数据增强是提升图像识别模型性能的重要手段。伯克利 AI 研究院的一篇关于数据增强的论文便被 ICML 2019 收录为 oral 论文,该论文巧妙地运用基于种群的数据增强算法,在降低计算成本的情况下,既能提高学习数据增强策略的速度,又能提升模型的整体性能。伯克利 AI 研究院也在官方博客上对论文进行了解读, AI 科技评论编译如下。

在本文中,我们将介绍基于种群的增强算法(Population Based Augmentation,PBA),它能够快速、高效地学习到一个目前最先进的应用于神经网络训练的数据增强方法。PBA 能够在将速度提升 1000 倍的情况下,达到与之前在 CIFAR 和 SVHN 数据集上最佳的效果,这使得研究者和从业人员可以使用单个工作站的 GPU 有效地学习新的增强策略。研究者可以广泛地使用 PBA 算法来提升深度学习在图像识别任务上的性能。
同时,我们将讨论我们最新发表的论文「Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules」(论文下载地址:https://arxiv.org/abs/1905.05393.pdf)中 PBA 算法的实验结果,然后说明如何利用「Tune」(https://ray.readthedocs.io/en/latest/tune.html)框架在新数据集上运行 PBA 算法(https://github.com/arcelien/pba)。
你为什么需要关注数据增强技术?
近年来,深度学习模型的进步很大程度上归功于收集到的数据,在数量和多样性上的增加。数据增强是一种使从业人员在无需实际收集新数据的情况下,能够显着提升可用于训练模型的数据的多样性的策略。诸如裁剪,填充和水平翻转等数据增强技术通常被用于训练大型神经网络。然而,用于训练神经网络的的大多数方法仅仅使用了基本类型的数据增强技术。尽管研究者们已经深入研究了神经网络架构,但着眼于开发强大的数据增强和能够捕获数据不变性的数据增强策略的工作就相对较少了。

最近,谷歌已经能够通过使用 AutoAugment(一种新型的自动数据增强技术,https://arxiv.org/abs/1805.09501)在诸如 CIFAR-10 之类的数据集上达到目前最高的准确率。AutoAugment 说明了:之前只使用一系列固定变换(如水平翻转、填充和裁剪)的数据增强方法还有很大的提升空间。AutoAugment引入了 16 种几何变换和基于颜色的变换,并制定了一种可以最多选择两个指定幅度的变换的数据增强策略,从而应用于每批数据。这些具有更高性能的数据增强策略是通过直接在数据上使用强化学习训练模型学习到的。
有什么进步?
AutoAugment 是一种计算成本非常大的算法,从开始训练到收敛需要训练 15,000 个模型以为基于强化学习的策略生成足够的样本。同时,样本之间不共享计算过程,学习 ImageNet 的增强策略需要在NVIDIA Tesla P100 上训练 15,000 个 GPU 小时,而学习 CIFAR-10 则需要耗费 5,000 个 GPU 小时。例如,如果使用谷歌云上按需随选的 P100 GPU,探索 CIFAR 数据集上的数据增强策略将花费大约 7,500 美元,而探索 ImageNet 数据集上的数据增强策略则需要高达 37,500 美元!因此,在对新数据集进行训练时,更常见的用例是迁移作者证明效果相对较好的预先存在的已开发出来的策略。
基于种群的数据增强策略(PBA)
我们的数据增强策略搜索方法被称为「基于种群的增强」(PBA),它在各种神经网络模型上在将计算成本降低三个数量级的情况下,达到了相似的测试准确度水平。我们通过在 CIFAR-10 数据上训练几个小型模型副本来学习数据增强策略,在学习过程中需要使用 NVIDIA Titan XP GPU 训练 5 个小时。当在大型模型架构和 CIFAR-100 数据上从头开始进行训练时,此策略展现出了强大的性能。
相对于训练大型 CIFAR-10 网络时动辄花费好几天才能收敛的计算成本而言,事先运行 PBA 的计算成本就微不足道了,并且在实验结果上能够取得显著的提升。例如,在 CIFAR-10 上训练一个 PyramidNet 需要在一块 NVIDIA V100 GPU 上花费超过 7 天的时间,因此学习 PBA 策略仅仅增加了 2% 的预计算训练时间成本。对于 SVHN 数据及而言,这种成本甚至更低,低于 1%。
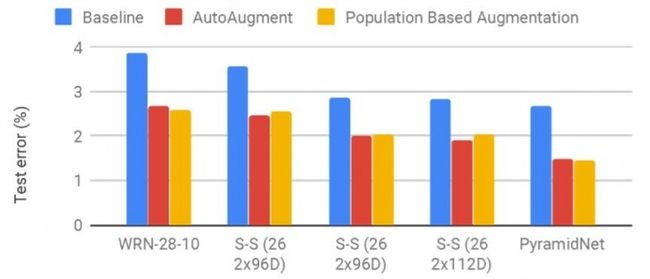
在 WideResNet(https://arxiv.org/abs/1605.07146),Shake-Shake(https://arxiv.org/abs/1705.07485),以及 PyramidNet(https://arxiv.org/abs/1610.02915)+ShakeDrop(https://arxiv.org/abs/1802.02375)模型上运用 PBA、AutoAugment 以及仅仅使用水平翻转、填充和裁剪等操作的对比基线时,各自在 CIFAR-10 测试集上产生的误差。
PBA 利用基于种群的训练算法(若想了解更多关于该算法的信息,可前往https://deepmind.com/blog/population-based-training-neural-networks/ 阅读相关内容)来生成一个增强策略计划,它可以根据当前训练的迭代情况进行自适应的调整。这与没有考虑当前训练迭代情况而应用相同的变换方式的固定增强策略,形成了鲜明对比。
这就使得一个普通的工作站用户可以很容易地使用搜索算法和数据增强操作进行实验。一个有趣的用例是引入一个新的数据增强操作,它可能针对的是特定的数据集或图像模态,可以迅速生成一个定制化的、高性能的数据增强计划。通过模型简化实验,我们发现学到的超参数和计划顺序对于得到好的实验结果非常重要。
如何学习到数据增强计划?
我们使用了基于种群的训练,该种群由 16 个小型 WideResNet 模型构成。种群中的每个个体会学习到不同的候选超参数计划。我们将性能最佳的计划进行迁移,从而从头开始训练更大的模型,而我们将从中得到测试误差指标。
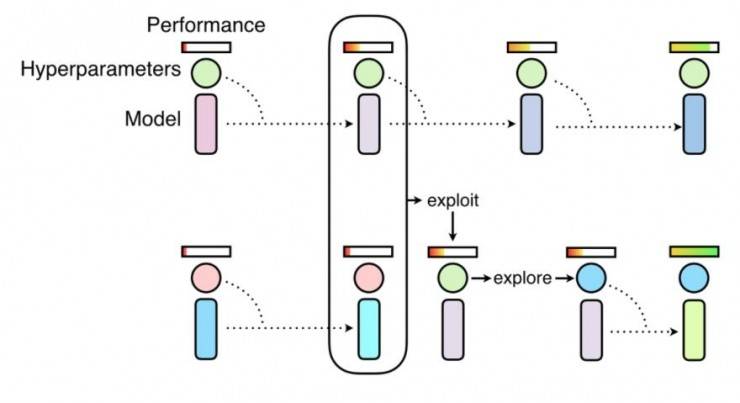
基于种群的训练示意图,它通过训练一个神经网路的种群来探索超参数计划。它将随机搜索(探索)和拷贝高性能个体的模型权重(利用)结合起来(https://deepmind.com/blog/population-based-training-neural-networks/)。
我们在感兴趣的数据集上训练种群模型,一开始将所有的增强超参数设置为「0」(不应用任何数据增强技术)。通常而言,一个「探索-利用」过程会通过将高性能个体的模型权重拷贝给性能较低的个体来「利用」高性能个体,并且会通过扰动个体的超参数来进行「探索」。通过这个过程,我们可以让个体之间大量共享超参数,并且在训练的不同区域针对于不同的增强超参数。因此,PBA 可以节省训练上千个模型才能达到收敛以实现高性能的计算成本。
示例和代码
我们使用了「TUNE」内置的 PBT 的实现来直接使用 PBA 算法。
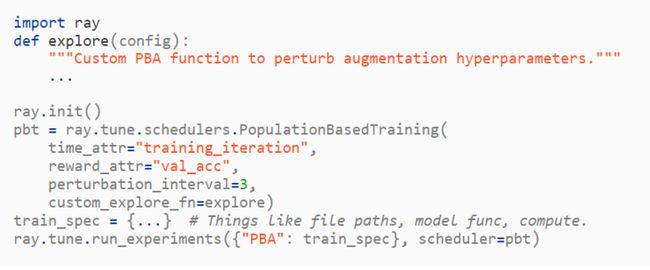
我们使用自定义的探索函数来调用「Tune」对 PBT 的实现,而这将会创建出 16 份 WideResNet 模型的副本,并且在时分多工模式下训练它们。每个模型副本使用的策略计划将会被保存到磁盘中,并且可以再程序终止后被检索,用于训练新模型。
感兴趣的人可以按照 Github 中「README」文件的指示运行 PBA 算法,地址如下:
https://github.com/arcelien/pba
在一块 Titan XP 显卡上,你只需一个小时就可以学到一个作用于 SVHN 数据集的高性能数据增强策略计划。你也可以很轻易地在自定义的数据集上使用 PBA 算法:只需简单定义一个数据加载器(dataloader),其它的部分就会自动就绪。
参考文献
ICML 2019 oral 论文:Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules
论文作者:Daniel Ho, Eric Liang, Ion Stoica, Pieter Abbeel, Xi Chen
论文链接:https://arxiv.org/abs/1905.05393
代码链接:https://github.com/arcelien/pba
Via https://bair.berkeley.edu/blog/2019/06/07/data_aug/
今日资源推荐:AI入门、大数据、机器学习免费教程
35本世界顶级原本教程限时开放,这类书单由知名数据科学网站 KDnuggets 的副主编,同时也是资深的数据科学家、深度学习技术爱好者的Matthew Mayo推荐,他在机器学习和数据科学领域具有丰富的科研和从业经验。
点击链接即可获取:https://ai.yanxishe.com/page/resourceDetail/417