【包】PF_RING
一.libpcap与libpcap-mmap
上周提及运用libpcap抓包在占用资源方面没有很大缺陷,但是丢包率很高,当网络数据流量较大(以10ms间隔发送广播包)时,丢包率高于90%,随着数据包量的增加和包长度的减小,丢包率呈上升趋势。
libpcap丢包严重的原因:
- cpu频繁中断(接收数据包时中断);
- 数据包被多次拷贝(从网卡拷贝到内核空间,从内核拷贝到用户空间)。
于是有人提出了libpcap-mmap,建立内核与用户空间的映射,数据包被直接传送到用户空间,从而减少拷贝次数。同时libpcap-mmap还对libpcap的缓冲器进行了改进,设计了一个可变大小的循环缓冲器代替原先固定大小的存储缓冲器和保持缓冲器,允许用户程序和内核程序对循环缓冲器中不同区域的数据进行访问和读写。
在libpcap-0.7.2(centos7自带libpcap-1.5.3,需要先卸载libpcap-1.5.3,再重新安装低版本,以及相应的tcpdump)和libpcap-1.5.3中对比运行自定义的libpcap.c以及tcpdump,发现抓包效率和cpu及内存占用率没有明显区别(libpcap-0.7.2环境下的tcpdump抓包率更高一些),这与文献“Improving passive packet capture: beyond device polling”的结果是接近的,因为即使是改进的libpcap-mmap也存在内存拷贝和频繁的上下文切换,报文捕获率并不乐观。
libpcap-0.7:



libpcap-1.5.3:


![]()
Tcpdump 通过网络接口捕获原始数据包,执行过滤条件需要耗费一些时间,因此传入数据包必须排队(数据缓存)进行处理,当数据包过多时(处理速度跟不上缓存速度),缓存区就会被撑爆(缓存区大小默认是2M),此时就会丢弃新近的数据包,直到缓存区有空间保存新到数据。于是尝试增大缓存区的大小:
tcpdump -B 4096 -i ens33
抓包率由94.1%->99.89%
二.pf_ring
PF_RING针对libpcap的改进方法:将网卡接收到的数据包存储在一个环状缓存中,这个环状缓存有两个接口,一个供网卡向其中写数据,另一个为应用层程序提供读取数据包的接口,从而减少了内存的拷贝次数,若将收到的数据包分发给多个环形缓冲区则可以实现多线程应用程序的读取。
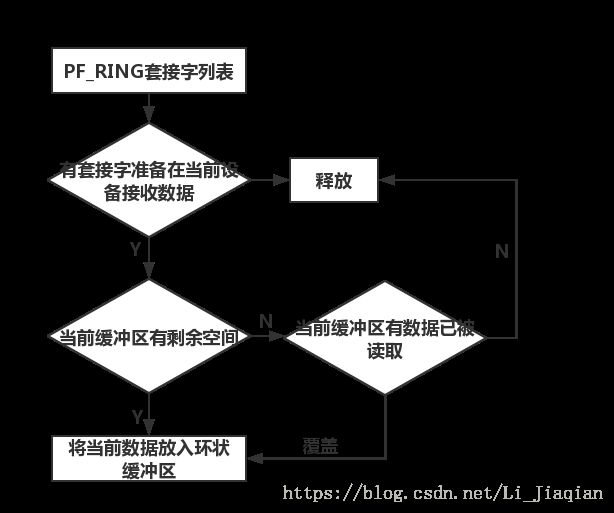
每创建一个PF_RING套接字便分配一个环形缓冲区,当套接字结束时释放缓冲区,不同套接字拥有不同缓冲区,将PF_RING套接字绑定到某网卡上,当数据包到达网卡时,将其放入环形缓冲区,若缓冲区已满,则丢弃该数据包。当有新的数据包到达时,直接覆盖掉已经被用户空间读取过的数据包空间。
网卡接收到新的数据包后,直接写入环形缓冲区,以便应用程序直接读,若应用程序需要向外发送数据包,也可以直接将数据包写入环形缓冲区,以便网卡驱动程序将该数据包发送到相应接口上。
PF_RING的工作流程:
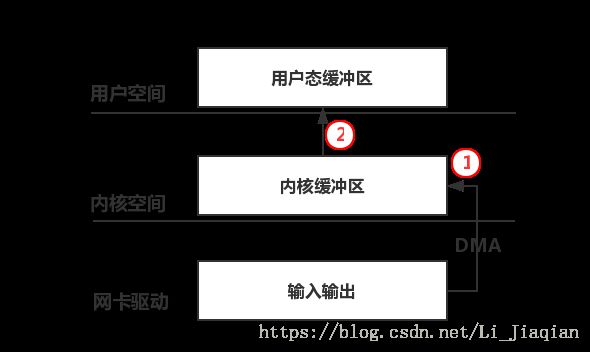
普通的网络接收函数中,网卡驱动到内核传递数据的核心是netif_rx()函数,若使用了设备轮询(NAPI)机制(中断机制+轮询机制,以中断方式通知系统,将设备注册到轮询队列后关闭中断,轮询队列中注册的网络设备从而读取数据包,采用NAPI机制可以减少中断触发的时间),则传递数据的核心是netif_receive_skb()函数。PF_RING定义了一个处理函数skb_ring_handler(),插入前两个核心函数的起始位置,每当有数据包需要传递时,先经过skb_ring_handler()的处理。
(1)一般的数据包捕获(libpcap):
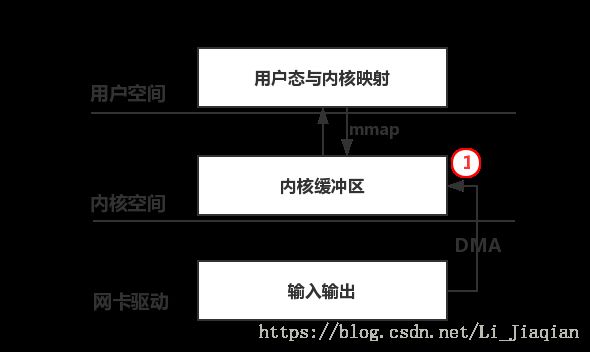
非零拷贝的pf_ring(pf_ring noZC):
零拷贝的pf_ring(pf_ring ZC):

PF_RING有三种工作模式:
- Transparent_mode=0:用户通过mmap获取已经拷贝到内核的数据包,相当于libpcap-mmap技术;
- Transparent_mode=1:将数据包放入环形缓冲区;
- Transparent_mode=2:数据包只由PF_RING模块处理,不经过内核,直接mmap到用户态。
后两种模式需要使用PF_RING特殊定制的网卡驱动:pf_ring.ko。
PF_RING的安装使用:
PF_RING/userland/examples中自带一些程序供使用:
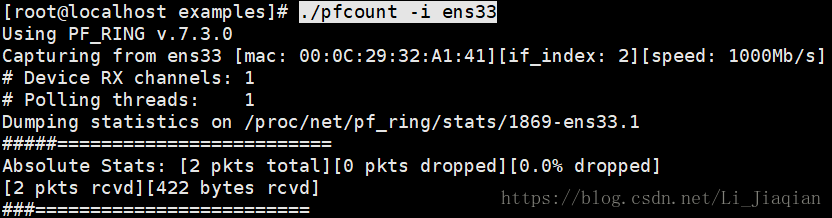
·统计流经ens33端口的数据包数量:
 ·显示端口设备信息:
·显示端口设备信息:
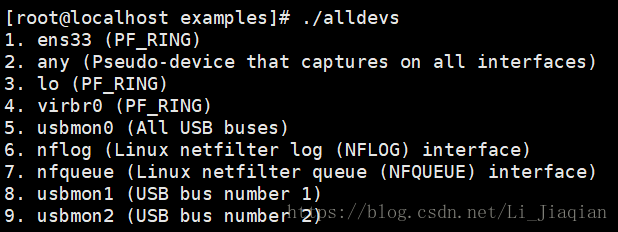
(可以看出ens33、lo、virbr0是经过PF_RING特殊配置后的端口)
·使用PF_RING前后的tcpdump抓包率对比:
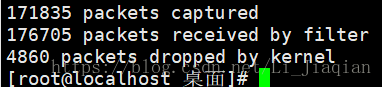
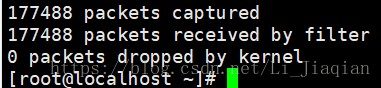
·可以看出基于pf_ring的tcpdump丢包率明显降低,但是占用cpu和内存较大:
Tcpdump(pf_ring):

Tcpdump:

安装过程中的问题:
编译内核:
make: *** /lib/modules/3.10.0-862.el7.x86_64/build: 没有那个文件或目录。 停止。
——》进入/usr/src/kernels/下看有没有相应的内核开发包,没有,就安装,若有跳过第一步
UNAME=$(uname -r)
yum install gcc kernel-devel-${UNAME%.*}
make
对于ko.xz:
——》[root@localhost net]# locate e1000e.ko
/usr/lib/modules/3.10.0-862.el7.x86_64/kernel/drivers/net/ethernet/intel/e1000e/e1000e.ko.xz
xzcat e1000.ko.xz>>e1000.ko
三.丢包率测试
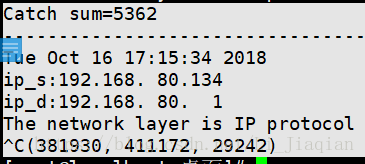
Libpcap:

Wireshark:

Scapy:

Tcpdump:
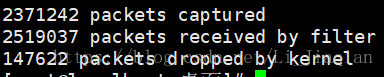
Tcpdump(pf_ring):

|
|
Libpcap(64byte) |
Libpcap(10000byte) |
wireshark |
scapy |
tcpdump |
tcpdump(pf__ring) |
| Catched |
309 |
5363 |
1216460 |
120660 |
2371242 |
2766151 |
| Sum |
1808638 |
29242 |
1228807 |
129390 |
2519037 |
2766151 |
| 抓包率(%) |
0.02 |
18.34 |
98.99 |
93.3 |
94.1 |
100 |
| Cpu占用(%) |
0.0 |
0.0 |
2.7 |
55.0 |
4.7 |
9.2 |
| 内存占用(%) |
0.2 |
0.3 |
4.8 |
65.9 |
0.8 |
26.6 |


若网络中数据包流量较大(如,以100ms为间隔发送广播包),抓包率明显降低,但是基于pf_ring的tcpdump抓包率仍为100%。
四.dpdk
dpdk使用UIO技术(UIO将驱动的很少一部分运行在内核空间,而在用户空间实现驱动的绝大多数功能,使用UIO可以避免设备的驱动程序需要随着内核的更新而更新的问题)将网卡收到的数据包直接拷贝到应用层处理,不再经过内核协议栈,从而减少了中断,dpdk的数据包全都在用户空间使用内存池管理,内核空间与用户空间的内存之间不用进行拷贝,只做控制权的转移,从而减少了数据包的拷贝次数,提高了报文的转发效率。