python 数据分析基础一:csv文件处理(1)
前言: csv文件格式是一种非常简单的数据储存与分享方式,csv文件可以将数据表格储存为纯文本,这适应了很多的程序。而且利用python处理csv几乎是完全自由的,因为你可以自己去开发一些处理的工具
对于csv文件我们可以使用普通的文本编辑器打开,如下:
我们以文本文档的格式打开可以看到:

而且我们可以通过修改文本文档的内容去修改整个csv文件。
那么我们首先要说的就是通过基础python处理这样的文件
首先,我们看最基本的以python,写入一个csv文件,代码:
#写入文本文件 write()写单个字符串,writelines可以将一系列字符串写入文本文件中
a_list=['1','2','3']
le=len(a_list)
inputname="the_first_csv.csv"
filename=open(inputname,"w+")
for index in range(le):
if index先创建一个非空列表,里面包含了我们要上传的数据,这里我们没有使用新型的打开文件的方式,我个人还是建议使用
with open(“filename”,“way”,newline="") 的方式去打开文件,这样比我们使用open与close的安全性更高
接着看代码,如果没有这个文件的话,系统会会在目录上创建这个名为 “the_first_csv.csv” 的文件,创建好之后,我们使用write函数将这些字符串写入文件中,我们执行完这段代码后打开这个csv文件,如下:
这样,一个简单的csv文件就诞生了,但这只是最基本的。
读写csv文件。
这里为了方便读写,我给大家提供一个简单的csv文件,也就是我上面截图的那个文件,大家可以从网址上面下载:
以上的csv文件地址传送门.
将文件下载之后,我们首先不使用csv模块与pandas模块,
接下来我们使用基础python,对该文件进行操作
上代码:
input_file="supplier_data.csv"
out_file="the_first_csv.csv"
with open(input_file,"r",newline="") as filereader:
with open(out_file,"w",newline="") as filewriter:
head=filereader.readline()
head=head.strip()
head_list=head.split(",")
filewriter.write(",".join(map(str,head_list))+'\n')
for row in filereader:
row=row.strip()
row_list=row.split(",")
print(row_list)
filewriter.write(','.join(map(str,row_list))+'\n')
前两行 :我们将两个csv文件名赋给两个变量
三四行 :新型读取文件的方法,还太懂的小伙伴可以去这里看看某博主的博客
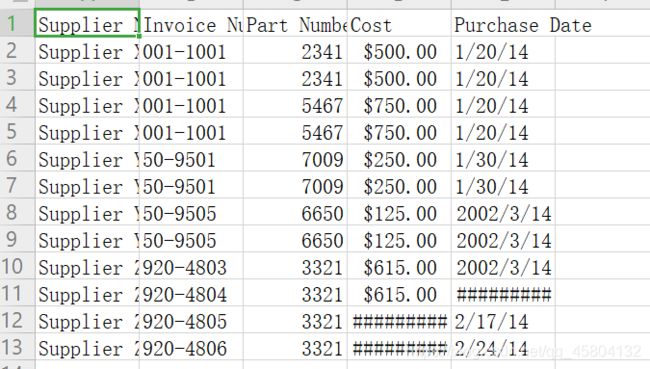
第五行到第八行 :这里是我要说明的部分,上面我们已经将csv模板文件读取为filereader,我们这里使用readline函数,注意不要误写为readlines函数两个函数并不相同。readline函数是对改文件读取一行,其实我们的目的就是将第一行读取出来,因为第一行实际上是表格的表头:如图:
![]()
这也是为什么我要命名为head的原因。
这几行的流程:
- 使用readline函数返回第一行的字符串。
- 用strip()函数去掉字符串头尾的空格,制表符。
- 用split()函数来将整个字符串分割为一个列表,我们注意到,以文本文档打开csv文件的模板,一系列字符串之间是通过","连接的,因此我们以逗号来分隔为列表
- 最后我们使用write函数写入第二个文件中,也就是我们的the_first_csv.csv
拓展:这里补充write函数,与join函数:
fileObject.write( [ str ]):文件目标.write(“字符串”)
join函数:join函数可以将列表或者迭代对象,以某种字符连接起来成为一个字符串,用法:(连接后的分隔符).join(要连接的元素序列)
- 最后几行,与上类似。我们使用for循环将,其余行的内容全部写入第二个csv文件,并使用print打印出来
代码执行的结果:
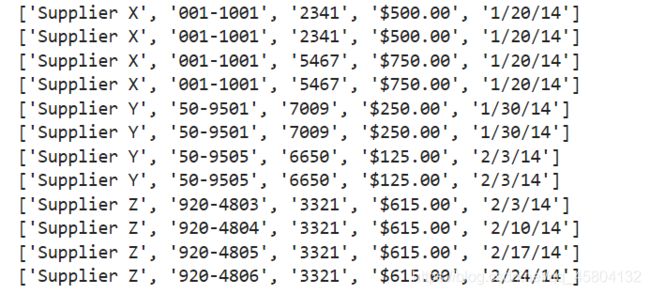
这是脚本执行后print语句所打印出来的。
拓展:使用pandas模块
那么我们知道python,在数据分析方面很多其他的高效的模块,使用这些模块可以加强我们处理数据的呢你,并且代码可能会很简洁,看起来会很高大上。
这里我们可以引用pandas模块,很多人都很陌生,没关系,我们从第一步慢慢走:我们尝试使用pandas模块去打印出这个csv文件
首先 我们需要引用这个模块:
import pandas as pd
那么为了方便 我们将其as为pd
我们知道python储存数据的方式有列表,元组,字典等等,pandas为什么处理csv方便呢,是因为它囊括了一种名为数据框的方式,这种储存方式包含了表格,因此我们便不再需要复杂的列表套列表去处理数据了
代码:
#利用pandas处理csv文件,pandas含有一种数据框的模式,这种模式保留了表格的形式,应该可以较为方便的处理
import pandas as pd
input_file="supplier_data.csv"
out_file="the_first_csv.csv"
date_frame=pd.read_csv(input_file)#frame:框架,架构
print(date_frame)
date_frame.to_csv(out_file,index=False)#index=False 表示输出不显示索引值
我们创建了一个名为:date_frame的变量,frame:名词:框架

这里我们使用了pandas.read_csv(),这个函数我不做详解,太多了,哈哈,我给大家一个连接们大家就不用去搜索了:对pandas.read_csv的详解传送门
这里我们只需要明白,这个函数可以返回,我们的csv模板的每一行的数据框,然后我们使用print函数将其打印出来,后面的 date_frame.to_csv(out_file,index=False) 其实是将这些数据框输入到我们自己创建的那个"the_first_csv.csv"中。这个函数,大家暂时可以记住这个用法,也不复杂,后的index=False的意思是,不显示索引,为什么会有索引,这些之后会给大家细说,这里简单解释,不多说,这个代码运行的结果是:
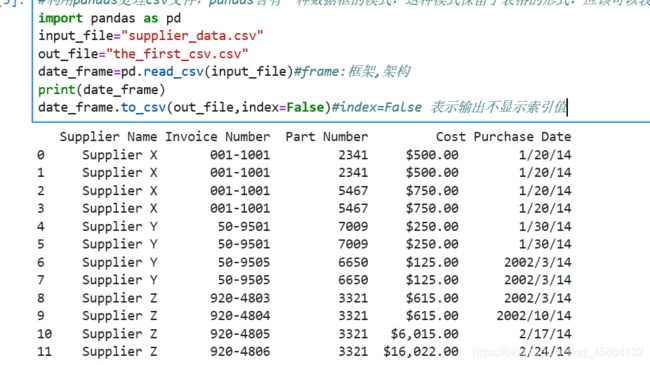
这是脚本运行的结果,如果这时候我们打开我们的the_first_csv.csv就会看到
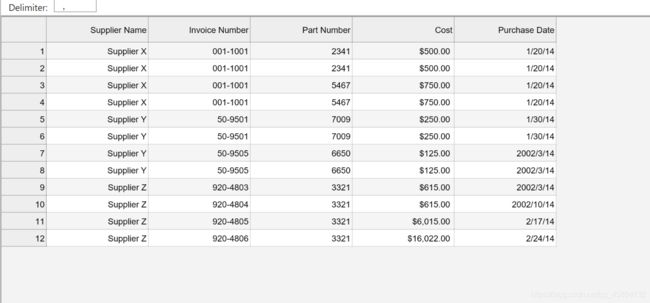
没错,实现了将我们的csv模板,完全搬运到了另一个新的csv文件的功能,
其实与之前那个代码的作用是一样的,但是看着是不是简洁了许多,而且print打印出来的也不再是一行行列表了。那么今天先讲到这吧
虽然博主很懒,但是csv这一章还是会持续更的,想学习的小伙伴,望关注哦