc() 来找到其中的最小值和最大值的位置了。第一个值为矩形左上角的点(位置),(w, h)为 moban 模板矩形的宽和高。这个矩形就是找到的模板区域了。
注意: 如果你使用的比较方法是 cv2.TM_SQDIFF, 最小值对应的位置才是匹配的区域。
24.1 OpenCV 中的模板匹配
OpenCV 提供了几种不同的比较方法:
cv2.TM_CCOEFF, cv2.TM_CCOEFF_NORMED, cv2.TM_CCORR,
cv2.TM_CCORR_NORMED, cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED
24.2 多对象的模板匹配
25 Hough 直线变换
如何在一张图片中检测直线
霍夫变换在检测各种形状的的技术中非常流行,如果要检测的形状可以用数学表达式写出,就可以使用霍夫变换检测它。即使要检测的形状存在一点破坏或者扭曲也可以使用。
我们下面就看看如何使用霍夫变换检测直线。一条直线可以用数学表达式 y = mx + c 或者 ρ = x cos θ + y sin θ 表示。ρ 是从原点到直线的垂直距离, θ 是直线的垂线与横轴顺时针方向的夹角(如果使用的坐标系不同方向也可能不同)。
OpenCV 使用的坐标系如下图所示:
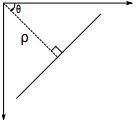
详见P.170
25.1 OpenCV 中的霍夫变换
cv2.HoughLines()
上面介绍的整个过程都封装在了:cv2.HoughLines()函数中。返回值就是(ρ, θ)。 ρ 的单位是像素, θ 的单位是弧度。
这个函数的第一个参数是一个二值化图像,所以在进行霍夫变换之前要首先进行二值化,或者进行Canny 边缘检测。第二和第三个值分别代表 ρ 和 θ 的精确度。第四个参数是阈值,只有累加其中的值高于阈值时才被认为是一条直线,也可以把它看成能检测到的直线的最短长度(以像素点为单位)。
25.2 Probabilistic Hough Transform概率霍夫变换
cv2.HoughLinesP()
从上边的过程我们可以发现:仅仅是一条直线都需要两个参数,这需要大量的计算。 Probabilistic_Hough_Transform 是对霍夫变换的一种优化。它不会对每一个点都进行计算,而是从一幅图像中随机选取一个点集进行计算,对于直线检测来说这已经足够了。
但是使用这种变换我们必须要降低阈值(总的点数都少了,阈值肯定也要小)
cv2.HoughLinesP()有两个参数:
• minLineLength - 线的最短长度。比这个短的线都会被忽略。
• MaxLineGap - 两条线段之间的最大间隔,如果小于此值,这两条直线就被看成是一条直线。
更加给力的是,这个函数的返回值就是直线的起点和终点。而在前面的例子中,我们只得到了直线的参数,而且你必须要找到所有的直线。
26 Hough 圆环变换
cv2.HoughCircles() 使用霍夫变换在图像中找圆形(环)
圆形的数学表达式为 (x − xcenter)2+(y − ycenter)2 = r2,其中(xcenter,ycenter)为圆心的坐标, r 为圆的直径。从这个等式中我们可以看出:一个圆环需要 3个参数来确定。所以进行圆环霍夫变换的累加器必须是 3 维的,这样的话效率就会很低。所以 OpenCV 用来一个比较巧妙的办法,霍夫梯度法,它可以使用边界的梯度信息。
27 分水岭算法图像分割
使用分水岭算法基于掩模的图像分割
函数: cv2.watershed()
原理
任何一副灰度图像都可以被看成拓扑平面,灰度值高的区域可以被看成是山峰,灰度值低的区域可以被看成是山谷。我们向每一个山谷中灌不同颜色的水。随着水的位的升高,不同山谷的水就会相遇汇合,为了防止不同山谷的水汇合,我们需要在水汇合的地方构建起堤坝。不停的灌水,不停的构建堤坝直到所有的山峰都被水淹没。我们构建好的堤坝就是对图像的分割。这就是分水岭算法的背后哲理。
但是这种方法通常都会得到过度分割的结果,这是由噪声或者图像中其他不规律的因素造成的。为了减少这种影响, OpenCV 采用了基于掩模的分水岭算法,在这种算法中我们要设置那些山谷点会汇合,那些不会。这是一种交互式的图像分割。我们要做的就是给我们已知的对象打上不同的标签。
如果某个区域肯定是前景或对象,就使用某个颜色(或灰度值)标签标记它。如果某个区域肯定不是对象而是背景就使用另外一个颜色标签标记。而剩下的不能确定是前景还是背景的区域就用 0 标记。这就是标签。然后实施**分水岭算法。**每一次灌水,我们的标签就会被更新,当两个不同颜色的标签相遇时就构建堤坝,直到将所有山峰淹没,最后我们得到的边界对象(堤坝)的值为 -1。
如将硬币和桌面分开:
1.首先使用 Otsu’s 二值化,硬币部分变为白色,其余部分变为黑色
2.形态学开运算 ——去除图像中的白噪声
形态学闭运算—— 去除对象上小的空洞
腐蚀操作 —— 去除边缘像素
膨胀操作 —— 将对象边界延伸到背景中
3.分水岭算法 —— 这些区域通常是前景与背景的交界处(或者两个前景的交界)。我们称之为边界。
从肯定不是背景的区域中减去肯定是前景的区域就得到了边界区域。
4.创建标签(一个与原图像大小相同,数据类型为 in32 的数组),并标记其中的区域。
对我们已经确定分类的区域(无论是前景还是背景)使用不同的正整数标记,对我们不确定的区域使用 0 标记。
我们可以使用函数 **cv2.connectedComponents()**来做这件事。它会把将背景标记为 0,其他的对象使用从1开始的正整数标记。
5.最后一步:实施分水岭算法了。标签图像将会被修改,边界区域的标记将变为 -1
详见P.179-182
28 使用 GrabCut 算法进行交互式前景提取
步骤:
• 用户输入一个矩形。矩形外的所有区域肯定都是背景。矩形框内的东西是未知。同样用户确定前景和背景的任何操作都不会被程序改变。
• 计算机对输入图像做一个初始化标记。它会标记前景和背景像素。
• 使用一个高斯混合模型(GMM)对前景和背景建模。
• 根据输入, GMM 会学习并创建新的像素分布。对那些分类未知的像素(可能是前景也可能是背景),可以根据它们与已知分类(如背景)的像素的关系来进行分类(就像是在做聚类操作)。
• 这样就会根据像素的分布创建一幅图。图中的节点就是像素点。除了像素点做节点之外还有两个节点: Source_node 和 Sink_node。
所有的前景像素都和 Source_node 相连。所有的背景像素都和 Sink_node 相连。
• 将像素连接到 Source_node/end_node 的(边)的权重由它们属于同一类(同是前景或同是背景)的概率来决定。两个像素之间的权重由边的信息或者两个像素的相似性来决定。如果两个像素的颜色有很大的不同,那么它们之间的边的权重就会很小。
• 使用 mincut 算法对上面得到的图进行分割。它会根据最低成本方程将图分为 Source_node 和 Sink_node。成本方程就是被剪掉的所有边的权重之和。在裁剪之后,所有连接到 Source_node 的像素被认为是前景,所有连接到 Sink_node 的像素被认为是背景。
• 继续这个过程直到分类收敛。

cv2.grabCut()
参数:
• img - 输入图像
• mask-掩模图像,用来确定那些区域是背景,前景,可能是前景/背景等。可以设置为:cv2.GC_BGD,cv2.GC_FGD,cv2.GC_PR_BGD,cv2.GC_PR_FGD,或者直接输入 0,1,2,3 也行。
• rect - 包含前景的矩形,格式为 (x,y,w,h)
• bdgModel, fgdModel - 算法内部使用的数组。只需要创建两个大小为 (1,65),数据类型为 np.float64 的数组。
• iterCount - 算法的迭代次数
• mode 可以设置为 cv2.GC_INIT_WITH_RECT 或 cv2.GC_INIT_WITH_MASK,也可以联合使用。这是用来确定我们进行修改的方式,矩形模式或者掩模模式。
部分 V
图像特征提取与描述
29 理解图像特征 P.188 - P.190
角点是一个好的图像特征(不仅仅是角点,有些情况斑点也是好的图像特征)
找到图像特征的技术被称为特征检测
计算机也要对特征周围的区域进行描述,这样它才能在其他图像中找到相同的特征。我们把这种描述称为特征描述。
(比如我们选择特征周围的一个区域,然后用我们自己的语言来描述它,比如“上边是蓝天,下边是建筑,在建筑上有很多玻璃等”,你就可以在其他图片中搜索相同的区域了。基本上看来,你是在描述特征)
30 Harris 角点检测
上一节我们已经知道了角点的一个特性:向任何方向移动变化都很大
Harris 角点检测:
他把这个(向任何方向移动变化都很大)的简单想法转换成了数学形式。将窗口向各个方向
移动(u, v)然后计算所有差异的总和。表达式如下:
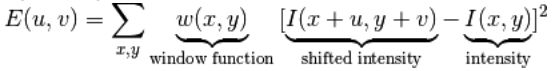
角点检测中要使 E (µ; ν) 的值最大。这就是说必须使方程右侧的第二项的取值最大。对上面的等式进行泰勒级数展开然后再通过几步数学换算,得到下面的等式:
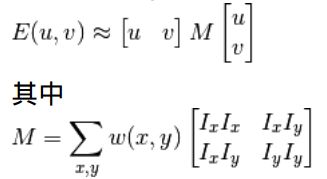
这里 Ix 和 Iy 是图像在 x 和 y 方向的导数。 (可以使用函数 cv2.Sobel()计算得到)
然后就是主要部分了。他们根据一个用来判定窗口内是否包含角点的等式进行打分。
R = det(M) - k(trace(M))2
= λ1λ2 - k(λ1 + λ2)2
det (M) = λ1λ2
trace (M) = λ1 + λ2
• λ1 和 λ2 是矩阵 M 的特征值
根据这些特征中可以判断一个区域是否是角点,边界或者是平面。
• 当 λ1 和 λ2 都小时, |R| 也小,这个区域就是一个平坦区域。
• 当 λ1≫ λ2 或者 λ1≪ λ2,时 R 小于 0,这个区域是边缘
• 当 λ1 和 λ2 都很大,并且 λ1~λ2 时(近似), R 也很大,(λ1 和 λ2 中的最小值都大于阈值)说明这个区域是角点。
可以用下图来表示我们的结论:
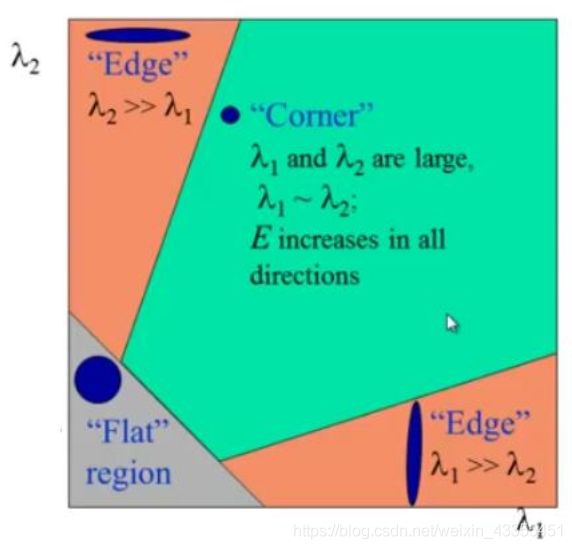
所以 Harris 角点检测的结果是一个由角点分数构成的灰度图像。选取适当的阈值对结果图像进行二值化就可以检测到图像中的角点。
30.1 OpenCV 中的 Harris 角点检测
cv2.cornerHarris() 用来进行角点检测。参数如下:
• img - 数据类型为 float32 的输入图像。
• blockSize - 角点检测中要考虑的领域大小。
• ksize - Sobel 求导中使用的窗口大小
• k - Harris 角点检测方程中的自由参数,取值参数为 [0,04, 0.06]
30.2 亚像素级精确度的角点
cv2.cornerSubPix()
它可以提供亚像素级别的角点检测。
例:首先找到 Harris角点,然后将角点的重心传给这个函数进行修正。 Harris 角点用红色像素标出,绿色像素是修正后的像素。在使用这个函数是我们要定义一个迭代停止条
件。当迭代次数达到或者精度条件满足后迭代就会停止。我们同样需要定义进行角点搜索的邻域大小。
31 Shi-Tomasi 角点检测 & 适合于跟踪的图像特征
另一个角点检测技术: Shi-Tomasi 焦点检测
cv2.goodFeatureToTrack()
Harris 角点检测的打分函数: R = λ1λ2 − k (λ1 + λ2)2
Shi-Tomasi 角点检测的打分函数: R = min (λ1, λ2)
P.197
即只有当 λ1 和 λ2 都大于最小值时,才被认为是角点(绿色区域)
32 介绍 SIFT (Scale-Invariant Feature Transform)
前面介绍的Harris 等角点检测技术它们具有旋转不变特性,即使图片发生了旋转,也能找到同样的角点。即使图像发生旋转之后角点还是角点。
那如果我们对图像进行缩放,角点可能就不再是角点。
因此在 2004 年, D.Lowe 提出了一个新的算法:尺度不变特征变换(SIFT),
这个算法可以提取图像中的关键点并计算它们的描述符
SIFT 算法主要由四步构成
•尺度空间极值检测
•关键点(极值点)定位
•为关键点(极值点)指定方向参数
•关键点描述符
•关键点匹配
看到了P.201