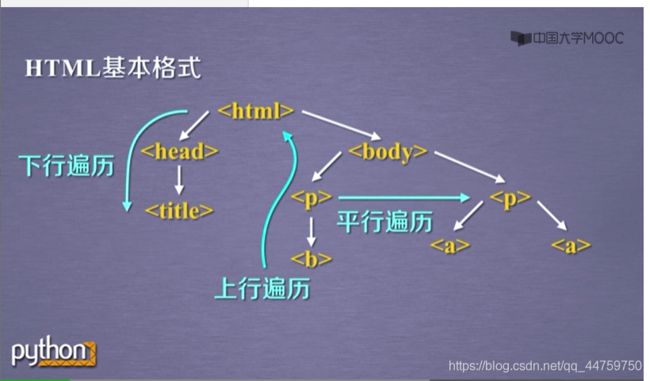
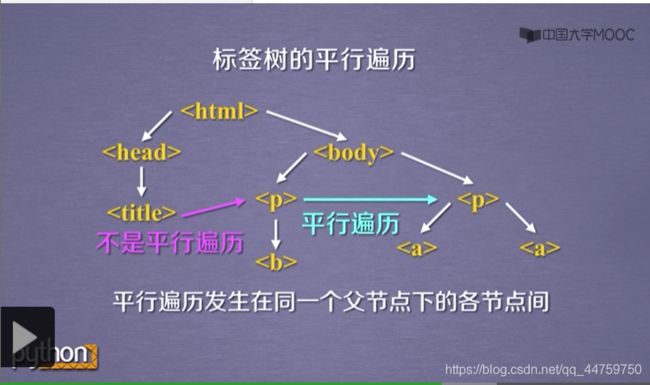
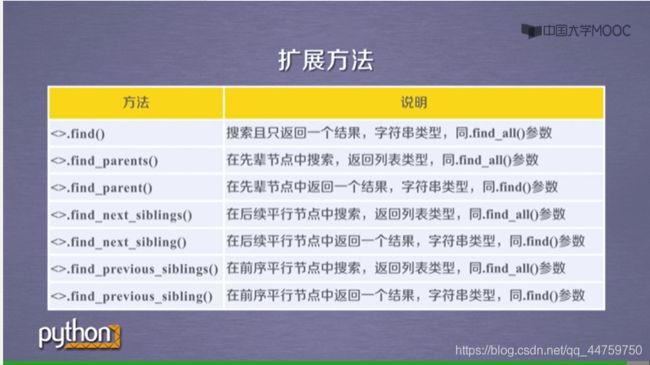
- 2018-11-09
94min呀
我以为蒙上了眼睛,就可以看不见这个世界;以为捂住了耳朵,就可以听不到所有的烦恼;以为脚步停了下来,心就可以不再远行;以为我需要的爱情,其实只是一个拥抱。。。。。。图片发自App即使这个社会很现实,我们也要过好当下的每一天~晚安~2018.11.9共修(晓敏)
- 豆包教你如何用Python向女生表白
51reboot
一年一度的考试大会又拉开了帷幕其中的一个重头戏就是python了不知道正处于手机前的你为python又掉了多少头发呢but!!!python绝不只是你脱发的工具善于使用你将收获多多比如你知道如何利用python向女生表白吗如果不知道少年,你可要当心啦考试很危险的呢后记:某年月日,某许愿池推文:震惊!某旦python考试题新鲜出炉,考题震惊十几亿中国人!原因竟是。。。待豆包点开推文:一看考试题,嘿哈
- nodejs中process讲解
虽然node对操作系统做了很多抽象的工作,但是你还是可以直接和他交互,比如和系统中已经存在的进程进行交互,创建工作子进程。node是一个用于事件循环的线程,但是你可以在这个事件循环之外创建其他的进程(线程)参与工作。进程模块process模块允许你获得或者修改当前node进程的设置,不想其他的模块,process是一个全局进程(node主进程),你可以直接通过process变量直接访问它。proc
- 为什么蜜雪冰城的主题曲这么洗脑?
我的天哪aoe
洗脑的原因:①歌词十分的短,容易记住且十分顺口②曲调十分有节奏,简直听一遍能记住一辈子⑤又土又潮,形象生动可爱相比于茶巷**,沪上**、CO**,蜜雪冰城真是做到了价格亲民和质量过关,而且面对多个奶茶品牌都在涨价这一现象,蜜雪冰城也直接给出:"我们还是不涨价!"的霸气回应,简直是亲民亲到家。看到蜜雪冰城的广告,我还想到了很久以前超火的脑白金广告:今年过节不收礼,收礼只收脑白金!顿时,大脑里就有面面
- 《谷歌时间管理课》:掌握这个法则,打造自己的高效能人生
日月照书时
文|深夏晚晴天ZMH“想做的事情不少,可就是没时间啊!”“我手头的工作都做不完,怎么有空做……”“等我有时间了,我就……”生活中,我们没少听到类似的抱怨。不管是他人还是自己,总是难免会有感觉时间不够用的时刻。按道理来说,近百年来科技与工具的迅猛发展,早已解放了我们的双手,我们应该多出很多时间过上一种悠闲的生活才对。但事实是,科技越发达,我们感觉越焦虑,依然还有一大堆“做不完”的事。为了应对这种情况
- C# 设计模式概况
业余撸码人
.net设计模式c#.net
什么是设计模式大家熟知的GOF23种设计模式,源自《DesignPatterns:ElementsofReusableObject-OrientedSoftware》一书,由ErichGamma、RichardHelm、RalphJohnson和JohnVlissides合著,四人组GangofFour简称GOF。总结了在面向对象语言开发过程中常见问题的解决方案。设计模式是面向对象语言开发过程中,
- 无人值守人工智能智慧系统数据分析:深度洞察与未来展望
呆码科技
人工智能数据分析数据挖掘
无人值守人工智能智慧系统数据分析:深度洞察与未来展望随着科技的飞速发展,人工智能(AI)技术已逐渐渗透到社会经济的各个领域,其中无人值守人工智能智慧系统作为AI技术应用的前沿阵地,正引领着一场深刻的行业变革。这类系统通过集成高级算法、大数据分析、物联网(IoT)及云计算等先进技术,实现了对复杂环境的自主监控、智能决策与高效管理,极大地提升了运营效率,降低了人力成本,并开启了数据驱动决策的新纪元。本
- 影子,我们一生的朋友。
紫柯的小绿洲
小时候玩的最多的游戏是互相追逐着踩对方的影子。在太阳底下,在路灯下面,我们一群小伙伴总是喜欢嬉闹着、追逐着踩对方的影子玩,但那时候只是纯粹的当做游戏来玩,并没有给影子赋予特别的含义。直到看了由法国著名作家马克.李维写的《偷影子的人》一书,才发现我们的影子还能有这么多的特殊的内容。大师就是大师,总是能从最平凡的细节中挖掘出最亮的闪光点。而真正的高手,也总是能在平淡的题材中见真章。毕竟大多数人都有的经
- 七彩人生公益“医护面对面”,关注医护心理健康,给世界一点爱!
七彩人生OCL
随着疫情的持续,我们已经习惯当前的生活,但我们之所以有正常的生活生产秩序,是因为有无数医护人员夜以继日的奋斗在抗疫第一线,用大无畏的精神守护我们的生命线。在抗击疫情这个过程中,我们除了向她们致以崇高敬意,能做得并不多,没办法给她们假期,也没办法给以财物,但在他们持续面对巨大的特殊心理压力时,需要我们给予特别的关注。01.聚焦医护心理健康对于一线医护人员来说,长期在高风险、高压力之下工作,因为目睹了
- 《微习惯》之后我做了什么
学晶
2017-12-17-星期日晴北京角落小的不能再小作者简介斯蒂芬·盖斯是个天生的懒虫。为了改变这一点,他开始研究各种习惯养成策略,从2004年起在美国各大自我成长类网站上发表了许多文章。2011年,他开始运营自己的博客DeepExistence,为读者提供自我成长策略方面的建议。他崇尚极简主义,喜欢打篮球和探索世界。[1]以前的以前受了很多书籍,很多文章的影响我也不断的制定年计划,月计划,周计划,
- 抖米多多怎么赚钱 抖米多多是什么平台
高省爱氧惠
抖米多多怎么赚钱抖米多多是什么平台购物、看电影、点外卖、用氧惠APP!更优惠!氧惠(全网优惠上氧惠)——是与以往完全不同的抖客+淘客app!2023全新模式,我的直推也会放到你下面,送1:1超级补贴(邀请好友自购多少,你就推广得多少,非常厉害),欢迎各位团队长体验!也期待你的加入。氧惠邀请码123456,注册就帮你推广,一起做到百万团队!抖米多多王炸实体项目来袭一周内首码发布,一千万团队粉丝滑落,
- 2018-03-25 学习之道6
SandyZhao
阅读:45min今日共计:90min关于工具和一些小技巧:这一章无新知识。里面说的都已经在用自己的方法实践和迭代了。周目标的设定挺要紧的
- c++ 反射与QMetaObject::invokeMethod介绍
文章目录c++QMetaObject::invokeMethodC++语言标准本身并不直接支持反射机制,这与Java、C#等语言不同,它们在语言层面提供了丰富的反射API。然而,C++是一种非常灵活的语言,可以通过一些设计和编程技巧来实现类似反射的功能。在C++中实现反射通常涉及以下几种技术:动态创建对象:反射可以在运行时创建任意一个已经定义的类的对象实例,即使你在编写代码时并不知道将要创建哪个类
- 2023-01-11今天下午评讲试卷6 刘绘老师启发讲解透
千里马会军
今天下午评讲试卷6,刘绘老师启发讲解透。参与学子劲头皆十足,积极互动人人精神抖!@所有人2023年1月11日数学课:[爱心][爱心][爱心]亲爱的同学们,大家好!数学课就马上要上开始了。主讲教师:刘绘请大家于1:55准时进入钉钉开始签到(5分钟之内完成签到)[微笑][微笑][微笑](上课时间2:00~3:00)[烟花][烟花][烟花]语音签到内容:1.等腰三角形三线合一2.有一个60°角的等腰三角
- 书记东来
谭家屋里
书记打浙江来,出差北京,恰逢假日,因此有机会相聚。书记乃研究生同学,因身兼党支部书记,因此大伙以书记相称,几乎没叫过他真名。他现在在浙江家乡的电网上班,入职不久,还是新人,恰逢电网要开大会,被抽调来做新媒体准备工作,也算是个不错的机会。当时求学,因为自己年纪大,玩得到一起的年轻人很少,书记则是少有的小伙伴,吃饭,或者周末游玩,两人常在一起。我几乎不发朋友圈,因此同学戏称:我活在书记的朋友圈里。可见
- 【江伦与伶桑】2/5 -我们牵手吧!
冷漠无情的宇佐木若子
终究到最后,我们还是没分手。但是,我们也没正式在一起。虽然,江伦口里一字一句的说‘是我的女人’、‘是我的女朋友’之类的话,即便我心里再开心,我们俩也没胜过现实。毕竟在风口浪尖上,我们也不好再被‘狗仔’抓个现行。后来的一个星期里,我们没有再见面。因为,我跟马月琴去了旅行。而江伦最近也进了新剧组拍片了。见不着面,还是可以通过微信语言聊天的。跟普通情侣一样,我们通过聊天,了解对方的情况。我自己个人觉得挺
- 倒计时:12天
香啡豆
图片发自App今早上完课又去了小菜场转转,因为下雨,卖菜的老人没几个。看到小龙虾,便买了一些回来。我没弄过龙虾,也不敢抓住活的龙虾。便请摊主帮我把龙虾头掐掉了。回来我自己抽了泥筋,把头里的虾黄挑出来。洋葱青椒爆炒再加入龙虾,虾黄。只放了盐和少许的糖。原汁原味、味道还不错。第一次烧龙虾,应该算成功的。丫头也蛮喜欢吃的。晚上丫头回来说数学考得不好,最近她的数学做的都不好,简单的都错。我让她不要紧张,她
- 锦衣之下番外40,陆绎陪夫人去看病,却意外碰到大人最不想见的人
859857d344be
夜晚,树林中静悄悄地,篝火上烤着陆绎打来的野鸡,一阵风吹来,香气四溢。今夏眼睛直勾勾地盯着冒油的野鸡,暗自吞咽口水。陆绎看在眼里,心中划过一丝甜蜜,无论如何,今夏母子总算是平安了。他紧悬着的一颗心,也大可暂时放下。岑福望着自家大人夫妇,心中甚觉自己多余,生平第一次,他也想成家了。岑福看得出大人担忧夫人,心底牵挂远在京城堂子里的小公子,但孑然一身的他,忽然很是羡慕有家人牵挂的感觉。话不多说,三人吃饱
- 2019-02-25
冰山轩儿
2019.2.25咖啡冥想财富目标:2019年3月30之前收入5万人民币。动机:智慧的路上自己成为榜样,我要种出孩子学习习惯棒棒的。帮助目前都在为孩子学习、习惯焦虑的父母们帮助,帮助孩子们不被父母打骂。夫妻关系我已经是榜样了,读书会的伙伴们都特别随喜我跟老公的感情,我的老公非常天使,我更希望我们可以共同学习智慧,学习种子法则。但是我希望能帮助正在经历困境的夫妻关系给予他们正确的引导。当我财富丰盛富
- 软件测试理论基础、质量保证常见面试题
程序员阿沐
全面掌握软件测试理论基础、文档编写,测试流程1.测试分为哪几个阶段?⒉谈谈你之前测试的项目流程,在每个阶段的输出有哪些?3.谈谈敏捷模式的认识?4.linux常见查看日志命令有哪些?5.线上质量BUG频频爆发怎么办?6.如何分析一个bug是前端还是后端的问题?这些问题你一定要能够很全面的表述出来。比如说我现在是面试官,我第一个肯定不会去问你哪些代码的问题,也不会问你自动化、测试开发的问题。第一个查
- Android7以上的手机通过fiddler抓包
春暖花开จุ๊บL
fiddler前端测试工具
设置以及安装步骤0,要求手机要先root1,安装fiddler,不赘述。不熟悉的可以安装中文版。fiddler中文版下载地址,并且把fiddler的证书文件导出到桌面上。2,安装windows版本的openssl。下载地址:OpenSSL下载地址记录好安装路径。3,到openssl的安装路径\bin目录下。shift+右键运行命令行。把fiddler的证书文件剪切到bin目录下。命令行执行open
- Node.js:process模块
process是Node.js中的一个全局对象,提供了与当前Node.js进程相关的信息和控制能力。它不需要通过require()引入即可使用。一、进程信息1.基础信息属性process.pid;//当前进程的PIDprocess.ppid;//父进程的PID(Node.jsv10+)process.title;//进程名称(可修改)process.arch;//CPU架构,如'x64','arm
- 突出全面从严治党,做好新时代基层党建工作
咕嘟咕嘟咕嘟
党的二十大报告深刻指出,全面建设社会主义现代化国家、全面推进中华民族伟大复兴,关键在党,必须弘扬伟大建党精神,坚定不移全面从严治党,以党的自我革命引领社会革命。党的基层组织是确保党的路线方针政策和决策部署贯彻落实的基础,一刻不停歇地推进全面从严治党,不断加强基层党建工作是落实党建工作科学发展的有效途径,也是保障各项事业高质量发展的坚实后盾。坚持从严治党,提升作风建设。作风问题究其根源还是信念信仰的
- 2023-01-29
话说癫痫
癫痫病怎么治疗呢?认为癫痫病患者很感兴趣的问题是治疗癫痫的方法。由于现代医学的研究和发现,癫痫病的面纱正在一点点地被揭开,曾经我们对癫痫的治疗无能为力,病人好坏完全取决于命运,但是很多病人由于没有很好的治疗方法而导致病情慢慢变得严重,甚至有些病人为了忍受癫痫病的折磨选择了轻生。目前针对癫痫我们不只有多种治疗方法,还有很多不同的治疗癫痫的药物,那么现在我们在临床上是如何治疗癫痫的呢?大量应用人群肯定
- “知识”、“学识”、“见识”华罗庚
穷人就要多旅行
人们认识事物有一个由感性认识到理性认识的过程,学习和从事科学研究,也有一个由“知’到“识”的过程。我们平常所说的“知识”、“学识”、“见识”这几个概念,其实都包含了两面的意思,反映了认识事物的两个阶段。“知识”是先知而后识,“学识”是先学而后识,“见识”是先见而后识。知了,学了,见了,这还不够,还要有个提高过程,即识的过程。因为我们要认识事物的本质,达到灵活运用,变为自己的东西,就必须知而识之,学
- 【FFmpeg】AVIOContext结构体
【FFmpeg】AVIOContext结构体1.AVIOContext结构体的定义参考:FFMPEG结构体分析:AVIOContext示例工程:【FFmpeg】调用ffmpeg库实现264软编【FFmpeg】调用ffmpeg库实现264软解【FFmpeg】调用ffmpeg库进行RTMP推流和拉流【FFmpeg】调用ffmpeg库进行SDL2解码后渲染流程分析:【FFmpeg】编码链路上主要函数的简
- 致良知线上正心班学习第93天
W_美娴
正心班功课模板致良知线上正心班学习第93天时间:2023年2月14日姓名:温美贤地区:山西朔州志愿:我立志要成为一名自省、利他、致良知的印证者,用言行去影响身边的人,日行一善,时时觉醒。为中华民族的复兴梦做出自己的努力!|当|下|即|未|来|【自省利他致良知】今日功课1、读原文✔:2分2、准时交功课✔:2分3、日行一善✔:2分4、每日自省✔:2分(1)时刻保持恩悲敬(2)不抱怨,不说谎5、读书践行
- 人际关系:想要混得好,表面一定要会装
土圭垚六土人生
[cp]人际关系:想要混得好,表面一定要会装即使在你心里,很排斥与人打交道,但要想在这个社会混得更好,与人接触是不可避免的。而在社会上,如果不遇人不淑,交了一个不好的朋友,不仅对自己的成长没有多大帮助,还有可能给自己带来很不好的坑。每个人的成长经历都不一样,所以不要想着去改变别人,这只是一种无用功。我们能做的只是掌握一些与人相处的技巧,更好的保护自己就行了。1、不要什么都说出来俗话说,对人只说三分
- 《活法》持续努力,变平凡为非凡
小玛丽妈咪
百日成长计划130组名:精进利他姓名:Mary日期:2021.1.18书名:《活法》作者:稻盛和夫持续努力,变平凡为非凡“遗传基因学第1人”,筑波大学名誉教授,村上和雄先生,针对所谓“火灾现场的爆发力”,这一现象,曾做过简单明了的解释。“在极限状态迸发出的人的巨大能量,为什么平时总是休眠呢?因为管理这部分功能的遗传基因,平常处于离线状态,只要把它的开关置于在线状态,那么即使在通常情况下,人们也可以
- 2021-05-25
偶然_9101
京心❤️达顺驰店:丁熊运2021年5月25日落地真经严格就是爱,放纵既是害油卡目标:10张、完成10张正能量语录每一颗螺丝都有标准每一颗螺丝都是标准今日体验:遇到问题要想办法去解决,跟据问题的不同想到不同的办法去快速的解决问题。从各个方面考虑全面这样在检查时就可以快速的解决问题。
- Enum 枚举
120153216
enum枚举
原文地址:http://www.cnblogs.com/Kavlez/p/4268601.html Enumeration
于Java 1.5增加的enum type...enum type是由一组固定的常量组成的类型,比如四个季节、扑克花色。在出现enum type之前,通常用一组int常量表示枚举类型。比如这样:
public static final int APPLE_FUJI = 0
- Java8简明教程
bijian1013
javajdk1.8
Java 8已于2014年3月18日正式发布了,新版本带来了诸多改进,包括Lambda表达式、Streams、日期时间API等等。本文就带你领略Java 8的全新特性。
一.允许在接口中有默认方法实现
Java 8 允许我们使用default关键字,为接口声明添
- Oracle表维护 快速备份删除数据
cuisuqiang
oracle索引快速备份删除
我知道oracle表分区,不过那是数据库设计阶段的事情,目前是远水解不了近渴。
当前的数据库表,要求保留一个月数据,且表存在大量录入更新,不存在程序删除。
为了解决频繁查询和更新的瓶颈,我在oracle内根据需要创建了索引。但是随着数据量的增加,一个半月数据就要超千万,此时就算有索引,对高并发的查询和更新来说,让然有所拖累。
为了解决这个问题,我一般一个月会进行一次数据库维护,主要工作就是备
- java多态内存分析
麦田的设计者
java内存分析多态原理接口和抽象类
“ 时针如果可以回头,熟悉那张脸,重温嬉戏这乐园,墙壁的松脱涂鸦已经褪色才明白存在的价值归于记忆。街角小店尚存在吗?这大时代会不会牵挂,过去现在花开怎么会等待。
但有种意外不管痛不痛都有伤害,光阴远远离开,那笑声徘徊与脑海。但这一秒可笑不再可爱,当天心
- Xshell实现Windows上传文件到Linux主机
被触发
windows
经常有这样的需求,我们在Windows下载的软件包,如何上传到远程Linux主机上?还有如何从Linux主机下载软件包到Windows下;之前我的做法现在看来好笨好繁琐,不过也达到了目的,笨人有本方法嘛;
我是怎么操作的:
1、打开一台本地Linux虚拟机,使用mount 挂载Windows的共享文件夹到Linux上,然后拷贝数据到Linux虚拟机里面;(经常第一步都不顺利,无法挂载Windo
- 类的加载ClassLoader
肆无忌惮_
ClassLoader
类加载器ClassLoader是用来将java的类加载到虚拟机中,类加载器负责读取class字节文件到内存中,并将它转为Class的对象(类对象),通过此实例的 newInstance()方法就可以创建出该类的一个对象。
其中重要的方法为findClass(String name)。
如何写一个自己的类加载器呢?
首先写一个便于测试的类Student
- html5写的玫瑰花
知了ing
html5
<html>
<head>
<title>I Love You!</title>
<meta charset="utf-8" />
</head>
<body>
<canvas id="c"></canvas>
- google的ConcurrentLinkedHashmap源代码解析
矮蛋蛋
LRU
原文地址:
http://janeky.iteye.com/blog/1534352
简述
ConcurrentLinkedHashMap 是google团队提供的一个容器。它有什么用呢?其实它本身是对
ConcurrentHashMap的封装,可以用来实现一个基于LRU策略的缓存。详细介绍可以参见
http://code.google.com/p/concurrentlinke
- webservice获取访问服务的ip地址
alleni123
webservice
1. 首先注入javax.xml.ws.WebServiceContext,
@Resource
private WebServiceContext context;
2. 在方法中获取交换请求的对象。
javax.xml.ws.handler.MessageContext mc=context.getMessageContext();
com.sun.net.http
- 菜鸟的java基础提升之道——————>是否值得拥有
百合不是茶
1,c++,java是面向对象编程的语言,将万事万物都看成是对象;java做一件事情关注的是人物,java是c++继承过来的,java没有直接更改地址的权限但是可以通过引用来传值操作地址,java也没有c++中繁琐的操作,java以其优越的可移植型,平台的安全型,高效性赢得了广泛的认同,全世界越来越多的人去学习java,我也是其中的一员
java组成:
- 通过修改Linux服务自动启动指定应用程序
bijian1013
linux
Linux中修改系统服务的命令是chkconfig (check config),命令的详细解释如下: chkconfig
功能说明:检查,设置系统的各种服务。
语 法:chkconfig [ -- add][ -- del][ -- list][系统服务] 或 chkconfig [ -- level <</SPAN>
- spring拦截器的一个简单实例
bijian1013
javaspring拦截器Interceptor
Purview接口
package aop;
public interface Purview {
void checkLogin();
}
Purview接口的实现类PurviesImpl.java
package aop;
public class PurviewImpl implements Purview {
public void check
- [Velocity二]自定义Velocity指令
bit1129
velocity
什么是Velocity指令
在Velocity中,#set,#if, #foreach, #elseif, #parse等,以#开头的称之为指令,Velocity内置的这些指令可以用来做赋值,条件判断,循环控制等脚本语言必备的逻辑控制等语句,Velocity的指令是可扩展的,即用户可以根据实际的需要自定义Velocity指令
自定义指令(Directive)的一般步骤
&nbs
- 【Hive十】Programming Hive学习笔记
bit1129
programming
第二章 Getting Started
1.Hive最大的局限性是什么?一是不支持行级别的增删改(insert, delete, update)二是查询性能非常差(基于Hadoop MapReduce),不适合延迟小的交互式任务三是不支持事务2. Hive MetaStore是干什么的?Hive persists table schemas and other system metadata.
- nginx有选择性进行限制
ronin47
nginx 动静 限制
http {
limit_conn_zone $binary_remote_addr zone=addr:10m;
limit_req_zone $binary_remote_addr zone=one:10m rate=5r/s;...
server {...
location ~.*\.(gif|png|css|js|icon)$ {
- java-4.-在二元树中找出和为某一值的所有路径 .
bylijinnan
java
/*
* 0.use a TwoWayLinkedList to store the path.when the node can't be path,you should/can delete it.
* 1.curSum==exceptedSum:if the lastNode is TreeNode,printPath();delete the node otherwise
- Netty学习笔记
bylijinnan
javanetty
本文是阅读以下两篇文章时:
http://seeallhearall.blogspot.com/2012/05/netty-tutorial-part-1-introduction-to.html
http://seeallhearall.blogspot.com/2012/06/netty-tutorial-part-15-on-channel.html
我的一些笔记
===
- js获取项目路径
cngolon
js
//js获取项目根路径,如: http://localhost:8083/uimcardprj
function getRootPath(){
//获取当前网址,如: http://localhost:8083/uimcardprj/share/meun.jsp
var curWwwPath=window.document.locati
- oracle 的性能优化
cuishikuan
oracleSQL Server
在网上搜索了一些Oracle性能优化的文章,为了更加深层次的巩固[边写边记],也为了可以随时查看,所以发表这篇文章。
1.ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前,那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾。(这点本人曾经做过实例验证过,的确如此哦!
- Shell变量和数组使用详解
daizj
linuxshell变量数组
Shell 变量
定义变量时,变量名不加美元符号($,PHP语言中变量需要),如:
your_name="w3cschool.cc"
注意,变量名和等号之间不能有空格,这可能和你熟悉的所有编程语言都不一样。同时,变量名的命名须遵循如下规则:
首个字符必须为字母(a-z,A-Z)。
中间不能有空格,可以使用下划线(_)。
不能使用标点符号。
不能使用ba
- 编程中的一些概念,KISS、DRY、MVC、OOP、REST
dcj3sjt126com
REST
KISS、DRY、MVC、OOP、REST (1)KISS是指Keep It Simple,Stupid(摘自wikipedia),指设计时要坚持简约原则,避免不必要的复杂化。 (2)DRY是指Don't Repeat Yourself(摘自wikipedia),特指在程序设计以及计算中避免重复代码,因为这样会降低灵活性、简洁性,并且可能导致代码之间的矛盾。 (3)OOP 即Object-Orie
- [Android]设置Activity为全屏显示的两种方法
dcj3sjt126com
Activity
1. 方法1:AndroidManifest.xml 里,Activity的 android:theme 指定为" @android:style/Theme.NoTitleBar.Fullscreen" 示例: <application
- solrcloud 部署方式比较
eksliang
solrCloud
solrcloud 的部署其实有两种方式可选,那么我们在实践开发中应该怎样选择呢? 第一种:当启动solr服务器时,内嵌的启动一个Zookeeper服务器,然后将这些内嵌的Zookeeper服务器组成一个集群。 第二种:将Zookeeper服务器独立的配置一个集群,然后将solr交给Zookeeper进行管理
谈谈第一种:每启动一个solr服务器就内嵌的启动一个Zoo
- Java synchronized关键字详解
gqdy365
synchronized
转载自:http://www.cnblogs.com/mengdd/archive/2013/02/16/2913806.html
多线程的同步机制对资源进行加锁,使得在同一个时间,只有一个线程可以进行操作,同步用以解决多个线程同时访问时可能出现的问题。
同步机制可以使用synchronized关键字实现。
当synchronized关键字修饰一个方法的时候,该方法叫做同步方法。
当s
- js实现登录时记住用户名
hw1287789687
记住我记住密码cookie记住用户名记住账号
在页面中如何获取cookie值呢?
如果是JSP的话,可以通过servlet的对象request 获取cookie,可以
参考:http://hw1287789687.iteye.com/blog/2050040
如果要求登录页面是html呢?html页面中如何获取cookie呢?
直接上代码了
页面:loginInput.html
代码:
<!DOCTYPE html PUB
- 开发者必备的 Chrome 扩展
justjavac
chrome
Firebug:不用多介绍了吧https://chrome.google.com/webstore/detail/bmagokdooijbeehmkpknfglimnifench
ChromeSnifferPlus:Chrome 探测器,可以探测正在使用的开源软件或者 js 类库https://chrome.google.com/webstore/detail/chrome-sniffer-pl
- 算法机试题
李亚飞
java算法机试题
在面试机试时,遇到一个算法题,当时没能写出来,最后是同学帮忙解决的。
这道题大致意思是:输入一个数,比如4,。这时会输出:
&n
- 正确配置Linux系统ulimit值
字符串
ulimit
在Linux下面部 署应用的时候,有时候会遇上Socket/File: Can’t open so many files的问题;这个值也会影响服务器的最大并发数,其实Linux是有文件句柄限制的,而且Linux默认不是很高,一般都是1024,生产服务器用 其实很容易就达到这个数量。下面说的是,如何通过正解配置来改正这个系统默认值。因为这个问题是我配置Nginx+php5时遇到了,所以我将这篇归纳进
- hibernate调用返回游标的存储过程
Supanccy2013
javaDAOoracleHibernatejdbc
注:原创作品,转载请注明出处。
上篇博文介绍的是hibernate调用返回单值的存储过程,本片博文说的是hibernate调用返回游标的存储过程。
此此扁博文的存储过程的功能相当于是jdbc调用select 的作用。
1,创建oracle中的包,并在该包中创建的游标类型。
---创建oracle的程
- Spring 4.2新特性-更简单的Application Event
wiselyman
application
1.1 Application Event
Spring 4.1的写法请参考10点睛Spring4.1-Application Event
请对比10点睛Spring4.1-Application Event
使用一个@EventListener取代了实现ApplicationListener接口,使耦合度降低;
1.2 示例
包依赖
<p