python字符串相关操作
前面学习过了字符串的基本知识,下面我们来聊聊字符串的一系列操作吧
字符串相关操作
python提供5个字符串基本操作符:
+ ————>x+y:用于连接两个字符串x和y
* ————>nx或xn:(n为整数)复制n次字符串x
in ————> x in s: 如果x是s的子串返回True,否则返回False
[]————>str[i]:索引,返回第i个字符
str[n:m] ————>切片操作,返回区间为n到m的子串,区间左闭右开即不包括第m个字符。
a="zmj"
b="好棒啊!"
print(a+b) #连接操作
print(a*2+b) #复制操作
print("字符串'{}'在字符串'{}'里面对吗?{}".format(a,b,(a in b))) #使用in判断包含关系
print(a[0]+b[0:-1]) #切片操作和索引操作结果为:

python字符串的切片操作更为通用的语法格式是:
[start: end: (step)]
特殊情况:
❶ [:] 用于切分出从开头(默认位置0)到结尾(默认位置-1)的整个字符串
❷[start:] 从start 切分到结尾
❸[:end] 从开头切分到end - 1
(由于第1个字符下标为0,因此第n个字符的下标实际应为n-1)
❹ [start: end: step] 从start 提取到end - 1,每step 个字符提取一下
内置的字符串处理函数
上一节向大家展示字符串时用到了len函数来获取字符串长度,还有其他几个字符串的处理函数今天还和大家聊一聊哈◟(`꒳´❀)
❶len(S)————>:返回字符串S的长度,也可返回其他组合类型的元素个数
❷str(x)————>:返回其他类型x所对应的字符串形式
❸chr(x)————>:返回Unicode编码x对应的单字符
❹ord(x)————>:返回单字符表示的Unicode编码
❺hex(x)————>:返回整数x对应十六进制数的小写形式字符串
❻oct(x)————>:返回整数x对应八进制数的小写形式字符串
由于python中的每个字符都采用Unicode编码表示,每一个字符都有它所对应的Unicode编码,chr函数和ord函数用于单字符与其Unicode编码转换。
hex函数和oct函数用于整数x所对应十六进制和八进制字符串形式的表示
给大家展示一下哈:
S='今天的例子不是zmj好棒了,而是你今天学废了吗'
pi=3.1415926
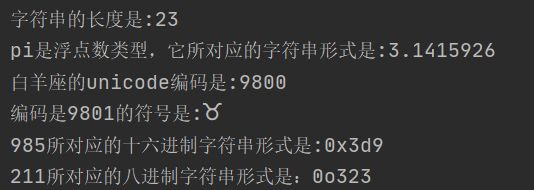
print("字符串的长度是:{}".format(len(S))) #len返回字符串长度
print("pi是浮点数类型,它所对应的字符串形式是:{}".format(str(pi))) #str返回浮点数对应字符串形式
print("白羊座的unicode编码是:{}".format(ord("♈")))#ord返回字符的Unicode编码
print("编码是9801的符号是:{}".format(chr(9801)))#chr函数返回Unicode编码对应的字符
print("985所对应的十六进制字符串形式是:{}".format(hex(985)))#hex返回整数的十六进制字符串形式
print("211所对应的八进制字符串形式是:{}".format(oct(211)))#oct返回整数的八进制字符串形式其结果是:
第二个字符串形式没有引号可能是显示的时候错了哈,小问题可以忽略( * ॑꒳ ॑* )
举例子的时候那个白羊座别问我为什么是白羊座,问就是想送我生日礼物么么(╯ε╰)
下面来看字符串的处理方法,对了,有同学问我字符串处理函数和内置处理方法有什么区别,有区别,名字不就不一样吗ʕ •ᴥ•ʔ。
内置处理函数是把字符串当作参数,使用函数处理字符串。一般都是某函数(字符串)的形式。
处理方法是先定义一个字符串,然后通过字符串调用处理方法进行处理,所以通常都是字符串.方法调用。
前者是函数调用的思想,把字符串当作参数传递给函数,后者是面向对象的思想,先有了字符串这一对象才可以通过对象使用方法。面向对象的思想我们以后讲解java的时候还会再提及˙Ꙫ˙
python提供了好多内置的字符串处理方法,我来说一下几个常用的吧:
①str.lower————>:返回字符串str的全部小写字符副本
②str.upper————>:返回字符串str的全部大写字符副本
③str.islower————>:当str中的所有字符都是小写时返回True,否则返回False
④str.isprintable————>:当str中的所有字符都可打印时返回True,否则返回False
⑤str.isnumeric————>:当str中的所有字符都是数字时返回True,否则返回False
⑥str.isspace————>:当str中的所有字符都是空格时返回True,否则返回False
⑦str.endswith(x[,start[,end]])————>:
str[start:end]以x结尾时返回True,否则返回False
⑧str.startswith(prefix[,start[,end]])————>:
str[start:end]以prefix结尾时返回True,否则返回False
⑨str.split(sep=None,maxsplit=-1)——————>:
返回一个列表,根据sep将str分隔开,默认情况下根据空格分隔开,maxsplit参数为最大分割次数,可以不给出
⑩str.count(sub[,start[,end]])————>:返回str[start,end]中子串sub出现的次数
⑪str.replace(old,new[,count])————>:所有old字符串被替换为new字符串,如果count参数给出,则前count次出现的old被替换为new,返回字符串str的副本
⑫str.center(width[,fillchar])————>:返回长度为width的新字符串,其中str处在新字符串的中心位置,两侧新增字符用fillchar控制,当width
⑭str.zfill(width)————>:返回字符串str的副本,长度为width,不足部分在在左侧添’0’,但是如果str最左侧是+或者-则从第二个字符左侧添加’0’
⑮str.format()————>:格式化处理str函数,我们将在下一节讲解,这个用的最多
这里已经更新完了哈✧*。٩(ˊᗜˋ*)و✧*。戳蓝字就可以进行学习了format方法讲解
⑯str.join(iterable)————>:将在以后讲解组合类型时说明.。
我把几个不好理解的方法展示一下吧,来我们上代码
str="是的,没错,今天的例子,依然是zmj好棒"
judge=str.endswith("是",0,13)
#这里我们切片的时候,区间是左闭右开,第12个字符为是,但是我们把边界选为12的话就只能取到第11个,要特别注意一下
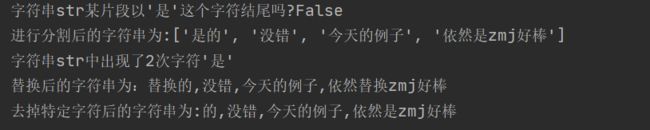
print("字符串str某片段以'是'这个字符结尾吗?{}".format(judge))
print("进行分割后的字符串为:{}".format(str.split(",")))
count=str.count("是")
print("字符串str中出现了{}次字符'是'".format(count))
print("替换后的字符串为:{}".format(str.replace("是","替换")))
print("去掉特定字符后的字符串为:{}".format(str.strip("是")))
下面我们来看结果:
其他几个函数如果想要小赵演示的话可以私信我鸭我会补上的ฅ•̀∀•́ฅ
那今天就到这吧,你又学废了吗,下次见咯(๑•̀ㅂ•́) ✧