python学习之爬取ts流电影
爬取ts流电影文件
- 需求
- 程序结构目录
- 编写代码
- 基本思路
- 代码编写
- 优化
需求
**前言**
最近学习Python,语法规则、变量等也看完了,但是觉得啥也没记住,打开
py不知道写啥,只能print(“xxx”)(ps:此处手动尴尬)。听说py网络爬取
挺不错就想着,通过爬取网上的电影来增加兴趣吧,找了一些电影网站,
F12后发现很多网站上电影格式都是ts分流的ts这个东东也是刚知道的。ts
流数据简单理解就是把一个高清电影分割成成千上万个ts格式的小文件。这
些小文件的时长、顺序以及加密方式都放在一个xxx.m3u8文件中,所以只要
下载m3u8文件,然后构造并下载所有ts文件就可以将电影下载本地播放了。
**简单写下需求**:
输入电影网址,运行程序,即可自动下载电影所有的ts流文件,下载完成后,自动合并成MP4或其他视频格式的文件。
程序结构目录
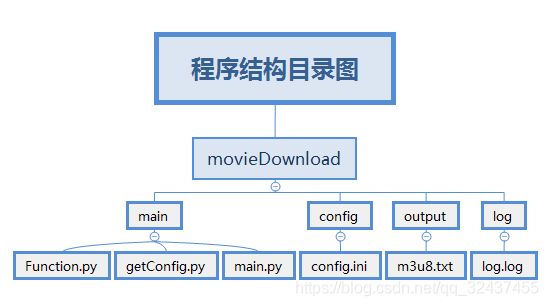
目录结构释义:
movieDownload:根目录
main:主程序目录
function.py:下载ts文件的方法模块
getConfig.py:获取配置文件方法
main.py:主程序
config:配置文件目录
config.ini:配置文件
output:ts流文件输出目录
m3u8.txt:待下载的网址文件
log:日志目录
log.log:日志文件
编写代码
基本思路
1.找到电影的index.m3u8文件url(这个文件中包含所有ts流文件名及顺序。后面需要通过该文件构造出所有的ts流文件下载,以及最后的合并顺序),把index.m3u8的url地址写入到m3u8.txt文件中。
2.下载u3m8文件
3.读取u3m8文件,把里面ts小文件名放入一个列表中待用。
4.循环从步骤3中的列表中读取单个ts链接,并下载到指定的目录。
5.合并所有ts小文件为ts(或MP4)格式。
6.美滋滋的观赏。
代码编写
使用的是PyCharm框架。
main.py代码:
# -*- coding:utf-8 -*-
"""
To be or not to bo ,That is a question !
"""
_author_ = 'wmx'
import os
import traceback
import movieDownload.main.getConfig as conf
from multiprocessing import Pool
import movieDownload.main.Function as fun
if __name__ == "__main__":
try:
fun.logging.debug("【需要下载的电影url文件目录】:" + conf.m3u8FilePath)
fun.logging.debug("【下载文件存储的根目录】:" + conf.filePath)
print("【需要下载的电影url文件目录】:" + conf.m3u8FilePath)
print("【下载文件存储的根目录】:" + conf.filePath)
m3u8FilePath = conf.m3u8FilePath #m3u8.txt文件的路径,从配置文件获取
filePath = conf.filePath #下载的文件存储根目录,从配置文件获取
urlList = fun.getM3u8List(m3u8FilePath) #获取m3u8.txt文件中的需要下载的url链接数量并放入列表。
fun.logging.debug("【需要下载的url数量】:"+str(len(urlList)))
print("【需要下载的url数量】:"+str(len(urlList)))
newDir = 0 #定义一个变量newDir,每个url下载的ts流文件放在单独的一个文件夹中,文件夹名从0开始。
for i in urlList: #循环取urlList的url
i=i.replace('\n','') #取出的url链接末尾会有一个换行符,去掉。
needDir = filePath+str(newDir) #构造新目录存放下载的ts文件,文件夹不存在的时候创建。
if not os.path.exists(needDir):
os.mkdir(needDir)
m3u8SavePath = needDir+"\\"+conf.postFix #构造存储m3u8文件数据的文件名,。
fun.logging.debug("【正在下载的是】:"+i+conf.postFix)
print("【正在下载的是】:"+i+conf.postFix)
tsList = fun.downladM3u8File(i+conf.postFix,m3u8SavePath) #下载并遍历并获取m3u8中的ts。
# 下载key文件,有的网站ts流文件是加密的,需要下载下来key.key文件便于最后文件的合并。
with open(conf.filePath + str(newDir) + "\\" +conf.postFix,'r') as m3u8Index:
key = m3u8Index.readlines()[4]
if key[-5:-2] =="key":
fun.logging.debug("【正在下载的是】:" + i + "key.key")
print("【正在下载的是】:" + i + "key.key")
fun.downloadTsFile(i+"key.key",conf.filePath + str(newDir) + "\\" + "key.key")
fun.logging.debug("【ts文件数量共】:"+str(len(tsList))+"\n【开始下载ts文件】")
print("【ts文件数量共】:"+str(len(tsList))+"\n【开始下载ts文件】")
newDir = newDir+1
#下载ts文件
tsIsOver = True
while tsIsOver:
pool = Pool(10) # 定义线程数量pool,利用多线程下载提高效率。
for j in tsList:
tsSavePath = needDir+"\\"+j #下载的ts文件存放路径。
if os.path.exists(tsSavePath):
pass
else:
pool.apply_async(fun.downloadTsFile,(i+j,tsSavePath))
pool.close()
pool.join()
#判断ts文件是否下载完毕,没下载完就继续下载。
lostList = []
for ts in tsList:
tsSavePath_bak = needDir + "\\" + ts
if not os.path.exists(tsSavePath_bak):
lostList.append(ts)
if len(lostList)>0:
tsIsOver = True
fun.logging.debug("ts文件没有下载完,继续下载!")
print("ts文件没有下载完,继续下载!")
else:
tsIsOver = False
fun.logging.debug("ts文件已经下载完!")
print("ts文件已经下载完!")
except Exception as ex:
fun.logging.error("【具体错误】:"+ex)
print("【具体错误】:"+ex)
fun.logging.error(traceback.print_exc())
print("【错误位置】:"+traceback.print_exc())
Function.py 代码:
# -*- coding:utf-8 -*-
import requests
import movieDownload.main.getConfig as conf
import logging
'''设置日志格式'''
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d]%(levelname)s:%(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
filename='../log/log.log',
filemode='w'
)
'''从指定的m3u8.txt中获取所有url(m3u8)链接'''
def getM3u8List(m3u8FilePath):
'''
:param m3u8FilePath: m3u8.txt文件的路径,即存放url的文件路径
:return: 返回一个m3u8链接的列表
'''
with open(m3u8FilePath,"r",encoding="utf-8") as f:
m3u8List = f.readlines()
return m3u8List
'''下载index.m3u8文件'''
def downladM3u8File(urlName,savePath):
'''
:param urlName: 需要下载的m3u8文url件链接 。
:param savePath: 保存路径。
:return: index.m3u8文件中ts链接的列表
'''
tsList = []
loop = 0
#把下载的文件内容存入指定文件夹
requesFileContent = requests.get(urlName,timeout=int(conf.timeOut)).content
try:
with open(savePath,"wb") as fo:
fo.write(requesFileContent)
logging.debug(urlName + " 下载成功!")
print(urlName + " 下载成功!")
# 如果下载失败,打印错误重新下载(重复5次)
except Exception as e:
print(e)
if loop<5:
downladM3u8File(urlName, savePath)
else:
logging.debug(urlName+"未下载成功!")
print(urlName+"未下载成功!")
loop+=1
#打开下载的index.m3u8文件,获取ts流链接地址
with open(savePath,"r",encoding="utf-8") as f:
u3m8FileList = f.readlines()
for i in u3m8FileList:
if i[0] != "#":
i = i[:-1]
tsList.append(i)
return tsList
'''下载ts文件'''
def downloadTsFile(urlName,savePath):
'''
:param urlName: 需下载的ts链接
:param savePath: 保存路径
:return:
'''
try:
requestsContent = requests.get(urlName,timeout=int(conf.timeOut)).content
with open(savePath,"wb") as f:
f.write(requestsContent)
print(urlName+" 下载成功!")
except Exception as e:
print(e)
#downloadTsFile(urlName, savePath)
#print(urlName + "下载失败!")
getConfig.py 代码:
# -*- coding: utf-8 -*-
import os
import configparser
#获取配置文件
configDir = os.path.dirname(os.path.dirname(__file__))
configFile = os.path.join(configDir,"config\config.ini")
#定义一个配置文件对象
configPar = configparser.ConfigParser()
configPar.read(configFile,encoding="utf-8")
#获取配置文件内容
m3u8FilePath = configPar.get("m3u8FilePath","m3u8FilePath")
filePath = configPar.get("filePath","filePath")
timeOut = configPar.get("timeOut","timeOut")
postFix = configPar.get("postFix","postFix")
config.ini
[m3u8FilePath]
;url文件地址
m3u8FilePath=E:\IDE\wmx-python\movieDownload\output\m3u8.txt
[filePath]
;下载存储根目录
filePath=E:\IDE\wmx-python\movieDownload\output\
[timeOut]
;超时时间
timeOut=10
[postFix]
;m3u8的url后缀
postFix=index.m3u8
m3u8.txt文件内容:每个url占一行不能有空行,url不用写后缀index.m3u8,因为在配置文件中已经写了(postFix=index.m3u8),有的网站后缀是xxx.m3u8,所以直接在配置文件中定义吧:
https://sohu.com-v-sohu.com/20181101/13971_6060c196/1000k/hls/
https://sohu.com-v-sohu.com/20181101/13971_6060c196/1000k/hls/
https://sohu.com-v-sohu.com/20181101/13971_6060c196/1000k/hls/
最后是所有ts流文件的合并:
重点来了!!!!
对于下载下的ts流文件合并没有用代码实现,手工实现的,开始以为一个copy /b *.ts new.ts 就OK了,但是这种合并后的文件有各种小毛病,例如:卡屏、视频跳跃性播放等。
所以这个时候需要安装一个 ffmpeg!安装完后创建一个xxx.bat脚本,脚本内容:
>>>
ffmpeg -allowed_extensions ALL -i index.m3u8 -c copy new.mp4
del *.ts
>>>
-i :指定indexm3u8文件位置,因为需要这个文件中ts文件的顺序。
-c copy: 新文件名字。
执行xxx.bat ->打开最终的new.mp4
接下来就是观赏电影了~~ 哇哈哈哈 ~~~
优化
最后更新日期:2020.04.29 今天周三,明天上一天就TM 五一了,愿疫情早些结束~
以上是近期反复调整后的代码,不过依旧存在冗余,bug等 ,慢慢改进吧… 不足的地方望大神指点~